








































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)












































































































































































































































.jpg?#)




























































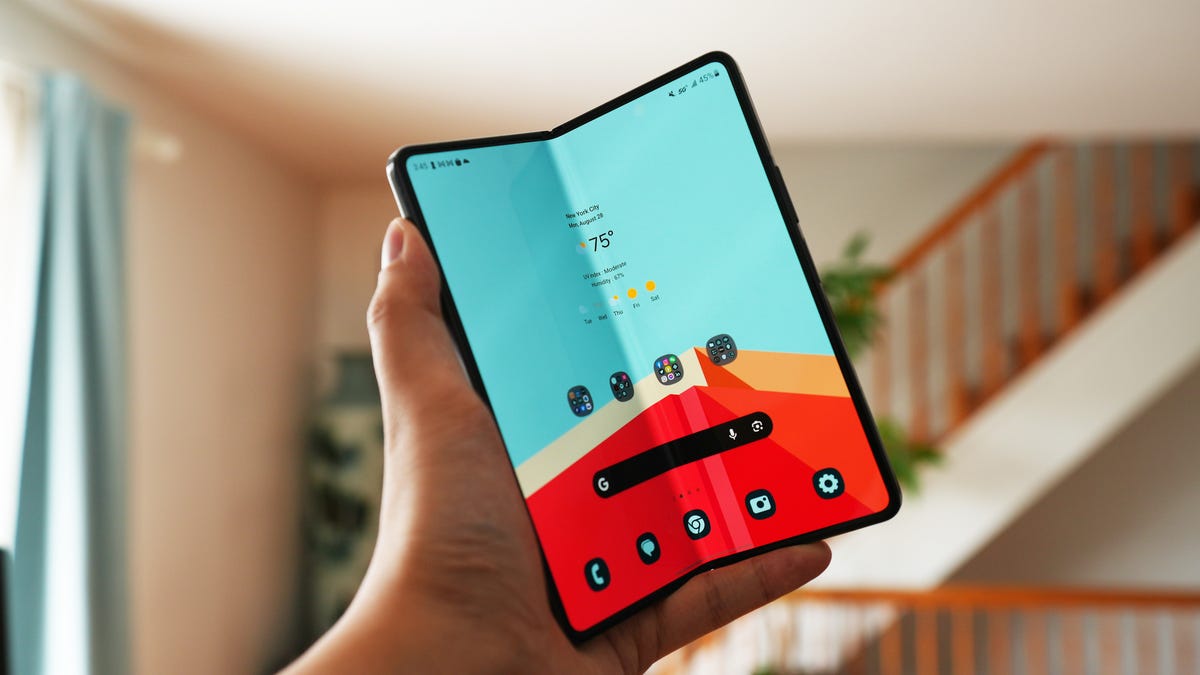











































































![Apple to Shift Robotics Unit From AI Division to Hardware Engineering [Report]](https://www.iclarified.com/images/news/97128/97128/97128-640.jpg)

![Apple Shares New Ad for iPhone 16: 'Trust Issues' [Video]](https://www.iclarified.com/images/news/97125/97125/97125-640.jpg)




























































































































Personalized Images: Auto-Regressive Models Rival Diffusion in New Study
This is a Plain English Papers summary of a research paper called Personalized Images: Auto-Regressive Models Rival Diffusion in New Study. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Exploring a New Frontier in Personalized Image Generation Personalized image synthesis has become a pivotal application in text-to-image generation, enabling the creation of images featuring specific subjects in diverse contexts. This capability is particularly valuable for applications in digital art, advertising, and virtual reality, where seamlessly integrating personalized content into diverse scenes is crucial. While diffusion models have dominated personalized image generation, auto-regressive models, with their unified architecture for text and image modeling, remain underexplored for this task. This research investigates the potential of optimizing auto-regressive models for personalized image synthesis, leveraging their inherent multimodal capabilities. The researchers propose a novel two-stage training strategy that combines optimization of text embeddings and fine-tuning of transformer layers. Their experiments on the Lumina-mGPT 7B model demonstrate that this method achieves comparable subject fidelity and prompt following to leading diffusion-based personalization methods. Overview of the personalization process, showing how just a few reference images can be used to generate diverse personalized images. Understanding the Landscape: Related Work in Image Personalization and Generation Personalized Image Synthesis: From Diffusion Models to Unified Approaches Personalized image synthesis focuses on generating images of specific subjects in novel contexts while seamlessly integrating them into new scenes. The advent of diffusion models has significantly advanced text-guided image generation, offering remarkable flexibility to personalize text-to-image models. Current diffusion-based personalization models can be broadly divided into two categories: Optimization-based models (like Textual Inversion and DreamBooth) optimize embeddings of text tokens or fine-tune the backbone to implant a new subject into the model's output domain. Tuning-free models pre-train a separate encoder to extract subject features, enabling