








































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)







































































































































































































![Blue Archive tier list [April 2025]](https://media.pocketgamer.com/artwork/na-33404-1636469504/blue-archive-screenshot-2.jpg?#)





























.png?#)











-Baldur’s-Gate-3-The-Final-Patch---An-Animated-Short-00-03-43.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

































































































































![Apple's Foldable iPhone May Cost Between $2100 and $2300 [Rumor]](https://www.iclarified.com/images/news/97028/97028/97028-640.jpg)
![Apple Releases Public Betas of iOS 18.5, iPadOS 18.5, macOS Sequoia 15.5 [Download]](https://www.iclarified.com/images/news/97024/97024/97024-640.jpg)
![Apple to Launch In-Store Recycling Promotion Tomorrow, Up to $20 Off Accessories [Gurman]](https://www.iclarified.com/images/news/97023/97023/97023-640.jpg)
























































































































Next-Gen AI Multi-Modal RAG with Text and Image Integration
Through artificial intelligence, we experience a revolutionary change in our technology interactions because of image-text integration. Multi-Modal Retrieval-Augmented Generation (RAG) leads the transformation of AI processing by allowing it to produce responsive content from texts and images. The following blog describes multi-modal RAG by exploring its fundamental concept and importance along with its operational framework. Understanding Multi-Modal RAG The Retrieval-Augmented Generation (RAG) system offers improved AI productivity by seeking appropriate content from database resources to assist its output development. Traditional RAG models process text only, although multi-modal RAG expands their capability by handling image inputs, thus enabling the system to handle queries with text and images. With RAG technology, you can upload an old ruin image to get historical documentation about its cultural builder through a multi-conditional analysis, which delivers accurate information. This capability stems from the system’s ability to align text and visual data in a shared framework, making it possible to handle diverse inputs seamlessly. By bridging language and vision, multi-modal RAG represents a leap toward AI that mirrors human-like comprehension, where multiple senses inform understanding. How Multi-Modal RAG Functions Multi-modal RAG completes its operation with three essential steps that include retrieval, followed by processing, and ends with generation. The advanced modeling provided in each procedural step creates outputs that are logical and information-rich. Retrieval: The process starts with the retrieval of a query that may consist of text documents or images alone or combined. The system accesses knowledge provided by text documents alongside image content such as files and pictures. In CLIP (Contrastive Language-Image Pretraining), the text and visual input become integrated into a unified embedding space for effective item matching based on similarity measures. A search term of “modern furniture” enables the system to fetch articles combined with imagery of contemporary minimalist chairs. Processing: The system analyzes data that has been retrieved from the database. Natural language processing breaks down text into essential information before image examination through object detection or feature extraction, or caption generation processing. The system needs this process to comprehend both the textual context and visual information before it creates a unified view of the content. A bridge image can be processed to detect structural styles that yield accompanying text with historical information. Generation: The generative model, which frequently uses transformer technology, merges input data processing results to generate a response. In this phase, we consolidate the retrieved data through a condensed summary we formulate an answer to the presented question, or construct a story that amalgamates both information sources. The outcome has an informed quality because it draws content directly from both documents and pictures. Complex models built with large data collections enable this pipeline to perform multimodal reasoning, which exceeded human capabilities. Multi-Modal RAG Pipeline To bring multi-modal RAG to life, consider a streamlined pipeline