![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)














































































































































































































































































































































































![Google Home app fixes bug that repeatedly asked to ‘Set up Nest Cam features’ for Nest Hub Max [U]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2022/08/youtube-premium-music-nest-hub-max.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)

















































![Epic Games Wins Major Victory as Apple is Ordered to Comply With App Store Anti-Steering Injunction [Updated]](https://images.macrumors.com/t/Z4nU2dRocDnr4NPvf-sGNedmPGA=/2250x/article-new/2022/01/iOS-App-Store-General-Feature-JoeBlue.jpg)




















































DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
選定理由 中国科学院ソフトウェア研究所とWeChat AI研究チームの共同研究。 Paper: https://arxiv.org/abs/2502.01142 Code:N/A blog: https://x.gd/wTnkm https://zenn.dev/ren_ren_tnk/articles/775d6050e0cf4d 概要 【社会課題】 search-o1 と同じ 【技術課題】 従来のRAG手法ではRetriever(検索器)とGenerator(生成器)が独立に設計・最適化されていることにより、連携が不十分になり最終的な応答の品質や効率の課題を生んでいた。 【提案】 RetrieverとGeneratorが統一的な枠組みで最適化できるEnd2End な新しいRAGを提案。 ・検索強化推論(検索+推論の複合的ワークフロー)をマルコフ決定過程(MDP)として定式化し、最適な行動(検索するかどうか)を逐次選択。 ・問題を段階的に分解しながら検索と推論を繰り返す手法を導入。 ・各ステップで生成されるサブクエリに基づいて外部知識を取り込み、次のステップに活用。 ・Retrieval Narrative + Atomic Decisions Retrieval Narrative: すでに獲得している内部知識に基づき、文脈に沿ったサブクエリを生成。Atomic Decision: 各ステップで「検索する」or「内部知識だけで推論する」を判断。 【効果】 内部知識と外部知識の使い分けによりハルシネーションが抑制された結果、従来手法より21.99%の精度向上を実現した。無駄な検索を減らし必要なタイミングでのみ情報取得をすることで、計算・リソースの効率も改善した。 DeepRAG 図2はDeepRAGの全体像であり、この仕組みでRetrieval Narrative(クエリ分解) と atomic decision(検索するかしないかの判断)を行う。 3.1 Overview of the MDP Modeling DeepRAGでは、検索強化推論のプロセスを以下の4つの要素からなるMDPとしてモデル化する: 状態(States, S) 各ステップにおける状態は、元のクエリとそれまでのサブクエリとその応答の履歴 (q1,r1),…,(qt,rt)(q_1, r_1), \ldots, (q_t, r_t)(q1,r1),…,(qt,rt) で構成される。 行動(Actions, A) 各ステップでの行動 at+1a_{t+1}at+1 は、以下の2つの行動から成る: 終了判定(Termination Decision): 次のサブクエリ qt+1q_{t+1}qt+1 を生成するか、最終的な回答 ooo を出力してプロセスを終了するかを決定。 検索判定(Atomic Decision): 次のサブクエリ qt+1q_{t+1}qt+1 に対して、外部知識を取得する(retrieve)か、内部のパラメトリック知識に依存する(parametric)かを決定。 遷移(Transitions, P): 行動 at+1a_{t+1}at+1 を実行し、状態は st+1s_{t+1}st+1 に更新。 終了判定が「terminate」の場合、最終回答 ooo を生成し終了 終了判定が「continue」の場合、次のサブクエリ qt+1q_{t+1}qt+1 を生成 検索判定が「retrieve」の場合、外部知識を取得し中間応答を生成。 検索判定が「parametric」の場合、内部知識に基づいて中間応答を生成。 報酬(Rewards, R): 最終的な回答 ooo を生成した後、報酬関数 RRR は、回答の正確性と検索コストに基づいて評価されます。 正確な回答には正の報酬が与えられ、不正確な回答や不要な検索にはペナルティが課される。 3.2 Binary Tree Search, 3.3 Imitation Learning 上記のようなプロンプトを用いて質問文をサブクエリに分解するRetrieval Narrativeを実施する。 Q&Aデータに対してquery decomposition を繰り返すことでBinary Search Tree を構築する処理はアルゴリズム1である。9〜13行目の処理で幅優先探索にて推論のみと検索後に推論しているノードを生成している。終端の回答が正解であるかどうかは教師データの回答と比較して報酬を決定する。 3.4 Chain of Calibration (CoC) Chain of Thought (CoT)に似ているがCoTは推論方法であり、Chain of Calibration (CoC) は学習方法である。模倣学習(Stage I)で学習したベースモデルを用いてStage II として外部知識で再調整(calibrate)するステップを実行し学習を行う。 atomic decisions 時にはLLMに自身が持つ知識境界を明確に認識させる必要があり、そのために(1)検索が必要かどうか判定するための後述する合成Preference Dataの作成(2)LLMに対する特殊なFinetuningという2つの手順を踏む。 (1)Algorithm.1 で生成されたBinary Tree上の最適パスをたどることで各サブクエリ時に検索する・しないのどちらが選択されるべきかというPreference Dataを作成する。 L=−logσ(βlogπθ(yw∣si,qi)πref(yw∣si,qi)−βlogπθ(yl∣si,qi)πref(yl∣si,qi))\mathcal{L} = - \log \sigma \left( \beta \log \frac{ \pi_\theta (y_w \mid s_i, q_i) }{ \pi_{\text{ref}}(y_w \mid s_i, q_i) } - \beta \log \frac{ \pi_\theta (y_l \mid s_i, q_i) }{ \pi_{\text{ref}}(y_l \mid s_i, q_i) } \right) L=−logσ(βlogπref(yw∣si,qi)πθ(yw∣si,qi)−βlogπref(yl∣si,qi)πθ(yl∣si,qi)) (2)の学習では上記目的関数を最小化する。 ywy_wyw と yly_lyl はそれぞれ検索なしの回答と検索ありの回答を表す。 πref{\pi}_{ref} πref は参照ベースモデルを表し、ベースモデルからベイズ因子が改善する方向へ収束させる。 実験 Table.2が示すようにDeepRAGは最も少ない回数で必要な情報を取得することができる。これはMDPによる定式化の効果である。 Table.3 は atomic decisions によってどれだけ効率的に知識境界を探索できているかを示す。特にBalanced ACCやMCCの値の高さはDeepRAGが不必要な検索を行っていないことがわかる。 図5はNarrative の効果で推論のたびに毎回検索するより、全く検索しないよりもDeepRAGのアルゴリズムの方が改善されることを示す。 図6は模倣学習とCoCのアブレーションスタディである。(a)から模倣学習により検索回数を減らしスコアを上昇させていること、(b)からはBinary Search Tree のすべてのノードを使用するよりも最適パスのノードのみ使用した方が検索回数が減ることが示されている。