zero-shot personalized image generation without per-subject optimization. Recent advancements in unified multimodal models have expanded personalized image synthesis into broader multimodal tasks. However, when personalized image generation is included as one of many tasks for these models, its performance often lags behind models specially designed for this task. Auto-regressive Image Generation: Evolution and Current State Auto-regressive models generate data through next token prediction. Early auto-regressive image generation models like PixelCNN and PixelRNN operated at the pixel level, but their computational demands became prohibitive due to the high dimensionality of images. The introduction of VQVAE addressed this by compressing images into discrete tokens and enabled a two-stage approach: image tokenization followed by auto-regressive modeling of token distributions. This framework revitalized auto-regressive image generation. Building on this, models like DALL-E and CogView extended auto-regressive methods to text-to-image generation. They compress images into tokens with an autoencoder. By concatenating the text tokens and image tokens, they train a decoder-only transformer to predict the next image token. Chameleon advances the framework by enabling mixed-modal generation of interleaved text and image sequences using a unified transformer architecture, eliminating the need for separate text encoders. Lumina-mGPT inherits Chameleon's tokenizers and trains an auto-regressive transformer from scratch, enabling image generation and other vision-centric tasks. Diffusion models and auto-regressive models differ fundamentally in their paradigms. Diffusion models excel in iterative refinement, while auto-regressive models employ a unified architecture for text and image modeling, making them inherently compatible with multimodal tasks. Building Blocks: Understanding the Foundations of Personalization Personalizing Text-to-Image Models: How Optimization Works Textual Inversion proposes a personalization method by creating a new "pseudo-word" within the text embedding space of a text-to-image diffusion model. Using just 3-5 images of a specific subject provided by the user, this method optimizes the embedding vector corresponding to the pseudo-word to represent that subject. This word can then be used to compose natural language prompts, such as "a S* on the beach", to generate personalized images in novel contexts. DreamBooth opts to optimize a unique identifier "[V]" that precedes the subject class (for example, "a [V] cat/dog/toy on the beach"). This approach helps to link

This is a Plain English Papers summary of a research paper called Personalized Images: Auto-Regressive Models Rival Diffusion in New Study. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Exploring a New Frontier in Personalized Image Generation
Personalized image synthesis has become a pivotal application in text-to-image generation, enabling the creation of images featuring specific subjects in diverse contexts. This capability is particularly valuable for applications in digital art, advertising, and virtual reality, where seamlessly integrating personalized content into diverse scenes is crucial.