inspired by projects like the one from AI Online Course. This setup processes a research paper PDF, pulling text and images to answer queries, using libraries like PyMuPDF for PDF extraction, OpenCV and Tesseract for image OCR, LangChain for embeddings, and OpenAI’s APIs for generation. Here’s how it works, with brief code for each step. Text and Image Extraction: Code processes a PDF, extracting text sections like abstracts or results and images like graphs. OCR converts image-based text, such as captions, into usable data. import fitz doc = fitz.open("paper.pdf") text = doc[0].get_text("text") # Extract text from first page img = doc[0].get_images()[0] img_path = "figure.png" open(img_path, "wb").write(doc.extract_image(img[0])["image"]) ocr_text = pytesseract.image_to_string(cv2.imread(img_path, 0)) Embedding and Storage: Text and images are encoded into embeddings using a model like CLIP or OpenAI’s embeddings, stored in a vector database like Chroma for fast retrieval. from langchain_openai import OpenAIEmbeddings from langchain.vectorstores import Chroma documents = [Document(page_content=text + ocr_text, metadata={"page": 1})] vector_db = Chroma.from_documents(documents, OpenAIEmbeddings()) Query Handling: A query, such as “What’s the study’s main finding?” retrieves relevant text and visuals. For images, GPT-4o might analyze figures to summarize trends. query = "What's the main finding?" docs = vector_db.similarity_search(query, k=5) context = "\n".join([doc.page_content for doc in docs]) Response Generation: A language model combines retrieved data to answer, formatti
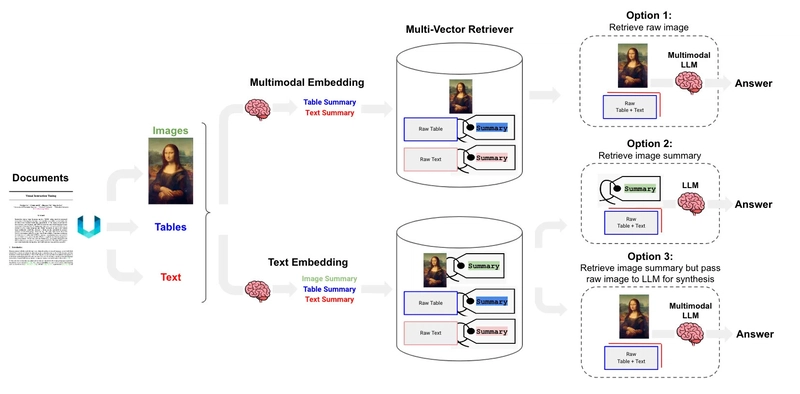
Through artificial intelligence, we experience a revolutionary change in our technology interactions because of image-text integration. Multi-Modal Retrieval-Augmented Generation (RAG) leads the transformation of AI processing by allowing it to produce responsive content from texts and images. The following blog describes multi-modal RAG by exploring its fundamental concept and importance along with its operational framework.
Understanding Multi-Modal RAG
The Retrieval-Augmented Generation (RAG) system offers improved AI productivity by seeking appropriate content from database resources to assist its output development. Traditional RAG models process text only, although multi-modal RAG expands their capability by handling image inputs, thus enabling the system to handle queries with text and images. With RAG technology, you can upload an old ruin image to get historical documentation about its cultural builder through a multi-conditional analysis, which delivers accurate information.
This capability stems from the system’s ability to align text and visual data in a shared framework, making it possible to handle diverse inputs seamlessly. By bridging language and vision, multi-modal RAG represents a leap toward AI that mirrors human-like comprehension, where multiple senses inform understanding.
How Multi-Modal RAG Functions
Multi-modal RAG completes its operation with three essential steps that include retrieval, followed by processing, and ends with generation. The advanced modeling provided in each procedural step creates outputs that are logical and information-rich.
Retrieval: The process starts with the retrieval of a query that may consist of text documents or images alone or combined. The system accesses knowledge provided by text documents alongside image content such as files and pictures. In CLIP (Contrastive Language-Image Pretraining), the text and visual input become integrated into a unified embedding space for effective item matching based on similarity measures. A search term of “modern furniture” enables the system to fetch articles combined with imagery of contemporary minimalist chairs.
Processing: The system analyzes data that has been retrieved from the database. Natural language processing breaks down text into essential information before image examination through object detection or feature extraction, or caption generation processing. The system needs this process to comprehend both the textual context and visual information before it creates a unified view of the content. A bridge image can be processed to detect structural styles that yield accompanying text with historical information.
Generation: The generative model, which frequently uses transformer technology, merges input data processing results to generate a response. In this phase, we consolidate the retrieved data through a condensed summary we formulate an answer to the presented question, or construct a story that amalgamates both information sources. The outcome has an informed quality because it draws content directly from both documents and pictures.