選定理由
中国科学院ソフトウェア研究所とWeChat AI研究チームの共同研究。
Paper: https://arxiv.org/abs/2502.01142
Code:N/A
blog: https://x.gd/wTnkm
https://zenn.dev/ren_ren_tnk/articles/775d6050e0cf4d
概要
【社会課題】
search-o1 と同じ
【技術課題】
従来のRAG手法ではRetriever(検索器)とGenerator(生成器)が独立に設計・最適化されていることにより、連携が不十分になり最終的な応答の品質や効率の課題を生んでいた。
【提案】
RetrieverとGeneratorが統一的な枠組みで最適化できるEnd2End な新しいRAGを提案。
・検索強化推論(検索+推論の複合的ワークフロー)をマルコフ決定過程(MDP)として定式化し、最適な行動(検索するかどうか)を逐次選択。
・問題を段階的に分解しながら検索と推論を繰り返す手法を導入。
・各ステップで生成されるサブクエリに基づいて外部知識を取り込み、次のステップに活用。
・Retrieval Narrative + Atomic Decisions
Retrieval Narrative: すでに獲得している内部知識に基づき、文脈に沿ったサブクエリを生成。Atomic Decision: 各ステップで「検索する」or「内部知識だけで推論する」を判断。
【効果】
内部知識と外部知識の使い分けによりハルシネーションが抑制された結果、従来手法より21.99%の精度向上を実現した。無駄な検索を減らし必要なタイミングでのみ情報取得をすることで、計算・リソースの効率も改善した。
DeepRAG
図2はDeepRAGの全体像であり、この仕組みでRetrieval Narrative(クエリ分解) と atomic decision(検索するかしないかの判断)を行う。
3.1 Overview of the MDP Modeling
DeepRAGでは、検索強化推論のプロセスを以下の4つの要素からなるMDPとしてモデル化する:
状態(States, S)
各ステップにおける状態は、元のクエリとそれまでのサブクエリとその応答の履歴 (q1,r1),…,(qt,rt)(q_1, r_1), \ldots, (q_t, r_t)(q1,r1),…,(qt,rt) で構成される。
行動(Actions, A)
各ステップでの行動 at+1a_{t+1}at+1 は、以下の2つの行動から成る:
終了判定(Termination Decision): 次のサブクエリ qt+1q_{t+1}qt+1 を生成するか、最終的な回答 ooo を出力してプロセスを終了するかを決定。
検索判定(Atomic Decision): 次のサブクエリ qt+1q_{t+1}qt+1 に対して、外部知識を取得する(retrieve)か、内部のパラメトリック知識に依存する(parametric)かを決定。
遷移(Transitions, P):
行動 at+1a_{t+1}at+1 を実行し、状態は st+1s_{t+1}st+1 に更新。
終了判定が「terminate」の場合、最終回答
ooo
を生成し終了
終了判定が「continue」の場合、次のサブクエリ
qt+1q_{t+1}qt+1
を生成
検索判定が「retrieve」の場合、外部知識を取得し中間応答を生成。
検索判定が「parametric」の場合、内部知識に基づいて中間応答を生成。
報酬(Rewards, R):
最終的な回答
ooo
を生成した後、報酬関数
RRR
は、回答の正確性と検索コストに基づいて評価されます。
正確な回答には正の報酬が与えられ、不正確な回答や不要な検索にはペナルティが課される。
3.2 Binary Tree Search, 3.3 Imitation Learning