While diffusion models have dominated personalized image generation, auto-regressive models, with their unified architecture for text and image modeling, remain underexplored for this task. This research investigates the potential of optimizing auto-regressive models for personalized image synthesis, leveraging their inherent multimodal capabilities.
The researchers propose a novel two-stage training strategy that combines optimization of text embeddings and fine-tuning of transformer layers. Their experiments on the Lumina-mGPT 7B model demonstrate that this method achieves comparable subject fidelity and prompt following to leading diffusion-based personalization methods.
Overview of the personalization process, showing how just a few reference images can be used to generate diverse personalized images.
Understanding the Landscape: Related Work in Image Personalization and Generation
Personalized Image Synthesis: From Diffusion Models to Unified Approaches
Personalized image synthesis focuses on generating images of specific subjects in novel contexts while seamlessly integrating them into new scenes. The advent of diffusion models has significantly advanced text-guided image generation, offering remarkable flexibility to personalize text-to-image models.
Current diffusion-based personalization models can be broadly divided into two categories:
Optimization-based models (like Textual Inversion and DreamBooth) optimize embeddings of text tokens or fine-tune the backbone to implant a new subject into the model's output domain.
Tuning-free models pre-train a separate encoder to extract subject features, enabling zero-shot personalized image generation without per-subject optimization.
Recent advancements in unified multimodal models have expanded personalized image synthesis into broader multimodal tasks. However, when personalized image generation is included as one of many tasks for these models, its performance often lags behind models specially designed for this task.
Auto-regressive Image Generation: Evolution and Current State
Auto-regressive models generate data through next token prediction. Early auto-regressive image generation models like PixelCNN and PixelRNN operated at the pixel level, but their computational demands became prohibitive due to the high dimensionality of images.
The introduction of VQVAE addressed this by compressing images into discrete tokens and enabled a two-stage approach: image tokenization followed by auto-regressive modeling of token distributions. This framework revitalized auto-regressive image generation.
Building on this, models like DALL-E and CogView extended auto-regressive methods to text-to-image generation. They compress images into tokens with an autoencoder. By concatenating the text tokens and image tokens, they train a decoder-only transformer to predict the next image token.
Chameleon advances the framework by enabling mixed-modal generation of interleaved text and image sequences using a unified transformer architecture, eliminating the need for separate text encoders. Lumina-mGPT inherits Chameleon's tokenizers and trains an auto-regressive transformer from scratch, enabling image generation and other vision-centric tasks.
Diffusion models and auto-regressive models differ fundamentally in their paradigms. Diffusion models excel in iterative refinement, while auto-regressive models employ a unified architecture for text and image modeling, making them inherently compatible with multimodal tasks.
Building Blocks: Understanding the Foundations of Personalization
Personalizing Text-to-Image Models: How Optimization Works
Textual Inversion proposes a personalization method by creating a new "pseudo-word" within the text embedding space of a text-to-image diffusion model. Using just 3-5 images of a specific subject provided by the user, this method optimizes the embedding vector corresponding to the pseudo-word to represent that subject. This word can then be used to compose natural language prompts, such as "a S* on the beach", to generate personalized images in novel contexts.
DreamBooth opts to optimize a unique identifier "[V]" that precedes the subject class (for example, "a [V] cat/dog/toy on the beach"). This approach helps to link the prior knowledge of the class with the subject, thereby reducing training time. However, using the class name can lead to a gradual loss of the model's broader semantic knowledge during fine-tuning, a phenomenon known as language drift. To address this issue, a class-specific prior preservation loss is introduced to retain the model's ability to generate diverse instances of the class.
These optimization-based approaches are implemented and proven to be effective on text-to-image diffusion models. They can effectively perform various personalization tasks, including subject recontextualization, text-guided view synthesis, and artistic rendering.
Text-to-Image Generation: How Auto-Regressive Models Create Images
Auto-regressive text-to-image models generate images in three steps:
A tokenizer converts the input text into a sequence of discrete tokens, which are transformed into vector embeddings.
