








































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)





































































































(1).jpg?#)

































_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)









































































































![Apple to Split iPhone Launches Across Fall and Spring in Major Shakeup [Report]](https://www.iclarified.com/images/news/97211/97211/97211-640.jpg)
![Apple to Move Camera to Top Left, Hide Face ID Under Display in iPhone 18 Pro Redesign [Report]](https://www.iclarified.com/images/news/97212/97212/97212-640.jpg)
![Apple Developing Battery Case for iPhone 17 Air Amid Battery Life Concerns [Report]](https://www.iclarified.com/images/news/97208/97208/97208-640.jpg)
![AirPods 4 On Sale for $99 [Lowest Price Ever]](https://www.iclarified.com/images/news/97206/97206/97206-640.jpg)





























![[Updated] Samsung’s 65-inch 4K Smart TV Just Crashed to $299 — That’s Cheaper Than an iPad](https://www.androidheadlines.com/wp-content/uploads/2025/05/samsung-du7200.jpg)






























































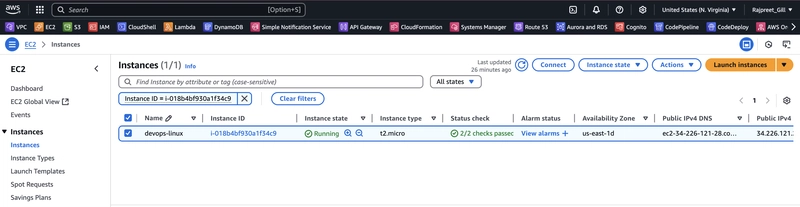
From Zero to GenAI Cluster: Scalable Local LLMs with Docker, Kubernetes, and GPU Scheduling
A practical guide to deploying fast, private, and production-ready large language models with vLLM, Ollama, and Kubernetes-native orchestration. Build your own scalable GenAI cluster with Docker, Kubernetes, and GPU scheduling for a fully private, production-ready LLM setup. Prerequisites Before we begin, ensure your system meets the following requirements: A Kubernetes cluster with GPU-enabled nodes (e.g., via GKE, AKS, or bare-metal) The NVIDIA device plugin installed on the cluster Helm CLI installed and configured Docker CLI and access to a GPU-compatible runtime (e.g., nvidia-docker2) Introduction Local LLMs are no longer a research luxury, they're a production need. But deploying them at scale, with GPU access, container orchestration, and real-time monitoring? That’s still murky territory for many. In this article, I’ll walk you through how I built a fully operational GenAI cluster using Docker, Kubernetes, and GPU scheduling. It serves powerful language models like vLLM, Ollama, or HuggingFace TGI. We’ll make it observable with Prometheus and Grafana, and ready to scale when the real load hits. This isn’t just another tutorial. It’s a battle-tested, experience-backed blueprint for real-world AI infrastructure, written for developers and DevOps engineers pushing the boundaries of what GenAI can do. Why Local/Private LLMs Matter Many teams today are realizing that hosted APIs like OpenAI and Anthropic, while convenient, come with serious trade-offs: Cost grows fast when usage scales Sensitive data can't always be sent to third-party clouds Customization is limited to what the API provider allows Latency becomes a bottleneck in low-connectivity environments Self-hosting LLMs means freedom, control, and flexibility. But only if you know how to do it right. What We'll Build We’ll deploy a production-grade Kubernetes cluster featuring: vLLM / Ollama / TGI model server containers GPU scheduling and node affinity Ingress with HTTPS via NGINX Autoscaling using HPA or KEDA Prometheus + Grafana for real-time insights Declarative infrastructure using Helm or plain YAML Architecture Overview Figure: High-level architecture of a scalable GenAI Cluster using Docker, Kubernetes, and GPU scheduling. This modular, observable cluster gives you full control over your LLM infrastructure, without vendor lock-in. Step 1: Dockerizing the Model Server Let’s start small: a single Docker container that wraps a model server like vLLM. # Dockerfile.vllm FROM nvidia/cuda:12.2.0-base-ubuntu20.04 RUN apt update && apt install -y git python3 python3-pip RUN pip install vllm torch transformers WORKDIR /app COPY start.sh ./ CMD ["bash", "start.sh"] start.sh: #!