上記のようなプロンプトを用いて質問文をサブクエリに分解するRetrieval Narrativeを実施する。

Q&Aデータに対してquery decomposition を繰り返すことでBinary Search Tree を構築する処理はアルゴリズム1である。9〜13行目の処理で幅優先探索にて推論のみと検索後に推論しているノードを生成している。終端の回答が正解であるかどうかは教師データの回答と比較して報酬を決定する。
3.4 Chain of Calibration (CoC)
Chain of Thought (CoT)に似ているがCoTは推論方法であり、Chain of Calibration (CoC) は学習方法である。模倣学習(Stage I)で学習したベースモデルを用いてStage II として外部知識で再調整(calibrate)するステップを実行し学習を行う。
atomic decisions 時にはLLMに自身が持つ知識境界を明確に認識させる必要があり、そのために(1)検索が必要かどうか判定するための後述する合成Preference Dataの作成(2)LLMに対する特殊なFinetuningという2つの手順を踏む。
(1)Algorithm.1 で生成されたBinary Tree上の最適パスをたどることで各サブクエリ時に検索する・しないのどちらが選択されるべきかというPreference Dataを作成する。
(2)の学習では上記目的関数を最小化する。 ywy_wyw と yly_lyl はそれぞれ検索なしの回答と検索ありの回答を表す。 πref{\pi}_{ref} πref は参照ベースモデルを表し、ベースモデルからベイズ因子が改善する方向へ収束させる。
実験
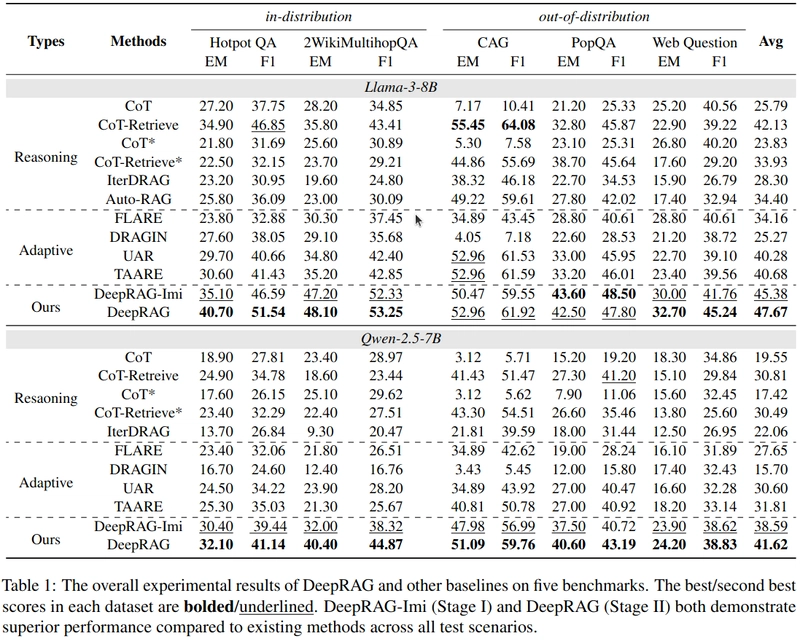

Table.2が示すようにDeepRAGは最も少ない回数で必要な情報を取得することができる。これはMDPによる定式化の効果である。

Table.3 は atomic decisions によってどれだけ効率的に知識境界を探索できているかを示す。特にBalanced ACCやMCCの値の高さはDeepRAGが不必要な検索を行っていないことがわかる。

図5はNarrative の効果で推論のたびに毎回検索するより、全く検索しないよりもDeepRAGのアルゴリズムの方が改善されることを示す。

図6は模倣学習とCoCのアブレーションスタディである。(a)から模倣学習により検索回数を減らしスコアを上昇させていること、(b)からはBinary Search Tree のすべてのノードを使用するよりも最適パスのノードのみ使用した方が検索回数が減ることが示されている。