These text embeddings are fed into an auto-regressive transformer that outputs logits. The logits are converted into probabilities where the next image token is sampled. The newly sampled token is concatenated with the preceding tokens to predict the subsequent token.
An image decoder translates the complete sequence of tokens into image pixels.
During training, the auto-regressive transformer models the conditional probability of the sequential tokens using the standard next-token prediction objective. The loss function for a single prediction uses cross-entropy loss to measure the difference between predicted and target tokens.
Most auto-regressive text-to-image models adopt classifier-free guidance (CFG) to enhance the quality of generated images. This technique amplifies the influence of the text condition on the generation process.
The Two-Stage Approach: How to Personalize Auto-Regressive Models
Personalizing a text-to-image model generally involves two strategies. The first associates a unique text embedding with the subject, either representing the subject as a whole or serving as an adjective describing the subject class. The second strategy involves fine-tuning the model parameters to effectively embed the subject's appearance.
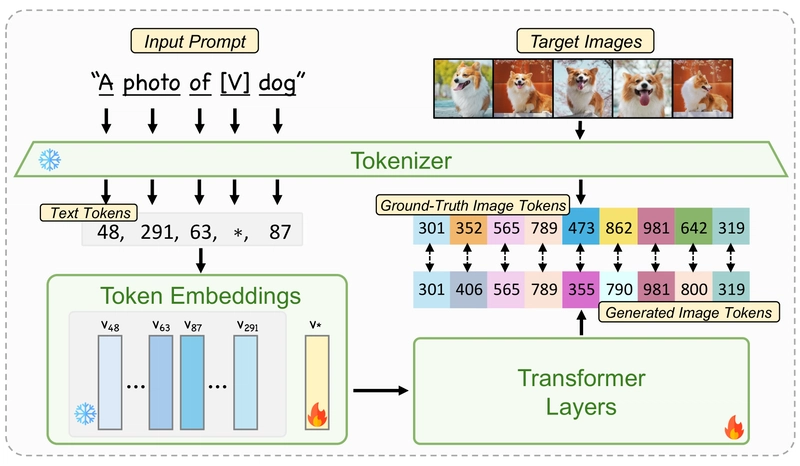
Overview of Fine-tuning. The process involves two distinct stages to optimize both text embeddings and transformer layers.
Stage 1: Teaching New Words to the Model
The researchers generally follow the DreamBooth approach to optimize a text embedding for a specific subject. They introduce a placeholder word [V], to represent the unique identifier of the new subject. The input text that includes the identifier [V] and the subject class name is then converted to tokens.
The embedding associated with the token for [V] is replaced with a new randomly initialized embedding. With a small set of reference images (e.g., 3-5) of the subject in various backgrounds or poses, this embedding is optimized based on the cross-entropy loss. For the input text, templates like "A photo of [V] [class_name]" or "A rendition of [V] [class_name]" are used.
Textual Inversion introduces a scheme that inserts a unique token for each reference image in the text template. Given a set of reference images, the method associates each image with a unique placeholder, optimizing the embeddings to capture the distinct features of each individual image while minimizing the influence of non-common elements on the universal placeholder [V].
The researchers observed that auto-regressive models are sensitive to specific wording. When prompts use different prepositions or structures during inference, the quality of the generated images tends to decrease. To avoid this issue, they use the format "A photo of [V] [class_name] Si", where Si can represent any form of phrase.
Additionally, they found that introducing the per-image tokens in all training prompts affects the quality of the generated images when attempting to reconstruct the subject using the prompt "A photo of [V] [class_name]". However, removing all per-image tokens makes it more challenging to eliminate content irrelevant to the subject. To strike a balance, they opt for a compromise strategy that incorporates both formats with a 1:1 ratio.
Stage 2: Fine-Tuning the Model's Understanding
The researchers observed that the generated images fail to accurately replicate the reference subject if they optimize the text embeddings only. Given the limited capacity of text embeddings, fine-tuning the auto-regressive transformer becomes necessary to effectively implant the subject into the model's output domain.