/bin/bash python3 -m vllm.entrypoints.openai.api_server --model facebook/opt-1.3b --port 8000 Then, build your container: docker build -f Dockerfile.vllm -t vllm-server:v0.1 . You can also use Ollama if you prefer pre-packaged models and a lower barrier to entry. vLLM is recommended for higher throughput and OpenAI-compatible APIs. This is your first step toward building a modular, GPU-ready inference system. Step 2: Kubernetes Deployment with GPU Scheduling apiVersion: apps/v1 kind: Deployment metadata: name: vllm-deployment spec: replicas: 1 selector: matchLabels: app: vllm template: metadata: labels: app: vllm spec: containers: - name: vllm image: vllm-server:v0.1 resources: limits: nvidia.com/gpu: 1 ports: - containerPort: 8000 nodeSelector: kubernetes.io/role: gpu tolerations: - key: "nvidia.com/gpu" operator: "Exists" effect: "NoSchedule" And here’s the corresponding Service definition: apiVersion: v1 kind: Service metadata: name: vllm-service spec: selector: app: vllm ports: - protocol: TCP port: 8000 targetPort: 8000 This exposes your model server inside the cluster. Step 3: Ingress and Load Balancing Install NGINX Ingress Controller: helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx helm install nginx ingress-nginx/ingress-nginx Then configure ingress: apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: vllm-ingress spec: rules: - host: vllm.local http: paths: - path: / pathType: Prefix backend: service: name: vllm-service port: number: 8000 Update your DNS or /etc/hosts to route vllm.local to your cluster. Step 4: Autoscaling with KEDA (Optional) helm repo add kedacore https://kedacore.github.io/charts helm install keda kedacore/keda With KEDA, you can scale your LLM pods based on GPU utilization, HTTP traffic, or even Kafka topic lag. Step 5: Monitoring with Prometheus + Grafana Install full-stack observability: helm repo add pr
A practical guide to deploying fast, private, and production-ready large language models with vLLM, Ollama, and Kubernetes-native orchestration. Build your own scalable GenAI cluster with Docker, Kubernetes, and GPU scheduling for a fully private, production-ready LLM setup.
Prerequisites
Before we begin, ensure your system meets the following requirements:
- A Kubernetes cluster with GPU-enabled nodes (e.g., via GKE, AKS, or bare-metal)
- The NVIDIA device plugin installed on the cluster
- Helm CLI installed and configured
- Docker CLI and access to a GPU-compatible runtime (e.g.,
nvidia-docker2)
Introduction
Local LLMs are no longer a research luxury, they're a production need. But deploying them at scale, with GPU access, container orchestration, and real-time monitoring? That’s still murky territory for many.
In this article, I’ll walk you through how I built a fully operational GenAI cluster using Docker, Kubernetes, and GPU scheduling. It serves powerful language models like vLLM, Ollama, or HuggingFace TGI. We’ll make it observable with Prometheus and Grafana, and ready to scale when the real load hits.
This isn’t just another tutorial. It’s a battle-tested, experience-backed blueprint for real-world AI infrastructure, written for developers and DevOps engineers pushing the boundaries of what GenAI can do.
Why Local/Private LLMs Matter
Many teams today are realizing that hosted APIs like OpenAI and Anthropic, while convenient, come with serious trade-offs:
- Cost grows fast when usage scales
- Sensitive data can't always be sent to third-party clouds
- Customization is limited to what the API provider allows
- Latency becomes a bottleneck in low-connectivity environments
Self-hosting LLMs means freedom, control, and flexibility. But only if you know how to do it right.
What We'll Build
We’ll deploy a production-grade Kubernetes cluster featuring:
- vLLM / Ollama / TGI model server containers
- GPU scheduling and node affinity
- Ingress with HTTPS via NGINX
- Autoscaling using HPA or KEDA
- Prometheus + Grafana for real-time insights
