















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)









































































































































































































![Blue Archive tier list [April 2025]](https://media.pocketgamer.com/artwork/na-33404-1636469504/blue-archive-screenshot-2.jpg?#)
































.png?#)








-Baldur’s-Gate-3-The-Final-Patch---An-Animated-Short-00-03-43.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)































.webp?#)







































































































![Apple to Split Enterprise and Western Europe Roles as VP Exits [Report]](https://www.iclarified.com/images/news/97032/97032/97032-640.jpg)
![Nanoleaf Announces New Pegboard Desk Dock With Dual-Sided Lighting [Video]](https://www.iclarified.com/images/news/97030/97030/97030-640.jpg)

![Apple's Foldable iPhone May Cost Between $2100 and $2300 [Rumor]](https://www.iclarified.com/images/news/97028/97028/97028-640.jpg)























































































































Cut Your API Costs to Zero: Docker Model Runner for Local LLM Testing
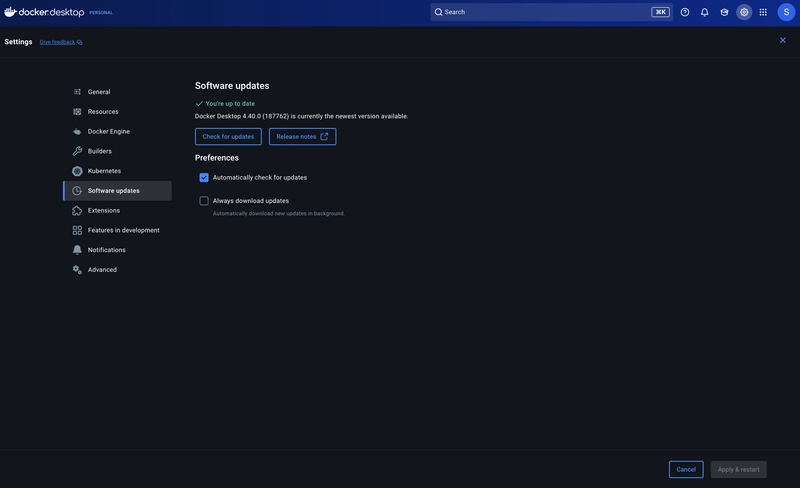
With the release of Docker Desktop 4.40, a beta version of Docker Model Runner is now available for Mac users with Apple Silicon (M1–M4). Official Docs If you're like me and use APIs like OpenAI or Amazon Bedrock in your applications, you know how quickly costs can pile up—especially during local development or team collaboration. And with new open-source LLMs like Gemma 3 and LLaMA 3.3 grabbing attention, there’s a growing need to try them out easily on your machine without hitting the cloud. That's exactly where Docker Model Runner comes in. Let’s dive into what it is and how to use it effectively. What is Docker Model Runner? Docker Model Runner is a local inference server integrated into Docker Desktop. It mimics the OpenAI API, which means if your app already uses the OpenAI SDK, switching to a local model is as simple as changing the API base URL: new OpenAI({ apiKey: 'dummy', baseURL: 'http://model-runner.docker.internal/engines/v1' }) While Ollama also supports local LLMs, its API isn’t OpenAI-compatible—so if you're using the official SDK, Docker Model Runner offers a smoother experience. Plus, you can easily pull models from Docker Hub: docker model pull ai/gemma3 Use Case: Cloud for Production, Local for Development The most practical way to use Docker Model Runner is to separate your production and development environments. In my case, I use Amazon Bedrock in production. But for prompt tuning or testing during development, hitting Bedrock is expensive and inefficient. Instead, I switch to Docker Model Runner locally. This same approach works whether you're using OpenAI, Vertex AI, or any other cloud LLM. Getting Started 1. Update Docker Desktop Make sure you’re running Docker Desktop 4.40 or newer. 2. Enable Docker Model Runner Go to: Settings > Features in development > Beta features > Enable Docker Model Runner Or enable it via CLI: docker desktop enable model-runner 3. Pull a Model Visit the ai namespace on Docker Hub, and pull the model you want: docker model pull ai/gemma3:1B-Q4_K_M Check available models: docker model list 4. Configure .env Set the following environment variables in your .env file: ENV=local BASE_URL=http://model-runner.docker.internal/engines/v1 MODEL=ai/gemma3:1B-Q4_K_M docker.internal is a special hostname provided by Docker Desktop. 