DreamBooth fine-tunes the layers conditioned on the text embeddings and the diffusion UNet simultaneously. In their experiments, the researchers found that when fine-tuning the text embeddings and transformer layers together, the text embeddings cannot get fully trained. If they revert to the original transformer layers during inference, the text embeddings alone fail to convey any meaningful content.
To address this issue, they devised a two-stage training strategy. In the first stage, they fully optimize the text embeddings, and in the second stage, they fine-tune the transformer layers to maximize the subject fidelity. This two-stage approach is mutually beneficial: the first stage stabilizes the training and reduces the effort needed in the second stage, while the second stage compensates for any defects from the first stage due to its inherent limitations.
Implementation Details: Making It Work in Practice
The text embeddings are initialized randomly. The experiments use a batch size of 1, which corresponds to approximately 8 text-image pairs. In the first stage, the learning rate for optimizing the text embeddings is set to 0.01, training for approximately 1500 steps. In the second stage, about 70 steps with a learning rate of 5×10^-6 is enough for full fine-tuning.
These training parameters work well for most cases. For some common subjects (e.g., dog, cat), satisfactory results can be achieved with fewer training steps in both stages. However, for challenging subjects, more training steps in the second stage are required for better results.
The first stage takes about 15 minutes, and the second stage takes only 2 minutes on a single H100 GPU, making this approach efficient for practical applications where pre-trained language models may struggle.
Putting It to the Test: Experiments and Results
Evaluation Framework: How We Measured Success
The model's personalization capability was evaluated on Dreambench, which provides a dataset consisting of 30 subjects, each with 4-6 images. These subjects are divided into two groups: 21 objects and 9 live subjects/pets. Each subject is tested on 25 prompts, which include scenarios such as re-contextualization, accessorization, and property modification.
Following Dreambench, the researchers employ DINO and CLIP-I to assess subject fidelity, and CLIP-T to measure prompt following. For evaluation, images are generated using a fixed CFG value of 4.0 and an image top-k value of 2000.
Subject fidelity is computed by calculating the average similarity between each generated image and all reference images for that subject, then averaging across all 25 prompts and all 30 subjects. For prompt following, the score for each generated image is calculated by computing the cosine similarity between CLIP embeddings of the image and the corresponding prompt.
Quantitative Analysis: Measuring Up Against the Competition
| Method | DINO ↑ | CLIP-I ↑ | CLIP-T ↑ |
|---|---|---|---|
| Real Images | 0.774 | 0.885 | N/A |
| Textual Inversion [6] | 0.569 | 0.780 | 0.255 |
| Re-Imagen [3] | 0.600 | 0.740 | 0.270 |
| DreamBooth (Stable Diffusion) [26] | 0.668 | 0.803 | 0.305 |
| DreamBooth (Imagen) [26] | 0.696 | 0.812 | 0.306 |
| BLIP-Diffusion (zero-shot) [17] | 0.594 | 0.779 | 0.300 |
| BLIP-Diffusion (fine-tune) [17] | 0.670 | 0.805 | 0.302 |
| Ours (Lumina-mGPT [18]) | 0.671 | 0.785 | 0.314 |
Table 1: Quantitative results comparison on Dreambench. The table shows subject fidelity (DINO, CLIP-I) and prompt following (CLIP-T) scores across different models. For all three metrics, higher scores indicate better performance, with bold values highlighting the highest scores achieved.
By fine-tuning the auto-regressive model of Lumina-mGPT using this method, it outperforms Textual Inversion, Re-Imagen, and zero-shot BLIP-Diffusion in both subject fidelity (DINO and CLIP-I) and prompt following (CLIP-T). Additionally, it achieves comparable results to stable diffusion-based DreamBooth and fine-tuned BLIP-Diffusion in DINO. Notably, the method achieves the highest prompt following score among all the models listed.
These findings demonstrate that auto-regressive models can be fine-tuned to incorporate new concepts without compromising their original generation capabilities.
Visual Results: Seeing is Believing

Qualitative results showing personalized objects with re-contextualization and property modification.

Qualitative results showing personalized animals with re-contextualization and accessorization.