- Declarative infrastructure using Helm or plain YAML
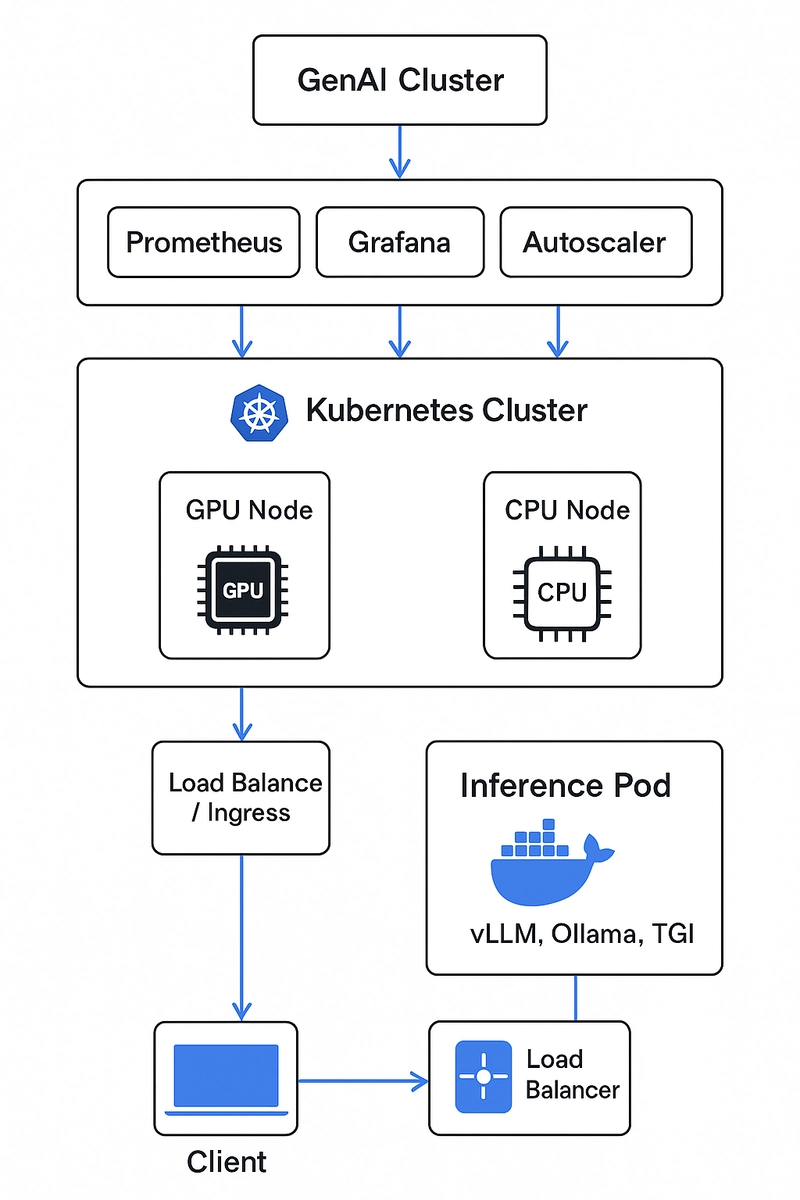
Architecture Overview
Figure: High-level architecture of a scalable GenAI Cluster using Docker, Kubernetes, and GPU scheduling.
This modular, observable cluster gives you full control over your LLM infrastructure, without vendor lock-in.
Step 1: Dockerizing the Model Server
Let’s start small: a single Docker container that wraps a model server like vLLM.
# Dockerfile.vllm
FROM nvidia/cuda:12.2.0-base-ubuntu20.04
RUN apt update && apt install -y git python3 python3-pip
RUN pip install vllm torch transformers
WORKDIR /app
COPY start.sh ./
CMD ["bash", "start.sh"]
start.sh:
#!/bin/bash
python3 -m vllm.entrypoints.openai.api_server --model facebook/opt-1.3b --port 8000
Then, build your container:
docker build -f Dockerfile.vllm -t vllm-server:v0.1 .
You can also use Ollama if you prefer pre-packaged models and a lower barrier to entry. vLLM is recommended for higher throughput and OpenAI-compatible APIs.
This is your first step toward building a modular, GPU-ready inference system.
Step 2: Kubernetes Deployment with GPU Scheduling
apiVersion: apps/v1
kind: Deployment
metadata:
name: vllm-deployment
spec:
replicas: 1
selector:
matchLabels:
app: vllm
template:
metadata:
labels:
app: vllm
spec:
containers:
- name: vllm
image: vllm-server:v0.1
resources:
limits:
nvidia.com/gpu: 1
ports:
- containerPort: 8000
nodeSelector:
kubernetes.io/role: gpu
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
And here’s the corresponding Service definition:
apiVersion: v1
kind: Service
metadata:
name: vllm-service
spec:
selector:
app: vllm
ports:
- protocol: TCP
port: 8000
targetPort: 8000
This exposes your model server inside the cluster.
Step 3: Ingress and Load Balancing
Install NGINX Ingress Controller:
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm install nginx ingress-nginx/ingress-nginx
Then configure ingress:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: vllm-ingress
spec:
rules:
- host: vllm.local
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: vllm-service
port:
number: 8000
Update your DNS or /etc/hosts to route vllm.local to your cluster.
Step 4: Autoscaling with KEDA (Optional)
helm repo add kedacore https://kedacore.github.io/charts
helm install keda kedacore/keda
With KEDA, you can scale your LLM pods based on GPU utilization, HTTP traffic, or even Kafka topic lag.
Step 5: Monitoring with Prometheus + Grafana
Install full-stack observability:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm install monitoring prometheus-community/kube-prometheus-stack
Expose a /metrics endpoint from your container.
from prometheus_client import start_http_server, Summary
import time
REQUEST_TIME = Summary('request_processing_seconds', 'Time spent processing request')
@REQUEST_TIME.time()
def process_request():
time.sleep(1)
if __name__ == '__main__':
start_http_server(8001)
while True:
process_request()
Or use GPU exporters like dcgm-exporter. Grafana will pull all this into beautiful dashboards.
Step 6: Optional Components
- Vector DB: Qdrant, Weaviate, or Chroma
- Auth Gateway: Add OAuth2 Proxy or Istio
- LangServe or FastAPI: Wrap your model with an API server or LangChain interface
- Persistent Volumes / Object Store: Save fine-tuned models using PVCs or MinIO
Final Thoughts
This isn’t just code. It’s the story of how I learned to stitch together powerful AI infrastructure from open-source tools and make it reliable enough for real-world teams to trust.
Docker gave me modularity. Kubernetes gave me orchestration. GPUs gave me the muscle.
Put together, they gave me something every AI builder wants: freedom.
If you're tired of vendor lock-in and ready to roll up your sleeves, this cluster is your launchpad.
This is just the beginning. Start building your GenAI infrastructure today and take control of your AI stack. Share your progress, contribute to the community, and let’s push the boundaries of what’s possible together.
See you at the edge!


