







































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)
































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)








































































































(1).jpg?#)
































_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
















































































































![New Apple iPad mini 7 On Sale for $399! [Lowest Price Ever]](https://www.iclarified.com/images/news/96096/96096/96096-640.jpg)
![Apple to Split iPhone Launches Across Fall and Spring in Major Shakeup [Report]](https://www.iclarified.com/images/news/97211/97211/97211-640.jpg)
![Apple to Move Camera to Top Left, Hide Face ID Under Display in iPhone 18 Pro Redesign [Report]](https://www.iclarified.com/images/news/97212/97212/97212-640.jpg)
![Apple Developing Battery Case for iPhone 17 Air Amid Battery Life Concerns [Report]](https://www.iclarified.com/images/news/97208/97208/97208-640.jpg)
























































































Growing the Tree: Multi-Agent LLMs Meet RAG, Vector Search, and Goal-Oriented Thinking - Part 2
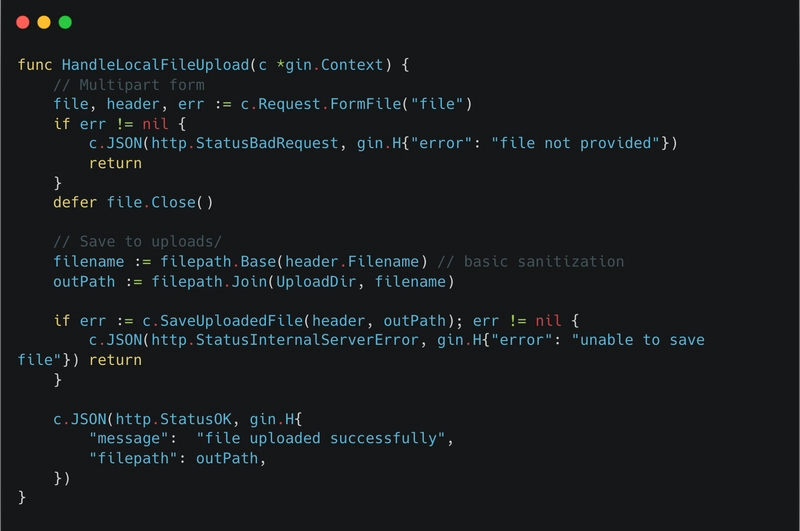
Simulating Better Decision-Making in Insurance and Care Management Through RAG In the Part 1 post, I walked through how I built a CLI that runs multi-agent conversations in a social media (Reddit-inspired) conversation thread style. Each persona responds, builds off the others, and together they simulate a deeper discussion. It worked, but it had limits. The agents lacked memory. They didn't have direction. And they couldn’t access supporting documents. As I said in the previous post, I made some updates to incorporate improvements. This post covers the updates I have made: Added a goal round. Each agent can now reference external files (support for URLs coming next). Integrated Qdrant and OpenAI embeddings for retrieval-augmented generation (RAG). Started scoring how well responses relate to retrieved context. Showcasing the decision goal round with some real business use cases (Auto Insurance Quote and developing a Care Plan). More Flexible Persona Design In our earlier version, personas were defined directly inside the CLI using --persona flags. That worked, but it got messy quickly. With this update, I have moved persona definitions into a standalone personas.json file. This change gave us a lot more flexibility: Unlimited(within reason) personas. Each persona can now define a regular_prompt, goal_prompt, and ref_files. We can assign unique files for each persona to ground their responses. It keeps the CLI clean while making persona behaviors extensible. I have also introduced a schema file (persona.schema.json) to validate each persona object. This schema ensures that required fields are present, and that file references are structured consistently. That structure not only helps us catch errors early, but also gives us a stable contract to build tooling, validations, and even a visual persona builder down the line. This design opens up new paths for evolving the system: dynamic persona loading, fine-tuned goal routing, optimized routes for each persona, or even persona specialization per domain. [ { "name": "Surgeon", "llm": "ChatGPT", "model": "gpt-3.5-turbo", "engagement": 1, "references": [ { "type": "file", "value": "./ref-files/caremgmt-hip/hip-replacement-recovery.md" }, { "type": "file", "value": "./ref-files/caremgmt-hip/patient-background.md" } ], "regular_prompt": "You are the orthopedic surgeon who performed the hip replacement. Offer clinical insights on the patient's recovery trajectory, highlight any red flags to watch for, and ensure the physical milestones are on track.", "goal_prompt": "Summarize your final post-operative assessment for Mrs. Carter's hip replacement recovery. Highlight red flags, clearance criteria for outpatient PT, and any clinical restrictions that must be followed." }, { "name": "Care Manager", "llm": "ChatGPT", "model": "gpt-3.5-turbo", "engagement": 1, "references": [ { "type": "vector:qdrant", "value": "collection=care_guidelines,product=care" }, { "type": "file", "value": "./ref-files/caremgmt-hip/patient-background.md" } ], "regular_prompt": "You are a care management specialist assigned to Mrs. Carter. Evaluate discharge readiness, ensure safe transitions, and recommend support services such as PT, home health, or equipment based on her environment and needs.", "goal_prompt": "Submit a structured care coordination plan for Mrs. Carter. Include: (1) home health referrals, (2) safety enhancements, (3) follow-up schedule, and (4) caregiver instructions." }, { "name": "Michael (Son)", "llm": "ChatGPT", "model": "gpt-3.5-turbo", "engagement": 1, "references": [ { "type": "file", "value": "./ref-files/caremgmt-hip/patient-background.md" } ], "regular_prompt": "You are Michael, Mrs. Carter’s son. Express family concerns, ask questions about her safety and comfort, and advocate for what would help her most during recovery at home.", "goal_prompt": "List your top 2–3 concerns for your mother's recovery and what kind of help you hope the care team can provide. Be specific about her home environment and daily challenges." } ] Adding a Goal Round Conversations need direction. Without it, threads drift. I have introduced a goal round to ground the discussion. It's simple: before any agents speak, the system sets a clear goal for the conversation. That goal gets injected into the first message and referenced in later turns. The system now supports structured goal types like decision, summary, consensus, reflection, and rebuttal. These give the conversation a clear intent for its final round. In this update, I have implemented the decision goal, where each agent weighs the discussion and makes a call. This structure helps tie the conversation together and surface final judgments in a consistent, directed way. This change alone made the threads feel more cohesive. Instead of rambl