5. Use as OpenAI-Compatible API Here's an example using NestJS with axios: axios.post(`${BASE_URL}/chat/completions`, { model: MODEL, messages: [...] }) If you're already using the OpenAI SDK, just point baseURL to the Docker Model Runner URL and you're good to go. Example: Switching Between Environments (NestJS) const llmResponse = process.env.ENV === 'local' ? await this.openAIService.queryOpenAI(systemPrompt, userPrompt) : await this.bedrockService.queryBedrock(systemPrompt, userPrompt) @Injectable() export class OpenAIService { constructor(private readonly openAIClient: OpenAIClient) {} async queryOpenAI(systemPrompt: string, userPrompt: string): Promise { try { return await this.openAIClient.sendQuery(systemPrompt, userPrompt) } catch (error) { const message = error?.message ?? 'Unknown error' throw new InternalServerErrorException(`Failed to get response from model: ${message}`) } } } export class OpenAIClient { private readonly openai: OpenAI private readonly model: string constructor() { const apiKey = process.env.OPENAI_API_KEY ?? 'dummy-key' const baseURL = process.env.BASE_URL ?? 'https://api.openai.com/v1' this.model = process.env.MODEL ?? 'gpt-4o-mini' this.openai = new OpenAI({ apiKey, baseURL }) if (baseURL.includes('api.openai.com') && !process.env.OPENAI_API_KEY) { console.warn('OPENAI_API_KEY is not set. OpenAI API won’t work.') } } async sendQuery(systemPrompt: string, userPrompt: string): Promise { try { const response = await this.openai.chat.completions.create({ model: this.model, messages: [ { role: 'system', content: systemPrompt }, { role: 'user', content: userPrompt } ], temperature: 0.2, max_tokens: 500, top_p: 0.5 }) const content = response.choices[0]?.message?.content if (!content) { throw new Error(`No valid response received from ${this.model}`) } return content } catch (error) { const message = error?.response?.data?.error?.message ?? error?.message ?? 'Unknown error' console.error(`Error from ${this.model}:`, message) throw error } } } No Need to Touch docker-compose.yml Docker Model Runner runs as an internal service in Docker Desktop, so no need to modify your docker-compose.yml. Just update .env and pull your models in advance—you're re
With the release of Docker Desktop 4.40, a beta version of Docker Model Runner is now available for Mac users with Apple Silicon (M1–M4).
Official Docs
If you're like me and use APIs like OpenAI or Amazon Bedrock in your applications, you know how quickly costs can pile up—especially during local development or team collaboration.
And with new open-source LLMs like Gemma 3 and LLaMA 3.3 grabbing attention, there’s a growing need to try them out easily on your machine without hitting the cloud.
That's exactly where Docker Model Runner comes in. Let’s dive into what it is and how to use it effectively.
What is Docker Model Runner?
Docker Model Runner is a local inference server integrated into Docker Desktop. It mimics the OpenAI API, which means if your app already uses the OpenAI SDK, switching to a local model is as simple as changing the API base URL:
new OpenAI({
apiKey: 'dummy',
baseURL: 'http://model-runner.docker.internal/engines/v1'
})
While Ollama also supports local LLMs, its API isn’t OpenAI-compatible—so if you're using the official SDK, Docker Model Runner offers a smoother experience.
Plus, you can easily pull models from Docker Hub:
docker model pull ai/gemma3
Use Case: Cloud for Production, Local for Development
The most practical way to use Docker Model Runner is to separate your production and development environments.
In my case, I use Amazon Bedrock in production. But for prompt tuning or testing during development, hitting Bedrock is expensive and inefficient. Instead, I switch to Docker Model Runner locally.
This same approach works whether you're using OpenAI, Vertex AI, or any other cloud LLM.
Getting Started
1. Update Docker Desktop
Make sure you’re running Docker Desktop 4.40 or newer.
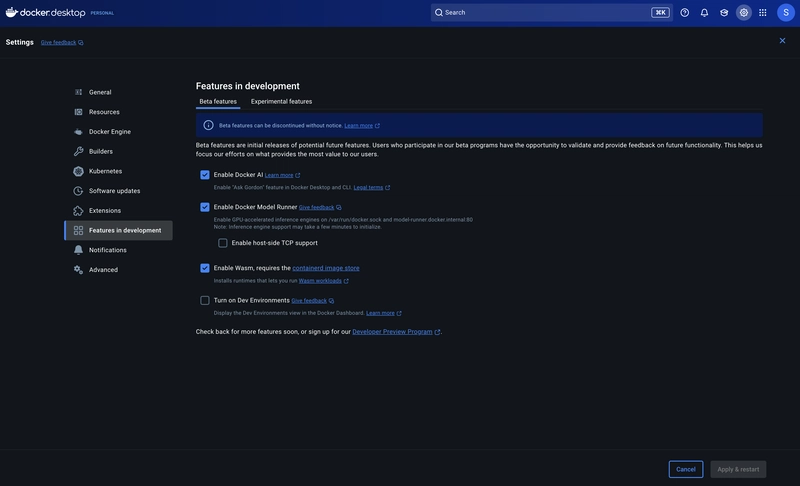
2. Enable Docker Model Runner
Go to:
Settings > Features in development > Beta features > Enable Docker Model Runner
Or enable it via CLI:
docker desktop enable model-runner
3. Pull a Model
Visit the ai namespace on Docker Hub, and pull the model you want:
docker model pull ai/gemma3:1B-Q4_K_M
Check available models:
docker model list

