


















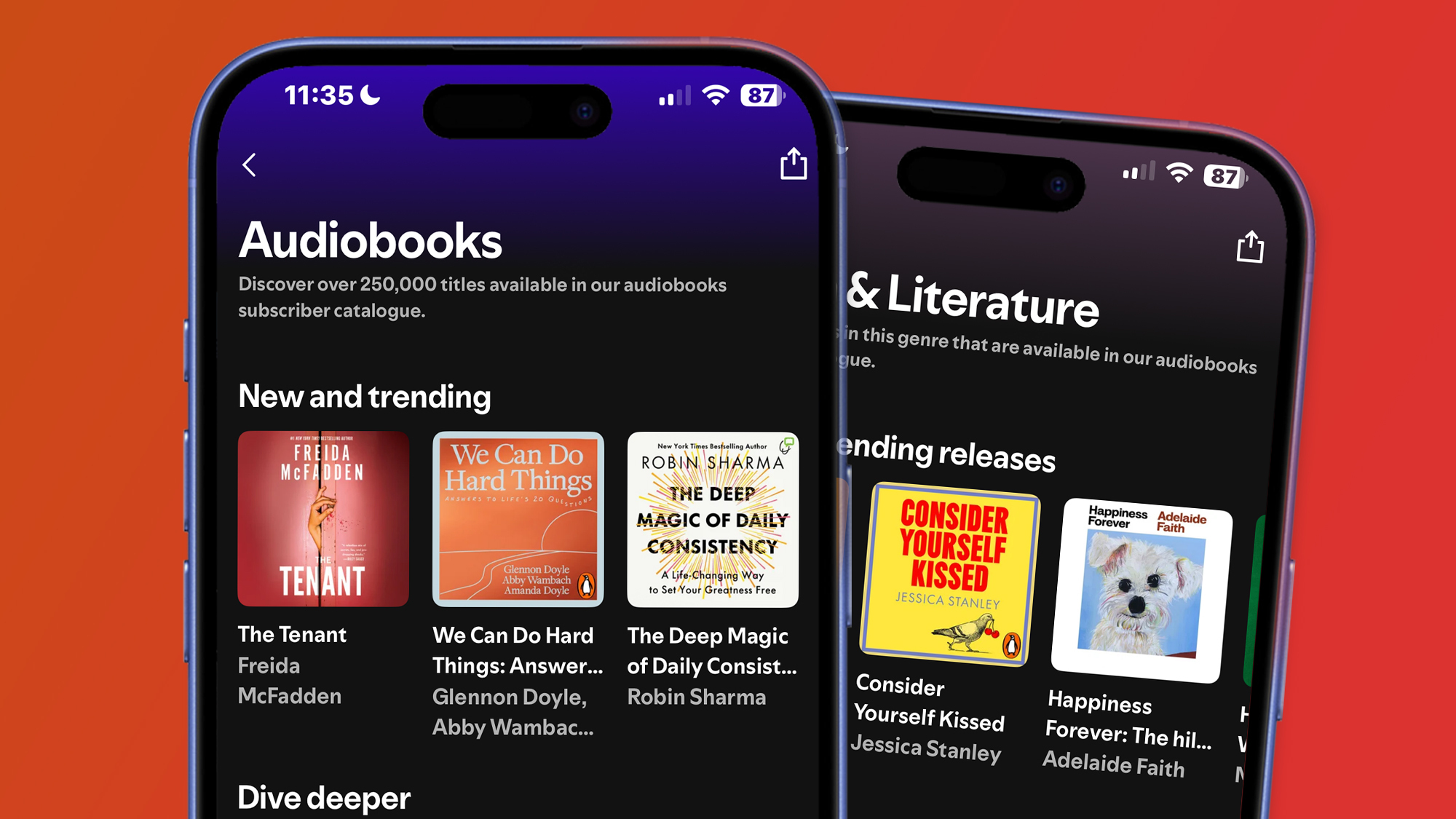
























































































































































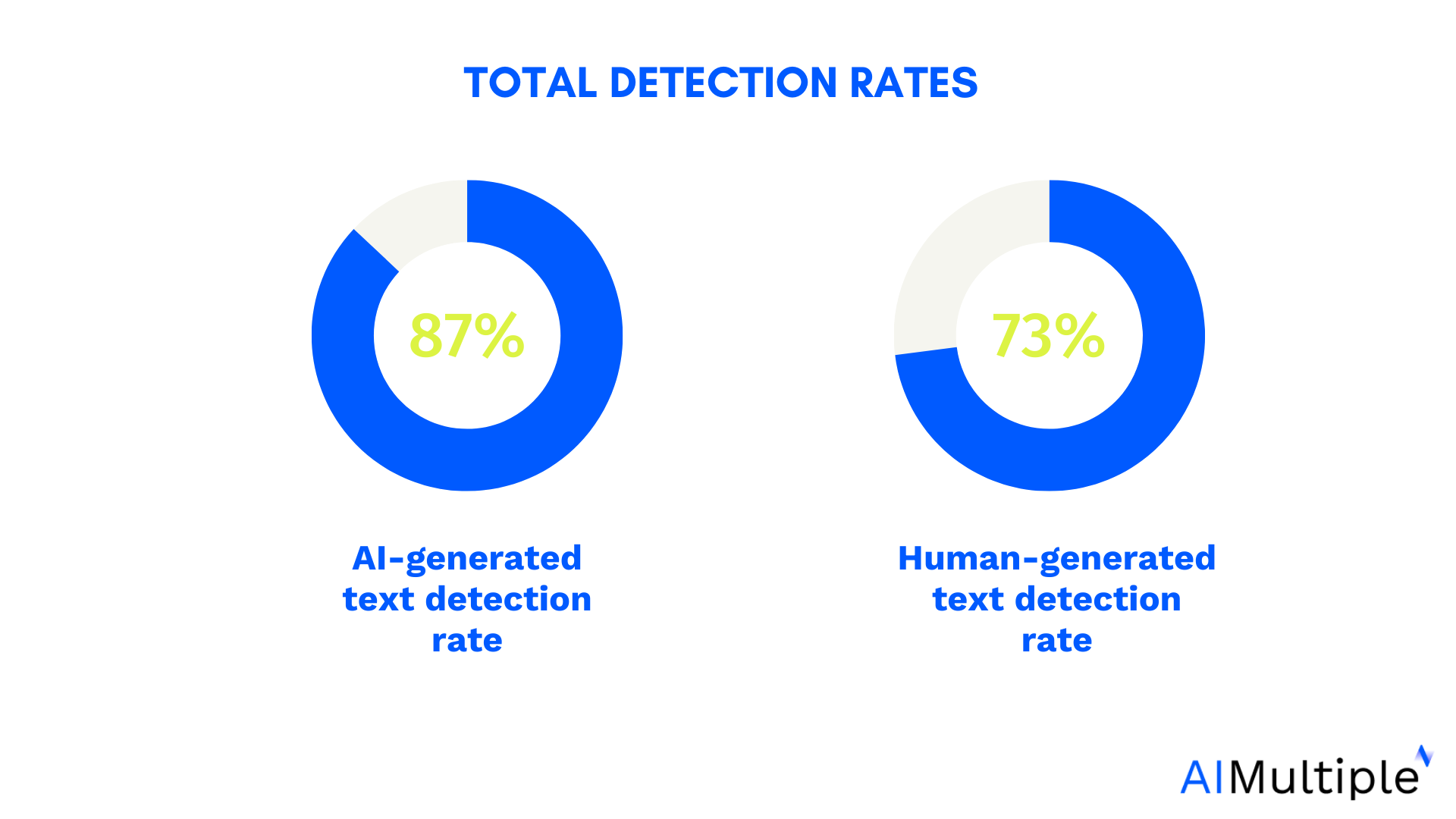
![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)



























































































































![Ditching a Microsoft Job to Enter Startup Purgatory with Lonewolf Engineer Sam Crombie [Podcast #171]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746753508177/0cd57f66-fdb0-4972-b285-1443a7db39fc.png?#)






















































































































_Piotr_Adamowicz_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)












_designer491_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)

















































