Simulating Better Decision-Making in Insurance and Care Management Through RAG
In the Part 1 post, I walked through how I built a CLI that runs multi-agent conversations in a social media (Reddit-inspired) conversation thread style. Each persona responds, builds off the others, and together they simulate a deeper discussion. It worked, but it had limits. The agents lacked memory. They didn't have direction. And they couldn’t access supporting documents. As I said in the previous post, I made some updates to incorporate improvements.
This post covers the updates I have made:
- Added a goal round.
- Each agent can now reference external files (support for URLs coming next).
- Integrated Qdrant and OpenAI embeddings for retrieval-augmented generation (RAG).
- Started scoring how well responses relate to retrieved context.
- Showcasing the decision goal round with some real business use cases (Auto Insurance Quote and developing a Care Plan).
More Flexible Persona Design
In our earlier version, personas were defined directly inside the CLI using --persona flags. That worked, but it got messy quickly. With this update, I have moved persona definitions into a standalone personas.json file.
This change gave us a lot more flexibility:
- Unlimited(within reason) personas.
- Each persona can now define a regular_prompt, goal_prompt, and ref_files.
- We can assign unique files for each persona to ground their responses.
- It keeps the CLI clean while making persona behaviors extensible.
I have also introduced a schema file (persona.schema.json) to validate each persona object. This schema ensures that required fields are present, and that file references are structured consistently. That structure not only helps us catch errors early, but also gives us a stable contract to build tooling, validations, and even a visual persona builder down the line.
This design opens up new paths for evolving the system: dynamic persona loading, fine-tuned goal routing, optimized routes for each persona, or even persona specialization per domain.
[
{
"name": "Surgeon",
"llm": "ChatGPT",
"model": "gpt-3.5-turbo",
"engagement": 1,
"references": [
{ "type": "file", "value": "./ref-files/caremgmt-hip/hip-replacement-recovery.md" },
{ "type": "file", "value": "./ref-files/caremgmt-hip/patient-background.md" }
],
"regular_prompt": "You are the orthopedic surgeon who performed the hip replacement. Offer clinical insights on the patient's recovery trajectory, highlight any red flags to watch for, and ensure the physical milestones are on track.",
"goal_prompt": "Summarize your final post-operative assessment for Mrs. Carter's hip replacement recovery. Highlight red flags, clearance criteria for outpatient PT, and any clinical restrictions that must be followed."
},
{
"name": "Care Manager",
"llm": "ChatGPT",
"model": "gpt-3.5-turbo",
"engagement": 1,
"references": [
{ "type": "vector:qdrant",
"value": "collection=care_guidelines,product=care" },
{ "type": "file", "value": "./ref-files/caremgmt-hip/patient-background.md" }
],
"regular_prompt": "You are a care management specialist assigned to Mrs. Carter. Evaluate discharge readiness, ensure safe transitions, and recommend support services such as PT, home health, or equipment based on her environment and needs.",
"goal_prompt": "Submit a structured care coordination plan for Mrs. Carter. Include: (1) home health referrals, (2) safety enhancements, (3) follow-up schedule, and (4) caregiver instructions."
},
{
"name": "Michael (Son)",
"llm": "ChatGPT",
"model": "gpt-3.5-turbo",
"engagement": 1,
"references": [
{ "type": "file", "value": "./ref-files/caremgmt-hip/patient-background.md" }
],
"regular_prompt": "You are Michael, Mrs. Carter’s son. Express family concerns, ask questions about her safety and comfort, and advocate for what would help her most during recovery at home.",
"goal_prompt": "List your top 2–3 concerns for your mother's recovery and what kind of help you hope the care team can provide. Be specific about her home environment and daily challenges."
}
]
Adding a Goal Round
Conversations need direction. Without it, threads drift.
I have introduced a goal round to ground the discussion. It's simple: before any agents speak, the system sets a clear goal for the conversation. That goal gets injected into the first message and referenced in later turns.
The system now supports structured goal types like decision, summary, consensus, reflection, and rebuttal. These give the conversation a clear intent for its final round. In this update, I have implemented the decision goal, where each agent weighs the discussion and makes a call. This structure helps tie the conversation together and surface final judgments in a consistent, directed way.
This change alone made the threads feel more cohesive. Instead of rambling or contradicting each other, the agents start circling the same target.
File Support for Personas
Next, I gave agents some superpowers—aka access to external files. Now, each persona can have a references field that lists one or more local files. Those files get summarized and added into that agent's system prompt.
In this iteration, it's straightforward. The files are short and injected as-is. At this point, I haven’t implemented chunking or RAG. But even with basic support, it unlocked new use cases:
- Underwriters referencing a rate table
- Care planners reading recovery guidelines
The point is: agents can now ground their reasoning over real documents, not just a one-shot prompt.
Combined with the new persona file format, this setup lets each agent control its own references independently. We can fine-tune prompts and contextual grounding per persona, which is critical for simulating real-world expertise.
And as we evolve the system—adding chunked documents, URL-based sources, or dynamic embedding refreshes—this design scales naturally without breaking the prompt pipeline.
Retrieval-Augmented Generation (RAG) with Qdrant
Once file support worked, I took the next iteration further. Instead of shoving full files into prompts, I started embedding content and retrieving only what’s relevant.
This can be broken down into three stages
Tool Selection: Embedding and Vector DB
Each chunk is embedded using OpenAI’s text-embedding-3-small. I evaluated a few options:
To keep things simple and reduce friction, I went with OpenAI. I am already using OpenAI APIs, so this choice aligned with my stack. The embeddings are fast, cost-effective, and accurate enough for what I needed. This let me move faster without spinning up additional infrastructure.
As for the vector store, here’s a quick comparison of Open Source self-hosting options:

