









































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)











































































































































































































































































_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



















































































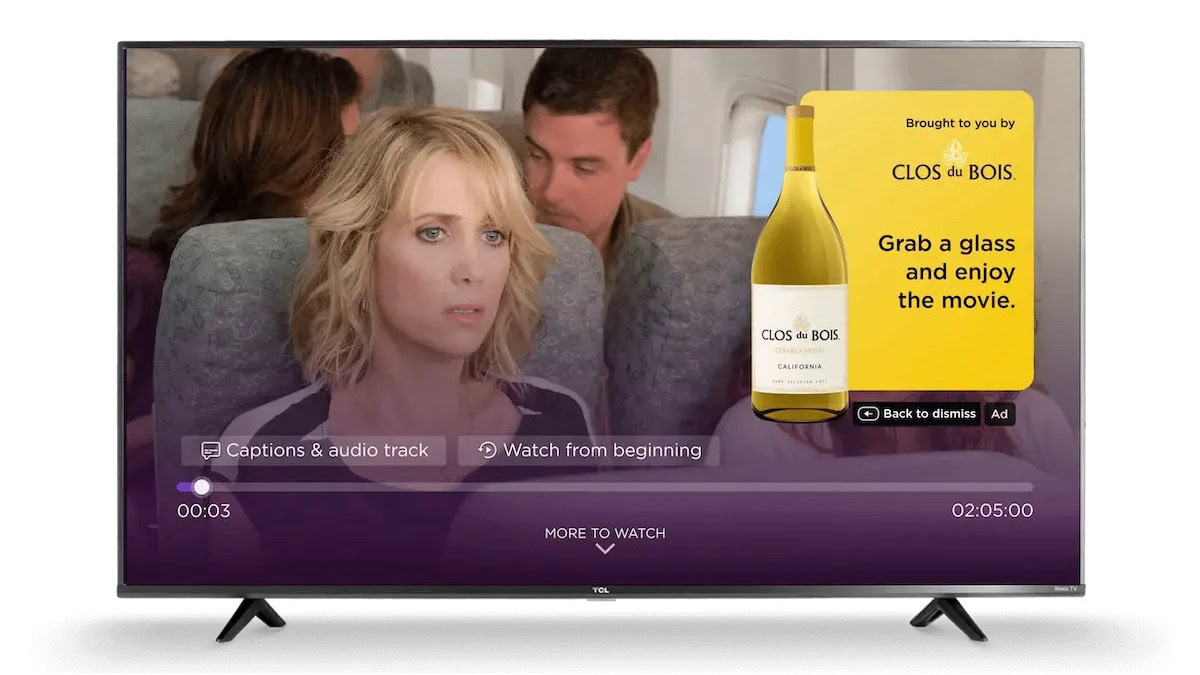




![Turn any iPad into a gaming display with this one simple trick [Video]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/05/iPad-as-console-FI.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)















![Apple Shares Official Teaser for 'Highest 2 Lowest' Starring Denzel Washington [Video]](https://www.iclarified.com/images/news/97221/97221/97221-640.jpg)

![Under-Display Face ID Coming to iPhone 18 Pro and Pro Max [Rumor]](https://www.iclarified.com/images/news/97215/97215/97215-640.jpg)
![New Powerbeats Pro 2 Wireless Earbuds On Sale for $199.95 [Lowest Price Ever]](https://www.iclarified.com/images/news/97217/97217/97217-640.jpg)
































































