4. Configure .env
Set the following environment variables in your .env file:
ENV=local
BASE_URL=http://model-runner.docker.internal/engines/v1
MODEL=ai/gemma3:1B-Q4_K_M
docker.internalis a special hostname provided by Docker Desktop.
5. Use as OpenAI-Compatible API
Here's an example using NestJS with axios:
axios.post(`${BASE_URL}/chat/completions`, {
model: MODEL,
messages: [...]
})
If you're already using the OpenAI SDK, just point baseURL to the Docker Model Runner URL and you're good to go.
Example: Switching Between Environments (NestJS)
const llmResponse =
process.env.ENV === 'local'
? await this.openAIService.queryOpenAI(systemPrompt, userPrompt)
: await this.bedrockService.queryBedrock(systemPrompt, userPrompt)
@Injectable()
export class OpenAIService {
constructor(private readonly openAIClient: OpenAIClient) {}
async queryOpenAI(systemPrompt: string, userPrompt: string): Promise<string> {
try {
return await this.openAIClient.sendQuery(systemPrompt, userPrompt)
} catch (error) {
const message = error?.message ?? 'Unknown error'
throw new InternalServerErrorException(`Failed to get response from model: ${message}`)
}
}
}
export class OpenAIClient {
private readonly openai: OpenAI
private readonly model: string
constructor() {
const apiKey = process.env.OPENAI_API_KEY ?? 'dummy-key'
const baseURL = process.env.BASE_URL ?? 'https://api.openai.com/v1'
this.model = process.env.MODEL ?? 'gpt-4o-mini'
this.openai = new OpenAI({
apiKey,
baseURL
})
if (baseURL.includes('api.openai.com') && !process.env.OPENAI_API_KEY) {
console.warn('OPENAI_API_KEY is not set. OpenAI API won’t work.')
}
}
async sendQuery(systemPrompt: string, userPrompt: string): Promise<string> {
try {
const response = await this.openai.chat.completions.create({
model: this.model,
messages: [
{ role: 'system', content: systemPrompt },
{ role: 'user', content: userPrompt }
],
temperature: 0.2,
max_tokens: 500,
top_p: 0.5
})
const content = response.choices[0]?.message?.content
if (!content) {
throw new Error(`No valid response received from ${this.model}`)
}
return content
} catch (error) {
const message = error?.response?.data?.error?.message ?? error?.message ?? 'Unknown error'
console.error(`Error from ${this.model}:`, message)
throw error
}
}
}
No Need to Touch docker-compose.yml
Docker Model Runner runs as an internal service in Docker Desktop, so no need to modify your docker-compose.yml.
Just update .env and pull your models in advance—you're ready to go.
What’s Next?
According to Docker, upcoming features include:
- Windows support (with GPU acceleration!)
- Custom model publishing
- Integration with Compose and test containers
More info:
Introducing Docker Model Runner: A Better Way to Build and Run GenAI Models Locally
Run LLMs Locally with Docker: A Quickstart Guide to Model Runner