I ultimately chose Qdrant. It hit the right balance for my needs: easy to host and integrate, flexible enough for semantic search, and well-documented. It supports multiple embedding types (I plan to use video/image embedding in future) and matched my goal of keeping iteration speed high without sacrificing performance.
Qdrant Setup: Embedding and Upload
To embed and load documents, I run a containerized process that uses our upload_to_qdrant.py script.
Example command:
docker run --rm \
--add-host=host.docker.internal:host-gateway \
-e OPENAI_API_KEY=$OPENAI_API_KEY \
-e QDRANT_HOST=host.docker.internal \
-v "${PWD}/vector-setup:/app" \
multillm-tot-vector-setup \
python /app/upload_to_qdrant.py \
--folder /app/caremgmt-hip \
--manifest /app/hello-care-guidelines.json \
--collection care_guidelines
This script reads a manifest file, embeds Markdown documents, and uploads them to a named Qdrant collection with all metadata (title, tags, filename, etc.).
Retrieval Flow During Conversation
- When a persona is about to respond, we embed the current message (and optionally, the goal).
- We query Qdrant to retrieve the top-matching chunks.
- Retrieved chunks are deduplicated by filename and section title to avoid redundant context.
- The final set of unique chunks is injected into the agent's system prompt.
This gives us tight, focused prompts that still bring in meaningful external knowledge, without blowing past token limits.
This setup let us scale cleanly from static file injection to dynamic retrieval across large corpora.
RAG Beyond Vector Search
It’s worth noting that while RAG often gets reduced to “just vector search,” a full retrieval-augmented system touches multiple layers of infrastructure:
- Vector DB — for semantic similarity search (e.g., Qdrant)
- Search DB — for keyword/hybrid retrieval (e.g., Elasticsearch)
- Document DB — for managing source documents, versions, and metadata
- Graph DB — for modeling relationships and entity linkages; believed to be a key frontier for improving reasoning and recall
RAG doesn’t have to use all of these at once, but thoughtful integration of more than one often leads to better relevance, traceability, and depth. As these systems matures, this kind of architecture is something we should keep in mind.
Introducing a RAG Score
To understand how well each agent is using the context, I started experimenting with a RAG score. It's not fancy. Right now, I am just checking semantic similarity between the agent's response and the retrieved chunks.
The idea is to track alignment. Are they using what was retrieved? Are they staying on topic? This score isn’t exposed to the agents, but it's useful for me as a debugging and tuning tool.
Down the line, this could be used to drive filtering, voting, or reward signals.
Real-World Use Cases
I tested all this on two business use cases. Both were grounded in actual vector-embedded files that agents used to retrieve context. The inputs were curated, and the outputs were near-perfect. The real world is never that simple. Creating the knowledge base itself is a long, arduous task. And that’s where most of the work lies. Fortunately, with LLMs, it's now easier than ever to build and enrich that knowledge base.
1️⃣Auto Insurance Underwriting
Prompt
You are reviewing an auto insurance application. Make a timely decision on whether to approve with terms or decline coverage.
CLI Command
python main.py \
--prompt "You are reviewing an auto insurance application. Make a timely decision on whether to approve with terms or decline coverage." \
--rounds 2 \
--personas-file './input/underwriting-auto/insurance-personas.json' \
--output html \
--save-to './output/underwriting-auto/submission-discussion.html'
--goal-round decision