The re-contextualization examples demonstrate the model's ability to accurately reproduce the subject's appearance while merging it into new backgrounds. Furthermore, the model can accurately modify the color and shape properties of the subject, even in challenging cases such as "cube-shaped." This indicates that the model not only learns new concepts but also effectively decomposes and recomposes them with its prior knowledge.
In accessorization examples, the model can seamlessly integrate subjects with outfits, demonstrating its ability to understand the structure and meaning of the subject rather than merely replicating its appearance. These results validate the model's strong ability to follow prompts and maintain high subject fidelity, as reflected in the quantitative evaluation.
Digging Deeper: What Makes This Approach Effective
As noted in DreamBooth, fine-tuning all layers of a diffusion model can lead to issues of language drift and reduced output diversity. This occurs because fine-tuning a pre-trained diffusion model on a small set of images causes it to gradually forget how to generate subjects of the same class as the target subject.
However, when fine-tuning all layers of the transformer within an auto-regressive model, these issues were not observed. After fine-tuning the model with reference images using the prompt "A photo of [V] [class_name]", the model can still generate diverse and distinct images when prompted with "A photo of a [class_name]" or "A photo of a [class_name] in the jungle", showing no significant resemblance to the training images.

Preservation of class semantic priors, showing no language drift or reduced output diversity after fine-tuning.
| Method | DINO ↑ | CLIP-I ↑ | CLIP-T ↑ |
|---|---|---|---|
| Ours (Lumina-mGPT) w/o class name | 0.668 | 0.785 | 0.312 |
| Ours (Lumina-mGPT) | 0.671 | 0.785 | 0.314 |
Table 2: Comparison of subject fidelity and prompt following scores when training with and without subject class names in prompts.
The researchers investigated the impact of removing the class name in the training prompt by fine-tuning with prompts such as "A photo of [V]". The quantitative results indicate that both methods yield comparable results, with fine-tuning using the class name performing slightly better. This suggests that auto-regressive models are more robust in preserving their pre-trained knowledge, eliminating the need for including the Prior Preservation Loss during personalization.
The research also explored fine-tuning the transformer layers using LoRA with different ranks and layer configurations. Subject fidelity improves with higher LoRA ranks and more trainable layers. Although there is a trade-off between subject fidelity and prompt following, prompt following remains strong across different training configurations.
| Rank | Every N Layer |
# Trainable Parameters |
DINO ↑ | CLIP-I ↑ | CLIP-T ↑ |
|---|---|---|---|---|---|
| r=16 | N=1 | 12.6 M | 0.657 | 0.781 | 0.316 |
| N=2 | 6.3 M | 0.640 | 0.773 | 0.316 | |
| N=4 | 3.2 M | 0.630 | 0.769 | 0.319 | |
| r=64 | N=1 | 50.4 M | 0.657 | 0.778 | 0.312 |
| N=2 | 25.2 M | 0.656 | 0.777 | 0.315 | |
| N=4 | 12.6 M | 0.638 | 0.769 | 0.317 | |
| r=256 | N=1 | 201.4 M | 0.668 | 0.785 | 0.312 |
| N=2 | 100.7 M | 0.654 | 0.775 | 0.315 | |
| N=4 | 50.4 M | 0.640 | 0.772 | 0.317 | |
| Full fine-tune | 1610.6 M | 0.671 | 0.785 | 0.314 |
Table 3: Quantitative results comparison under different training configurations of Lumina-mGPT. The table compares subject fidelity and prompt following scores across different LoRA ranks r and varying number of training layers, where N denotes the interval at which trainable layers are applied.
Generally, more trainable parameters correlate with improved subject fidelity, but there are exceptions. For instance, increasing the rank or trainable parameters but training fewer layers can degrade subject fidelity. This suggests that training more layers has a greater impact on performance than purely increasing the LoRA rank or trainable parameters.
When assessing the model's performance by optimizing only the text embeddings without fine-tuning the transformer layers, the quantitative results show that subject fidelity is significantly lower.
| Method | DINO ↑ | CLIP-I ↑ | CLIP-T ↑ |
|---|---|---|---|
| Ours (Lumina-mGPT) w/o transformer layers | 0.601 | 0.754 | 0.320 |
| Ours (Lumina-mGPT) w/ transformer layers | 0.671 | 0.785 | 0.314 |
Table 4: Comparison of performance when optimizing only text embeddings versus the full two-stage approach with transformer layers.