Recurrent Neural Networks (RNNs): A Comprehensive Guide
Introduction Recurrent Neural Networks (RNNs) are a fascinating class of neural networks designed to handle sequential data, a type of data where the order matters. Unlike traditional neural networks, which treat each input independently, RNNs possess a unique “memory” that allows them to consider past inputs when processing current ones. This makes them exceptionally well-suited for tasks where context and sequence are crucial, such as understanding sentences, predicting stock prices, or even generating music. In essence, RNNs transform sequential data, like words, sentences, or time-series data, into a specific sequential data output, considering the complex relationships between the data points. The concept of sequence modeling is fundamental to understanding RNNs. Many real-world problems involve sequences, where the order of elements carries significant meaning. For example, in language, the meaning of a sentence depends heavily on the order of the words. Similarly, in video analysis, the sequence of frames determines the action being performed. RNNs excel at capturing these dependencies, making them a powerful tool for a wide range of applications. The application of RNNs is prevalent in the field of deep learning. The history of RNNs is marked by continuous evolution. Early RNN architectures faced challenges like the vanishing gradient problem, which hindered their ability to learn long-range dependencies. However, innovations like Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks have largely overcome these limitations, paving the way for the widespread adoption of RNNs in various fields. Understanding the RNN Architecture At the heart of an RNN lies the RNN cell, the fundamental building block responsible for processing sequential data. This cell receives an input and a hidden state from the previous time step. The hidden state acts as the “memory” of the network, carrying information about past inputs. The RNN cell combines the current input and the previous hidden state to produce a new hidden state and an output. This process is repeated for each element in the sequence, allowing the network to maintain context and learn dependencies. The hidden state plays a pivotal role in capturing sequential information. It’s a vector that represents the network’s understanding of the sequence up to a given point. As the RNN processes the sequence, the hidden state is continuously updated, incorporating new information and refining its representation of the context. This dynamic updating of the hidden state is what enables RNNs to “remember” and learn from past inputs. Diagrams and examples are incredibly helpful in visualizing the RNN architecture. Imagine an RNN processing a sentence word by word. At each time step, the RNN cell receives a word and the previous hidden state. It then updates the hidden state based on the current word and its relationship to the preceding words. The output of the RNN cell could be used for various tasks, such as predicting the next word in the sentence or classifying the sentiment of the sentence. The Power of Memory: Long Short-Term Memory (LSTM) Networks While basic RNNs are powerful, they struggle with a problem known as the vanishing gradient problem. This issue arises when training RNNs on long sequences, making it difficult for the network to learn long-range dependencies. The gradients, which are used to update the network’s weights, become increasingly small as they are backpropagated through time, effectively “vanishing” and preventing the network from learning from distant past inputs. Long Short-Term Memory (LSTM) networks were developed to address the vanishing gradient problem. LSTMs have a more complex cell structure than basic RNNs, incorporating “gates” that regulate the flow of information. These gates allow LSTMs to selectively remember or forget information, enabling them to capture long-range dependencies more effectively. An LSTM cell consists of several key components: the cell state, which acts as a long-term memory, and three gates: the input gate, the output gate, and the forget gate. The forget gate determines what information to discard from the cell state. The input gate decides what new information to store in the cell state. The output gate controls what information from the cell state to output. These gates, each implemented using sigmoid functions, carefully manage the flow of information, allowing LSTMs to learn and retain relevant information across long sequences. The LSTM’s ability to maintain a “long short-term memory” makes it significantly more effective than traditional RNNs for tasks like language Applications of RNNs RNNs have found widespread applications across various domains, demonstrating their versatility and power in handling sequential data. A core application of RNNs is in the field of deep learning. RNNs have revolutionized Natural Language Processing (NLP), enabling breakthroughs in

Introduction
Recurrent Neural Networks (RNNs) are a fascinating class of neural networks designed to handle sequential data, a type of data where the order matters. Unlike traditional neural networks, which treat each input independently, RNNs possess a unique “memory” that allows them to consider past inputs when processing current ones. This makes them exceptionally well-suited for tasks where context and sequence are crucial, such as understanding sentences, predicting stock prices, or even generating music. In essence, RNNs transform sequential data, like words, sentences, or time-series data, into a specific sequential data output, considering the complex relationships between the data points.
The concept of sequence modeling is fundamental to understanding RNNs. Many real-world problems involve sequences, where the order of elements carries significant meaning. For example, in language, the meaning of a sentence depends heavily on the order of the words. Similarly, in video analysis, the sequence of frames determines the action being performed. RNNs excel at capturing these dependencies, making them a powerful tool for a wide range of applications. The application of RNNs is prevalent in the field of deep learning.
The history of RNNs is marked by continuous evolution. Early RNN architectures faced challenges like the vanishing gradient problem, which hindered their ability to learn long-range dependencies. However, innovations like Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) networks have largely overcome these limitations, paving the way for the widespread adoption of RNNs in various fields.
Understanding the RNN Architecture
At the heart of an RNN lies the RNN cell, the fundamental building block responsible for processing sequential data. This cell receives an input and a hidden state from the previous time step. The hidden state acts as the “memory” of the network, carrying information about past inputs. The RNN cell combines the current input and the previous hidden state to produce a new hidden state and an output. This process is repeated for each element in the sequence, allowing the network to maintain context and learn dependencies.
The hidden state plays a pivotal role in capturing sequential information. It’s a vector that represents the network’s understanding of the sequence up to a given point. As the RNN processes the sequence, the hidden state is continuously updated, incorporating new information and refining its representation of the context. This dynamic updating of the hidden state is what enables RNNs to “remember” and learn from past inputs.
Diagrams and examples are incredibly helpful in visualizing the RNN architecture. Imagine an RNN processing a sentence word by word. At each time step, the RNN cell receives a word and the previous hidden state. It then updates the hidden state based on the current word and its relationship to the preceding words. The output of the RNN cell could be used for various tasks, such as predicting the next word in the sentence or classifying the sentiment of the sentence.
The Power of Memory: Long Short-Term Memory (LSTM) Networks
While basic RNNs are powerful, they struggle with a problem known as the vanishing gradient problem. This issue arises when training RNNs on long sequences, making it difficult for the network to learn long-range dependencies. The gradients, which are used to update the network’s weights, become increasingly small as they are backpropagated through time, effectively “vanishing” and preventing the network from learning from distant past inputs.
Long Short-Term Memory (LSTM) networks were developed to address the vanishing gradient problem. LSTMs have a more complex cell structure than basic RNNs, incorporating “gates” that regulate the flow of information. These gates allow LSTMs to selectively remember or forget information, enabling them to capture long-range dependencies more effectively.
An LSTM cell consists of several key components: the cell state, which acts as a long-term memory, and three gates: the input gate, the output gate, and the forget gate. The forget gate determines what information to discard from the cell state. The input gate decides what new information to store in the cell state. The output gate controls what information from the cell state to output. These gates, each implemented using sigmoid functions, carefully manage the flow of information, allowing LSTMs to learn and retain relevant information across long sequences. The LSTM’s ability to maintain a “long short-term memory” makes it significantly more effective than traditional RNNs for tasks like language
Applications of RNNs
RNNs have found widespread applications across various domains, demonstrating their versatility and power in handling sequential data. A core application of RNNs is in the field of deep learning. RNNs have revolutionized Natural Language Processing (NLP), enabling breakthroughs in language modeling and text generation, where they learn the statistical properties of language and generate coherent and grammatically correct text. They are also used in machine translation, where RNNs learn the relationships between words and phrases in different languages to translate text from one language to another.
Furthermore, in sentiment analysis, RNNs analyze text to determine the sentiment expressed, such as positive, negative, or neutral. Another key application is in question answering systems, where RNNs process questions and retrieve relevant answers from a given text. Beyond NLP, RNNs are commonly used in speech recognition to convert speech to text, recognizing the sequential nature of audio signals.
In the field of computer vision, while traditionally dominated by Convolutional Neural Networks (CNNs), RNNs are increasingly used in tasks like image captioning, where they generate descriptive captions for images by learning the relationships between visual features and words, and video analysis, where they analyze sequences of video frames to understand actions and events. RNNs are also well-suited for time series analysis, predicting future values in data such as stock prices, where they analyze historical stock prices and identify patterns to forecast future trends, and in forecasting weather patterns, where they process weather data to predict future weather conditions.
*Character-Level Language Models *
A particularly fascinating application of RNNs is the creation of character-level language models. These models learn to generate text character by character, capturing the underlying statistical structure of the language at a very fine-grained level. Training a character-level RNN involves feeding it a large corpus of text. The RNN learns to predict the probability of the next character given the preceding characters. Once trained, the RNN can generate new text by repeatedly sampling from its predicted probability distribution. The results can be surprisingly creative, with RNNs generating text that mimics the style and patterns of the training data. For example, an RNN trained on Shakespearean plays might generate text that resembles Shakespeare’s writing style.
Recent Developments and Research Directions
The field of Recurrent Neural Network is constantly evolving, with ongoing research pushing the boundaries of their capabilities.
Attention Mechanisms: Attention mechanisms allow RNNs to focus on the most relevant parts of the input sequence when making predictions. This significantly improves performance, especially for long sequences.
Transformers: While not strictly RNNs, Transformers are a novel architecture that has rivaled RNNs in many tasks, particularly in NLP. Transformers use self-attention mechanisms to process the entire input sequence in parallel, offering advantages in terms of speed and long-range dependency modeling.
RNNs with external memory: Researchers are exploring ways to augment RNNs with external memory modules, allowing them to store and retrieve information more effectively.
Bidirectional RNNs: Bidirectional RNNs process the input sequence in both forward and backward directions, allowing them to capture context from both the past and the future.
Advantages and Disadvantages of RNNs
Like any technology, RNNs have their strengths and weaknesses.
Advantages:
Handling sequential data: RNNs are specifically designed for sequential data, making them ideal for tasks where order matters.
Capturing long-range dependencies (with LSTMs): LSTMs and GRUs can effectively capture long-range dependencies, allowing RNNs to learn from distant past inputs.
Versatility in applications: RNNs have proven effective in a wide range of applications, from NLP to time series analysis.
Disadvantages:
Vanishing/exploding gradients: Basic RNNs can suffer from vanishing or exploding gradients, making them difficult to train.
Difficulty in parallelizing computations: The sequential nature of RNNs makes it challenging to parallelize computations, which can slow down training.
Can be computationally expensive: Training large RNNs can be computationally demanding.
*Conclusion *
Recurrent Neural Networks have emerged as a powerful tool for processing sequential data, driving significant advancements in various fields. Their ability to capture dependencies and learn from context has made them indispensable in applications ranging from natural language processing to time series analysis. While challenges remain, ongoing research and innovations like LSTMs, attention mechanisms, and Transformers continue to expand the capabilities and potential of RNNs. As we move forward, RNNs will undoubtedly play an increasingly crucial role in shaping the future of artificial intelligence and, more broadly, deep learning.
Ready to dive deeper into the world of AI and future technologies? Visit Win in Life Academy to explore cutting-edge courses and unlock your potential in this transformative era.