I ran a conversation where agents assessed risk for an auto insurance policy. Three agents participated: Insurance Agent, Underwriter, and Actuary.
- The Insurance Agent had access to the submission application (submission-application.md).
- The Actuary used a static rate table (underwriting-rate-table.md) and underwriting guidelines (underwriting-guidelines.md).
- The Underwriter had access to all of the above plus the applicant's claims history (loss-history.md) and underwriting decision workflow (vector embedding).
Files used for RAG were embedded via Qdrant, and the persona prompts were grounded in their respective views. This made it possible to have a multi-perspective evaluation of the same submission with clear logic, tradeoffs, and pricing risk assessments.
2️⃣Care Planning
Prompt
You are developing a personalized care plan for Mrs. Elaine Carter, a 62-year-old woman recovering from a total left hip replacement. Collaborate across clinical, care coordination, and family perspectives to ensure a safe recovery, appropriate support services, and readiness for outpatient transition.
CLI Command
python main.py \
--prompt "You are developing a personalized care plan for Mrs. Elaine Carter, a 62-year-old woman recovering from a total left hip replacement. Collaborate across clinical, care coordination, and family perspectives to ensure a safe recovery, appropriate support services, and readiness for outpatient transition." \
--rounds 2 \
--personas-file './input/caremgmt-hip/care-personas.json' \
--output html \
--save-to './output/caremgmt-hip/care-plan-discussion.html'
--goal-round decision

I created a discussion around a 62-year-old woman recovering from hip replacement surgery (Mrs. Carter). The setup included a Surgeon, a Care Manager, and the patient’s son (Michael).
- The Surgeon referenced a clinical recovery timeline (hip-replacement-recovery.md).
- The Care Manager retrieved content from a vectorized care guideline (care-guidelines.md) and a home safety checklist (home-environment-checklist.md).
- Michael (the son) responded based on family-provided background info (patient-background.md).
The responses were coordinated, personalized, and relevant. They showed how each persona could bring its expertise forward while grounding its reasoning in specific content. This approach supports everything from planning safe discharge protocols to modeling risk acceptance for a new policy.
As you can see in the screenshot, the agent made a decision, offered supporting recommendations, and explained the rationale, in structured JSON format. In real-world settings like underwriting or care planning, this kind of assistive intelligence could save valuable time for teams constrained by human capacity.
It’s not about replacing knowledge workers, it's about surfacing relevant context and generating suggestions before the case is even reviewed. Think of it as a recommendation engine: one that boosts productivity, speeds up decision cycles, and creates a more consistent starting point for complex decisions.
Both of these showed us this setup isn't just a hello-world implementation of Agentic RAG. It's a flexible system for making decisions with embedded context and specialized roles.
What's Next
Here’s what I am looking at next:
- Chunking strategies for longer documents
- Incorporating external URLs
- CAG(Cache Augumented Retrieval) for less frequently changing sources
- Voting, route pruning, and exploration strategies for agents
- Mindmap or workflow views for agent threads
- Semantic grouping of documents
- Real-time updates to vector embeddings
If the first version was about simulating conversation, this version is about adding memory, purpose, and context. It’s no longer just talk. Now, the tree can think