Complex models built with large data collections enable this pipeline to perform multimodal reasoning, which exceeded human capabilities.
Multi-Modal RAG Pipeline
To bring multi-modal RAG to life, consider a streamlined pipeline inspired by projects like the one from AI Online Course. This setup processes a research paper PDF, pulling text and images to answer queries, using libraries like PyMuPDF for PDF extraction, OpenCV and Tesseract for image OCR, LangChain for embeddings, and OpenAI’s APIs for generation. Here’s how it works, with brief code for each step.
Text and Image Extraction: Code processes a PDF, extracting text sections like abstracts or results and images like graphs. OCR converts image-based text, such as captions, into usable data.
import fitz
doc = fitz.open("paper.pdf")
text = doc[0].get_text("text") # Extract text from first page
img = doc[0].get_images()[0]
img_path = "figure.png"
open(img_path, "wb").write(doc.extract_image(img[0])["image"])
ocr_text = pytesseract.image_to_string(cv2.imread(img_path, 0))
Embedding and Storage: Text and images are encoded into embeddings using a model like CLIP or OpenAI’s embeddings, stored in a vector database like Chroma for fast retrieval.
from langchain_openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
documents = [Document(page_content=text + ocr_text, metadata={"page": 1})]
vector_db = Chroma.from_documents(documents, OpenAIEmbeddings())
Query Handling: A query, such as “What’s the study’s main finding?” retrieves relevant text and visuals. For images, GPT-4o might analyze figures to summarize trends.
query = "What's the main finding?"
docs = vector_db.similarity_search(query, k=5)
context = "\n".join([doc.page_content for doc in docs])
Response Generation: A language model combines retrieved data to answer, formatting insights into clear outputs enriched by both modalities.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o")
response = llm.invoke([{"role": "user", "content": f"Answer: {query}\nContext: {context}"}]).content
Note: These snippets are simplified. Real systems need robust error handling, actual file paths, and API keys. This pipeline shows how multi-modal RAG handles academic papers, blending text and visuals to make complex information accessible.
Challenges and Future Directions
Multi-modal RAG faces hurdles that guide its evolution:
- Data Alignment: The process of matching text with images gets complicated when dealing with unclear data, so advanced methods must be developed.
- Resource Demands: The combination processing of different modalities requires substantial resource consumption, which restricts some application use cases.
- Bias Risks: The processing models tend to reflect the biases present in datasets, which requires specific attention to cultural representation while designing collections.
- Scalability: The creation of extensive specialized knowledge bases attains both specificity and importance for particular domains.
Future advances, like model compression or enhanced cross-modal reasoning, could make multi-modal RAG lighter and more inclusive, expanding its reach to devices and domains.
Ethical Considerations
The continuing expansion of multi-modal RAG creates new ethical dilemmas to address. Strategies to protect privacy must be developed when users upload their images to platforms. What methods can we implement to stop unauthorized creation of misleading content? Explanations about data processing establish trust between humans and systems. Safety measures such as bias detection systems together with content moderation practices guarantee good usage practices while ensuring artificial intelligence maintains alignment with public moral values.
Conclusion
The innovative Multi-modal Retrieval-Augmented Generation system takes artificial intelligence beyond mere intelligence by uniting text and images to create highly intuitive systems. The technology integrates human sensorial combination methods into its operations to turn complex content into straightforward insights, which enable innovation in education and healthcare research, and many other domains. This ongoing evolution of the technology demonstrates growing potential for human learning and work, and creation processes, which signal AI's capacity to fully grasp our world's richness.
Build Multi-Modal RAG AI Projects from scratch
Check out this hands-on project to see it in action
Multi-Modal Retrieval-Augmented Generation (RAG) with Text and Image Processing
Start implementing contextual retrieval today and take your AI applications to the next level!