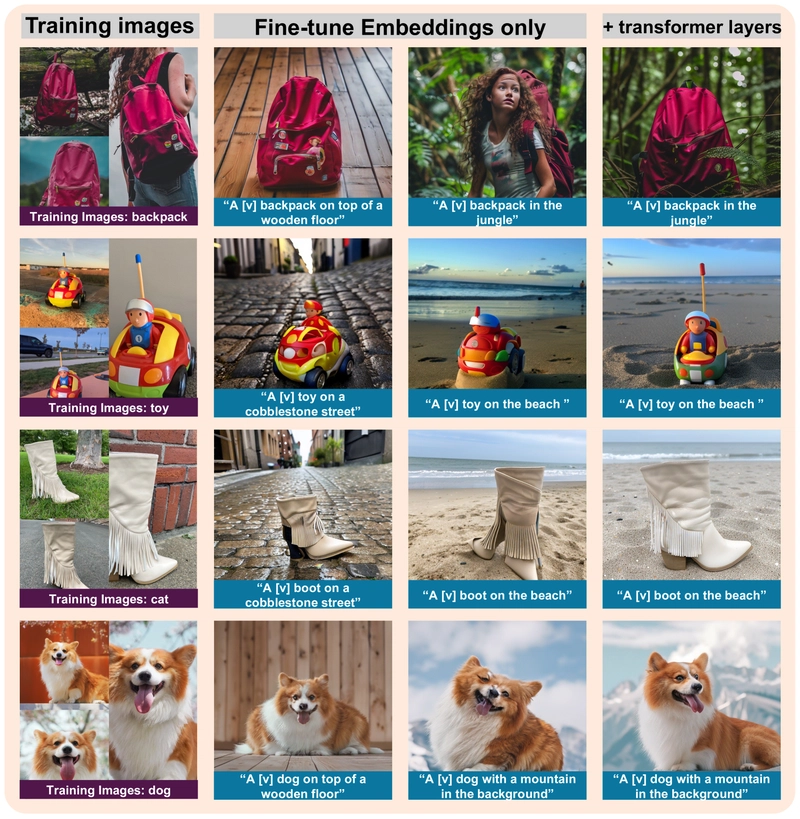
Visual comparison of fine-tuning strategies, showing the superiority of the two-stage approach.
Current Limitations: Where the Approach Falls Short
While the model demonstrates capabilities in re-contextualization, accessorization, and simple property modifications such as color and shape, it struggles with more complex scenarios requiring extensive prior knowledge or deep integration of multiple concepts.

Failure cases of various applications, showing the current limitations of the approach.
Novel view synthesis: The model struggles when tasked with generating perspectives of the specific subject it has never encountered (e.g., top, bottom, or back views). While it can extrapolate class knowledge to somewhat successfully generate top and back views, it fails to produce a correct bottom view due to overfitting to the input images.
Art renditions: The model can successfully transfer certain subjects into some artistic styles (e.g., Van Gogh), but fails with others. In pencil sketch and Chinese ink painting examples, the model recognizes the styles but misinterprets them as objects rather than applying them to the subject. This issue may stem from the token-based nature of the auto-regressive model.
Property modification: While the model performs well with simple tasks like altering color or shape, it struggles with more complex feature combinations. For example, it fails to merge features of two animals (e.g., "a dog panda" or "a dog lion"), instead generating only the second animal mentioned in the prompt.
Conclusion: Implications and Future Directions
This research demonstrates the potential of auto-regressive models for personalized image synthesis through a two-stage training strategy, first optimizing text embedding and then fine-tuning transformer layers. The approach achieves comparable subject fidelity and prompt following to state-of-the-art stable diffusion-based methods such as DreamBooth.
However, auto-regressive models are slow, taking minutes to generate images, and the fine-tuning also requires 15-20 minutes, limiting real-time applicability. Additionally, the ability to create personalized images raises ethical concerns, such as misuse for misleading content, a challenge common to all generative models.
Future work should focus on improving efficiency, addressing ethical risks, and ensuring responsible advancements in personalized generative technologies.