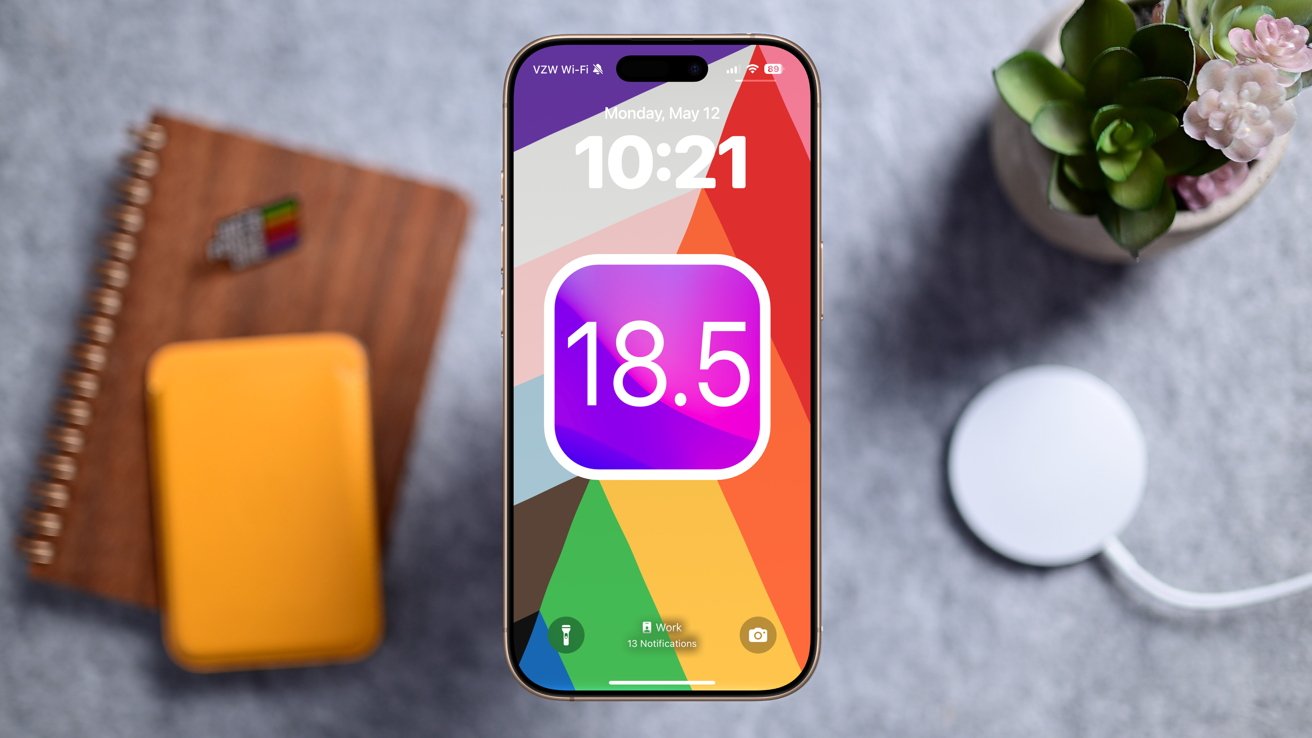





















![Apple Officially Releases macOS Sequoia 15.5 [Download]](https://www.iclarified.com/images/news/97308/97308/97308-640.jpg)




























































































Programming language of the future Part 3: OOP
We want to manage state, by dividing it into units and giving them a name. Attaching behavior to them is also a good option - and thus we have OOP. But let's not adopt it blindly - a critical examination is in order. OOP is there to promote Encapsulation, Polymorphism, Abstraction. What would be the optimal way of providing them? Three pillars of OOP Encapsulation means exposing only as much information about the object as necessary to provide the service. All of the information that is exposed and used by clients, if it were to be changed, means that either the client has to change at the same time - or versioning would need to take place. This idea makes sense, and for a language to support it, it would need ways to mark visibility of fields and methods. Polymorphism means for the same object to exhibit different behaviors in different contexts. Important for clearly stating one's intentions as a programmer - this method operates on objects that support this behavior. This cleanly maps on interfaces, and inversion of control. What it doesn't cleanly map to, is inheritance. And lastly, Abstraction. Ability to move up towards the general, and down towards the particular. This allows us to create larger, more general systems, out of smaller, more particular ones. Ergonomically achieved with object composition. The optimal solution Any choice of technology is a compomise, so let me explain why I believe this one to be optimal. Interfaces, extending them, and implementing them, are well-understood industry practices - and it makes sense, why. They work well at describing behavior, as well as variations of similar behavior (when extending interfaces). Object composition is also broadly accepted - constructing more complex objects out of simpler ones is how we create complex systems out of simpler ones. But it doesn't work well when you try to create a class that's only slightly different from a base class - then you either need a lot of boilerplate for passing things back and forth, or you can reach for the convenient solution - inherit from the class, and overwrite one method. But this is a trap. You should never want to create a class which is "slightly different" from the base class. If you want slightly different behavior - introduce a configuration parameter. If you are making a larger system out of smaller building blocks - your methods shouldn't be blindly passing parameters back and forth anyways, there should be actual logic in them. Never change the base? All abstraction comes down to not having to change anything existing, while trying to add new functionality. But there's also industry wisdom that abstraction has a cost, and you should only abstract when necessary - so, when you have more than one way of doing something, for example. And that does require changing the "base" that you're abstracting from. So why do some methodologies commit to never change the "base" at all, and only wrap, adapt, extend, override? I believe it's due to the nature of dealing with proprietary legacy software, that you physically cannot change - and the developer for which may no longer be supporting it. Then it makes sense to orient your language around supporting any hacks around it. But they are still hacks - and unsupported legacy software only gets you so far anyways. If we assume a healthier ecosystem, where software is in public repositories, even if requires payment for commercial use, with a working issue tracker and short lead times for bug fixes - we can ditch that whole set of crutches. For example, by overriding something - you introduce tight coupling. You now cannot confidently change the base class, because something somewhere may depend on a quirk of it. So you are now practically ensuring that you will never change it - and only ever continue adding functionality by further inheriting and overriding. This isn't a good model. If you want to have two implementations of the same functionality that sometimes differ, but are largely the same - introduce one class with configuration. If they present the same behavior, but are implemented totally differently - introduce two classes implementing the same interface. That way you can confidently change any class, you avoid the diamond problem, and you abstract only when you have to. Conclusion I believe this serves as a solid foundation to an object system. I have not touched on prototype-based inheritance, because I see no use for the flexibility it offers. We will continue our exploration in future blogs.

We want to manage state, by dividing it into units and giving them a name. Attaching behavior to them is also a good option - and thus we have OOP. But let's not adopt it blindly - a critical examination is in order. OOP is there to promote Encapsulation, Polymorphism, Abstraction. What would be the optimal way of providing them?
Three pillars of OOP
Encapsulation means exposing only as much information about the object as necessary to provide the service. All of the information that is exposed and used by clients, if it were to be changed, means that either the client has to change at the same time - or versioning would need to take place. This idea makes sense, and for a language to support it, it would need ways to mark visibility of fields and methods.
Polymorphism means for the same object to exhibit different behaviors in different contexts. Important for clearly stating one's intentions as a programmer - this method operates on objects that support this behavior. This cleanly maps on interfaces, and inversion of control. What it doesn't cleanly map to, is inheritance.
And lastly, Abstraction. Ability to move up towards the general, and down towards the particular. This allows us to create larger, more general systems, out of smaller, more particular ones. Ergonomically achieved with object composition.
The optimal solution
Any choice of technology is a compomise, so let me explain why I believe this one to be optimal. Interfaces, extending them, and implementing them, are well-understood industry practices - and it makes sense, why. They work well at describing behavior, as well as variations of similar behavior (when extending interfaces). Object composition is also broadly accepted - constructing more complex objects out of simpler ones is how we create complex systems out of simpler ones. But it doesn't work well when you try to create a class that's only slightly different from a base class - then you either need a lot of boilerplate for passing things back and forth, or you can reach for the convenient solution - inherit from the class, and overwrite one method.
But this is a trap. You should never want to create a class which is "slightly different" from the base class. If you want slightly different behavior - introduce a configuration parameter. If you are making a larger system out of smaller building blocks - your methods shouldn't be blindly passing parameters back and forth anyways, there should be actual logic in them.
Never change the base?
All abstraction comes down to not having to change anything existing, while trying to add new functionality. But there's also industry wisdom that abstraction has a cost, and you should only abstract when necessary - so, when you have more than one way of doing something, for example. And that does require changing the "base" that you're abstracting from. So why do some methodologies commit to never change the "base" at all, and only wrap, adapt, extend, override? I believe it's due to the nature of dealing with proprietary legacy software, that you physically cannot change - and the developer for which may no longer be supporting it. Then it makes sense to orient your language around supporting any hacks around it. But they are still hacks - and unsupported legacy software only gets you so far anyways. If we assume a healthier ecosystem, where software is in public repositories, even if requires payment for commercial use, with a working issue tracker and short lead times for bug fixes - we can ditch that whole set of crutches.
For example, by overriding something - you introduce tight coupling. You now cannot confidently change the base class, because something somewhere may depend on a quirk of it. So you are now practically ensuring that you will never change it - and only ever continue adding functionality by further inheriting and overriding. This isn't a good model. If you want to have two implementations of the same functionality that sometimes differ, but are largely the same - introduce one class with configuration. If they present the same behavior, but are implemented totally differently - introduce two classes implementing the same interface. That way you can confidently change any class, you avoid the diamond problem, and you abstract only when you have to.
Conclusion
I believe this serves as a solid foundation to an object system. I have not touched on prototype-based inheritance, because I see no use for the flexibility it offers. We will continue our exploration in future blogs.


