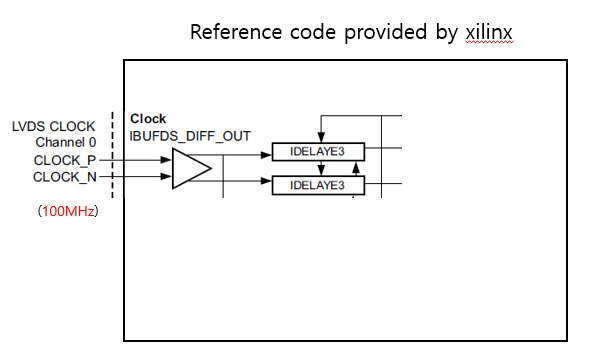
_courtesy_VERTICAL.jpg)






















































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)












































































































































































































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




















































































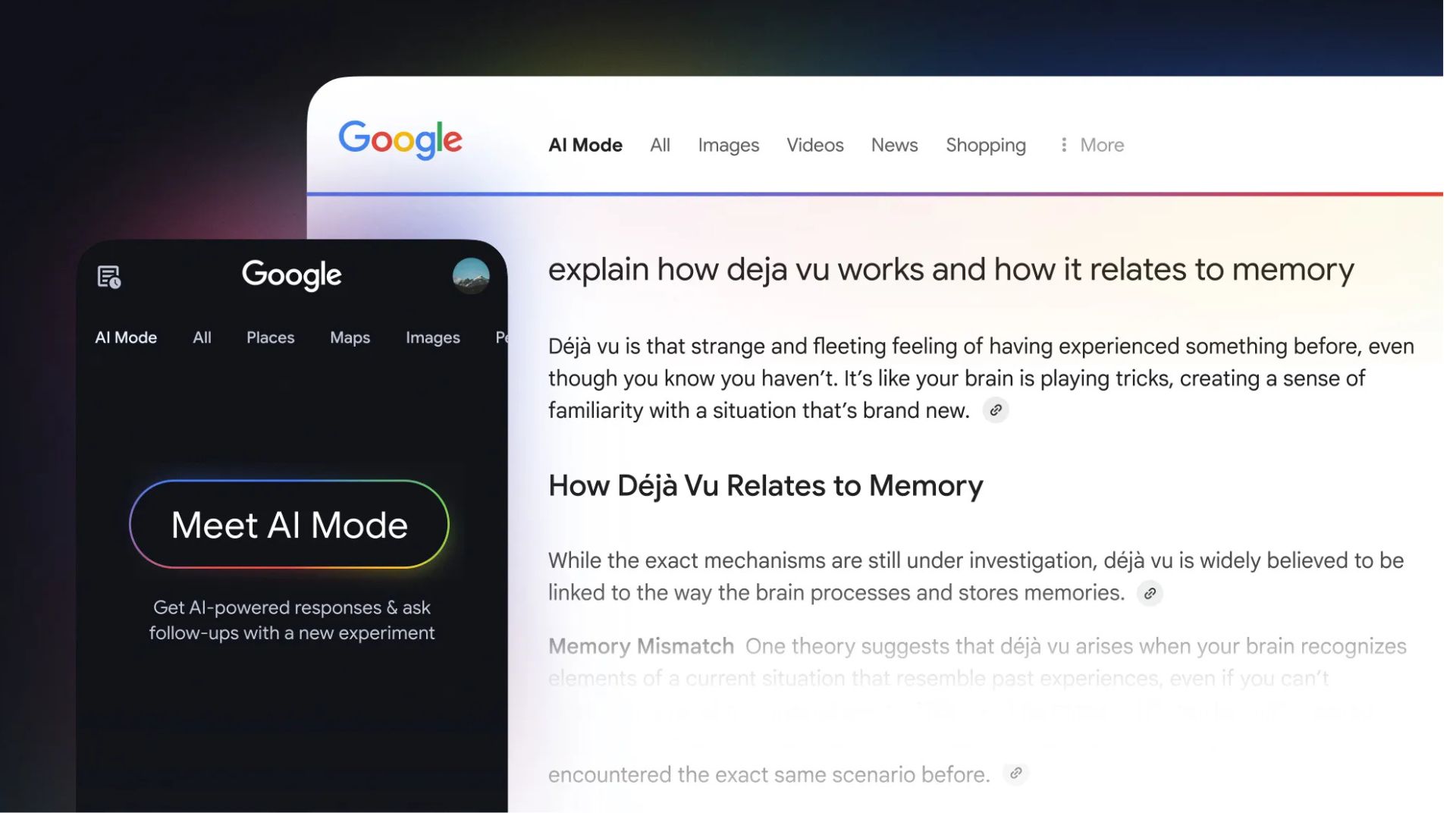



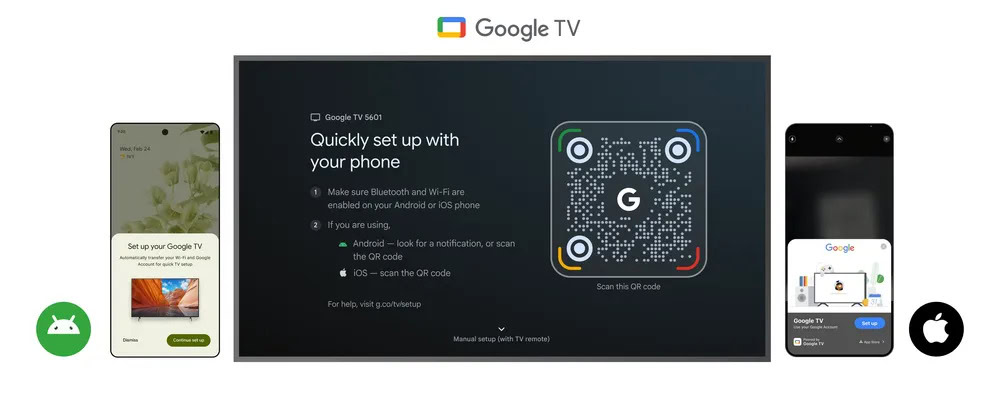




















![Apple Ships 55 Million iPhones, Claims Second Place in Q1 2025 Smartphone Market [Report]](https://www.iclarified.com/images/news/97185/97185/97185-640.jpg)



























































































Qwen 3 Benchmarks, Comparisons, Model Specifications, and More
Originally shared here: Qwen 3 Benchmarks, Comparisons, Model Specifications, and More Details about Qwen3; including benchmarks and comparisons, model sizes and specifications, and more bestcodes.dev Qwen3: Alibaba's Latest Open-Source AI Model Qwen3 is the latest generation of large language models (LLMs) from Alibaba Cloud. Built by the team behind the Tongyi Qianwen series (通义千问), this release brings serious power and flexibility, packed into an Apache-2.0-licensed, open-source package. Released on April 29, 2025, Qwen3 comes in eight sizes, including both dense models (from 600M to 32B parameters) and Mixture-of-Experts (MoE) giants, like the flagship Qwen3-235B. These MoE models activate only a small slice of their total parameters at a time (like 22B out of 235B), so you get high performance without insane compute requirements. Let's dive into some of the key features. Model Sizes and Options Here's a quick look at what you can choose from: Model Type Params (Total / Active) Max Context Qwen3-235B-A22B MoE 235B / 22B 128K Qwen3-30B-A3B MoE 30B / 3B 128K Qwen3-32B Dense 32B 128K Qwen3-14B Dense 14B 128K Qwen3-8B Dense 8B 128K Qwen3-4B Dense 4B 32K Qwen3-1.7B Dense 1.7B 32K Qwen3-0.6B Dense 0.6B 32K All models are licensed under Apache 2.0, so you can use them in commercial apps without worrying about legal issues. Benchmarks and Comparisons The benchmarks below evaluate Qwen3 with reasoning enabled. Qwen3-235B (the flagship model) leads on the CodeForces ELO Rating, BFCL, and LiveCodeBench v5 benchmarks but trails behind Gemini 2.5 Pro on ArenaHard, AIME, MultilF, and Aider Pass@2: Compared to open-source and less bleeding-edge models, Qwen3-30B (a smaller model) excels in both speed and accuracy. It is outranked only by QwQ-32B, another Alibaba model, in the LiveCodeBench and CodeForces benchmarks as well as GPT-4o in the BFCL benchmark: Below, despite being the second-smallest model, Qwen3-235B outranks all models on all benchmarks, excepting DeepSeek v3 on the INCLUDE Multilingual tasks benchmark. What's New in Qwen3? Dual "Thinking" Modes This is one of the coolest features: Qwen3 can switch between "thinking" mode and "non-thinking" mode. Thinking mode is for deep reasoning, like chain-of-thought answers for complex tasks. Non-thinking mode skips the fluff and gives you fast, concise responses. So, depending on the prompt or task, Qwen3 can choose to think deeply or just get to the point. That means better speed when you want it, and better depth when you need it. MoE for Smarter Scaling The MoE (Mixture-of-Experts) architecture is how Qwen3 pulls off those giant parameter counts. Instead of using all the parameters every time, it activates only a few "experts" per token. For example, Qwen3-235B uses just 22B active parameters at once, so it's much cheaper to run than you'd expect for its size. It's a smart way to scale up without blowing your budget on GPUs. Trained on 36 Trillion Tokens Across 119 Languages Qwen3 was trained on a massive dataset of about 36 trillion tokens, including web data, books, PDFs, and synthetic code/math generated by earlier Qwen models. It now understands 119 languages and dialects, making it one of the most multilingual models out there. Whether you're working in English, Chinese, or a low-resource language, Qwen3 is probably ready to help. Smarter Agents and Better Coders Qwen3 wasn't just trained to talk. Alibaba also focused on tool use, planning, and coding, making this generation much better at things like: Writing and debugging code Solving math and logic problems step-by-step Acting as an AI agent that can use tools or browse the web In fact, even the Qwen3-4B reportedly outperforms some earlier 72B models on tasks like programming. Getting Started You can grab the models from:

Originally shared here:
Qwen 3 Benchmarks, Comparisons, Model Specifications, and More
Details about Qwen3; including benchmarks and comparisons, model sizes and specifications, and more
bestcodes.dev
Qwen3: Alibaba's Latest Open-Source AI Model
Qwen3 is the latest generation of large language models (LLMs) from Alibaba Cloud. Built by the team behind the Tongyi Qianwen series (通义千问), this release brings serious power and flexibility, packed into an Apache-2.0-licensed, open-source package.
Released on April 29, 2025, Qwen3 comes in eight sizes, including both dense models (from 600M to 32B parameters) and Mixture-of-Experts (MoE) giants, like the flagship Qwen3-235B. These MoE models activate only a small slice of their total parameters at a time (like 22B out of 235B), so you get high performance without insane compute requirements.
Let's dive into some of the key features.
Model Sizes and Options
Here's a quick look at what you can choose from:
| Model | Type | Params (Total / Active) | Max Context |
|---|---|---|---|
| Qwen3-235B-A22B | MoE | 235B / 22B | 128K |
| Qwen3-30B-A3B | MoE | 30B / 3B | 128K |
| Qwen3-32B | Dense | 32B | 128K |
| Qwen3-14B | Dense | 14B | 128K |
| Qwen3-8B | Dense | 8B | 128K |
| Qwen3-4B | Dense | 4B | 32K |
| Qwen3-1.7B | Dense | 1.7B | 32K |
| Qwen3-0.6B | Dense | 0.6B | 32K |
All models are licensed under Apache 2.0, so you can use them in commercial apps without worrying about legal issues.
Benchmarks and Comparisons
The benchmarks below evaluate Qwen3 with reasoning enabled.
Qwen3-235B (the flagship model) leads on the CodeForces ELO Rating, BFCL, and LiveCodeBench v5 benchmarks but trails behind Gemini 2.5 Pro on ArenaHard, AIME, MultilF, and Aider Pass@2:

Compared to open-source and less bleeding-edge models, Qwen3-30B (a smaller model) excels in both speed and accuracy. It is outranked only by QwQ-32B, another Alibaba model, in the LiveCodeBench and CodeForces benchmarks as well as GPT-4o in the BFCL benchmark:

Below, despite being the second-smallest model, Qwen3-235B outranks all models on all benchmarks, excepting DeepSeek v3 on the INCLUDE Multilingual tasks benchmark.

What's New in Qwen3?
Dual "Thinking" Modes
This is one of the coolest features: Qwen3 can switch between "thinking" mode and "non-thinking" mode. Thinking mode is for deep reasoning, like chain-of-thought answers for complex tasks. Non-thinking mode skips the fluff and gives you fast, concise responses.
So, depending on the prompt or task, Qwen3 can choose to think deeply or just get to the point. That means better speed when you want it, and better depth when you need it.
MoE for Smarter Scaling
The MoE (Mixture-of-Experts) architecture is how Qwen3 pulls off those giant parameter counts. Instead of using all the parameters every time, it activates only a few "experts" per token. For example, Qwen3-235B uses just 22B active parameters at once, so it's much cheaper to run than you'd expect for its size.
It's a smart way to scale up without blowing your budget on GPUs.
Trained on 36 Trillion Tokens Across 119 Languages
Qwen3 was trained on a massive dataset of about 36 trillion tokens, including web data, books, PDFs, and synthetic code/math generated by earlier Qwen models. It now understands 119 languages and dialects, making it one of the most multilingual models out there.
Whether you're working in English, Chinese, or a low-resource language, Qwen3 is probably ready to help.
Smarter Agents and Better Coders
Qwen3 wasn't just trained to talk. Alibaba also focused on tool use, planning, and coding, making this generation much better at things like:
- Writing and debugging code
- Solving math and logic problems step-by-step
- Acting as an AI agent that can use tools or browse the web
In fact, even the Qwen3-4B reportedly outperforms some earlier 72B models on tasks like programming.
Getting Started
You can grab the models from: