






















































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)












































































































































































































































































_NicoElNino_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



























































































![Craft adds Readwise integration for working with book notes and highlights [50% off]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/craft3.jpg.png?resize=1200%2C628&quality=82&strip=all&ssl=1)














![Apple Restructures Global Affairs and Apple Music Teams [Report]](https://www.iclarified.com/images/news/97162/97162/97162-640.jpg)
![New iPhone Factory Goes Live in India, Another Just Days Away [Report]](https://www.iclarified.com/images/news/97165/97165/97165-640.jpg)






























































































Building Multimodal AI Applications With MongoDB, Voyage AI, and Gemini
The internet has content spanning multiple mediums, formats, and modalities. However, most LLM-based AI applications in the past few years have primarily dealt with text data. This is because embedding models and LLMs, until recently, were focused mainly on text. But this is changing— LLMs like Gemini and GPT-4o can now process and generate images, audio, and video. Vendors like Voyage AI and Cohere have multimodal embedding models that can embed both images and text. This means we are no longer limited to using just text in our LLM applications. In this tutorial, you will learn how to build a RAG application using documents consisting of interleaved text, images, and tables as their source of knowledge. Specifically, we will cover the following: What is multimodality? Processing multimodal data for retrieval Evaluating the performance of different multimodal embedding models Building a RAG application using multimodal embedding models and LLMs What is multimodality? Multimodality in the context of AI is the ability of machine learning models to process, understand, and sometimes generate different types of data, including text, images, audio, video, etc. In this tutorial, you will come across multimodal embedding models as well as LLMs. Multimodal embedding models can take different types of data or modalities as input and map them to the same high-dimensional vector space. Multimodal LLMs can not only accept multiple data formats as input but also generate different modalities as output. When choosing multimodal embedding models and LLMs for your application, keep in mind that not all models support all modalities. Always check the model specifications to determine which data types are supported as inputs and outputs for any given model. The challenge of multimodality A typical RAG pipeline for text data looks as follows: In the above setup, large documents are first broken down into smaller segments or chunks. The text in each chunk is then embedded using a text embedding model, and the raw text of the chunk, along with its embedding, is stored in a vector database. Given a user query, it is embedded using the same embedding model, and relevant chunks are retrieved using vector search or other retrieval techniques. The retrieved documents, along with the user query and any additional prompts, are sent to the LLM to generate an answer. This setup works well for documents that contain mainly text data. However, it doesn’t quite work for documents with mixed modalities since traditional text-based chunking can't and shouldn’t be applied directly to images, tables, and other non-text elements. Additionally, effectively retrieving these heterogeneous data types requires specialized embedding models to maintain the contextual relationships between different modalities. CLIP vs. VLM-based multimodal embedding models Until recently, the architecture of several multimodal embedding models in the market was based on OpenAI’s Contrastive Language-Image Pre-Training (CLIP) embedding model. In this architecture, text and images are processed via independent networks to generate embeddings. CLIP's separate treatment of images and text necessitates extracting these elements from documents, thus creating complex document parsing pipelines. Additionally, this architecture results in a phenomenon called “modality gap,” wherein unrelated concepts within the same modality often appear closer in vector space than related concepts across different modalities. This gap occurs because the vision and text encoders have fundamentally different architectures, learning representations through different transformations despite mapping to the same vector space. This is where a newer embedding model architecture based on Vision Language Models (VLMs) can help. These models use a single transformer encoder for both images and text, thus creating unified representations that preserve contextual relationships between modalities. This helps minimize the modality gap and eliminates the need for complex document parsing, allowing direct processing of interleaved texts and images, document screenshots, PDFs with complex layouts, annotated images, etc. Building a multimodal RAG application In this tutorial, we will build a multimodal RAG application using MongoDB as the vector store, a voyage-multimodal-3, a multimodal embedding model for images and text from Voyage AI, and Gemini 2.0 Flash, a multimodal LLM from Google that can interpret and generate text, images, voice, and video. We will also evaluate the performance of voyage-multimodal-3 against OpenAI’s CLIP on a large, multi-page document consisting of interleaved text and images. Here’s an architecture diagram of the system we are building: Given a multi-page PDF document, we will screenshot the PDF pages and write the raw images to blob storage. We will also embed the screenshots using a multimodal embedding model
The internet has content spanning multiple mediums, formats, and modalities. However, most LLM-based AI applications in the past few years have primarily dealt with text data. This is because embedding models and LLMs, until recently, were focused mainly on text. But this is changing— LLMs like Gemini and GPT-4o can now process and generate images, audio, and video. Vendors like Voyage AI and Cohere have multimodal embedding models that can embed both images and text. This means we are no longer limited to using just text in our LLM applications.
In this tutorial, you will learn how to build a RAG application using documents consisting of interleaved text, images, and tables as their source of knowledge. Specifically, we will cover the following:
- What is multimodality?
- Processing multimodal data for retrieval
- Evaluating the performance of different multimodal embedding models
- Building a RAG application using multimodal embedding models and LLMs
What is multimodality?
Multimodality in the context of AI is the ability of machine learning models to process, understand, and sometimes generate different types of data, including text, images, audio, video, etc.
In this tutorial, you will come across multimodal embedding models as well as LLMs. Multimodal embedding models can take different types of data or modalities as input and map them to the same high-dimensional vector space. Multimodal LLMs can not only accept multiple data formats as input but also generate different modalities as output.
When choosing multimodal embedding models and LLMs for your application, keep in mind that not all models support all modalities. Always check the model specifications to determine which data types are supported as inputs and outputs for any given model.
The challenge of multimodality
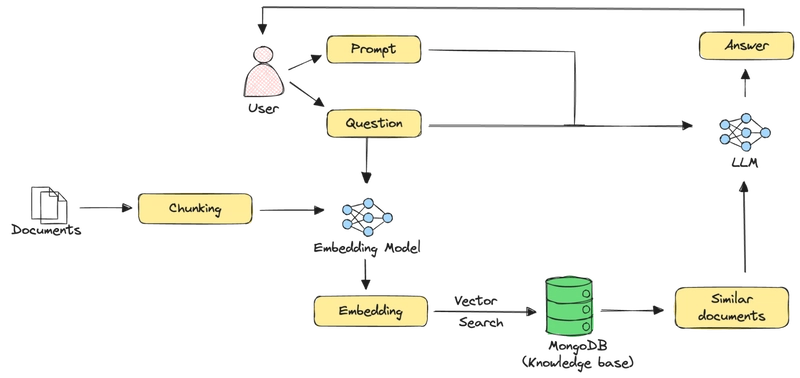
A typical RAG pipeline for text data looks as follows:
In the above setup, large documents are first broken down into smaller segments or chunks. The text in each chunk is then embedded using a text embedding model, and the raw text of the chunk, along with its embedding, is stored in a vector database. Given a user query, it is embedded using the same embedding model, and relevant chunks are retrieved using vector search or other retrieval techniques. The retrieved documents, along with the user query and any additional prompts, are sent to the LLM to generate an answer.
This setup works well for documents that contain mainly text data. However, it doesn’t quite work for documents with mixed modalities since traditional text-based chunking can't and shouldn’t be applied directly to images, tables, and other non-text elements. Additionally, effectively retrieving these heterogeneous data types requires specialized embedding models to maintain the contextual relationships between different modalities.
CLIP vs. VLM-based multimodal embedding models
Until recently, the architecture of several multimodal embedding models in the market was based on OpenAI’s Contrastive Language-Image Pre-Training (CLIP) embedding model. In this architecture, text and images are processed via independent networks to generate embeddings.
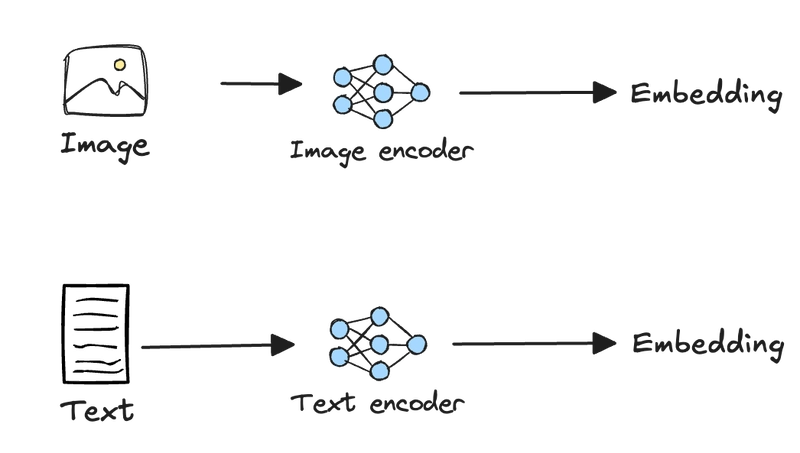
CLIP's separate treatment of images and text necessitates extracting these elements from documents, thus creating complex document parsing pipelines. Additionally, this architecture results in a phenomenon called “modality gap,” wherein unrelated concepts within the same modality often appear closer in vector space than related concepts across different modalities. This gap occurs because the vision and text encoders have fundamentally different architectures, learning representations through different transformations despite mapping to the same vector space.
This is where a newer embedding model architecture based on Vision Language Models (VLMs) can help.
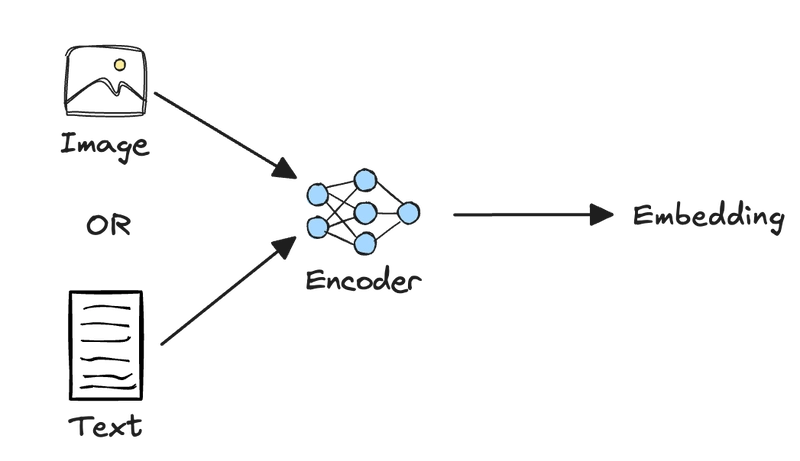
These models use a single transformer encoder for both images and text, thus creating unified representations that preserve contextual relationships between modalities. This helps minimize the modality gap and eliminates the need for complex document parsing, allowing direct processing of interleaved texts and images, document screenshots, PDFs with complex layouts, annotated images, etc.
Building a multimodal RAG application
In this tutorial, we will build a multimodal RAG application using MongoDB as the vector store, a voyage-multimodal-3, a multimodal embedding model for images and text from Voyage AI, and Gemini 2.0 Flash, a multimodal LLM from Google that can interpret and generate text, images, voice, and video. We will also evaluate the performance of voyage-multimodal-3 against OpenAI’s CLIP on a large, multi-page document consisting of interleaved text and images.
Here’s an architecture diagram of the system we are building:
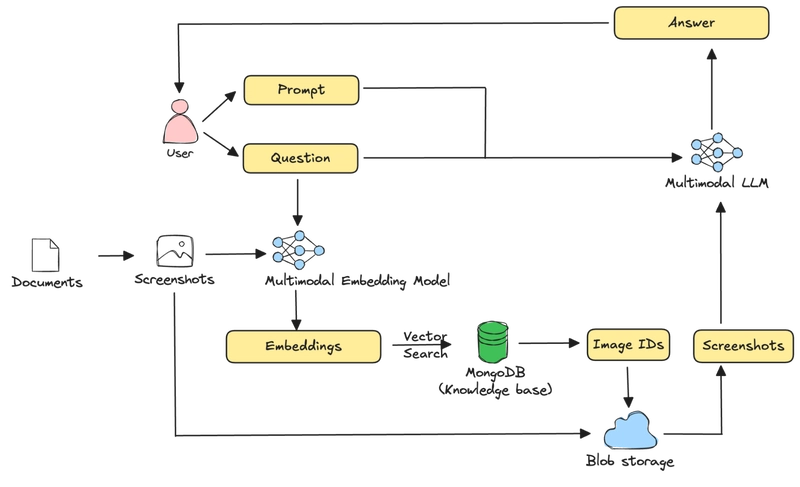
Given a multi-page PDF document, we will screenshot the PDF pages and write the raw images to blob storage. We will also embed the screenshots using a multimodal embedding model and store the embeddings, along with some metadata, including the references to the raw image files into MongoDB. Given a user query, we first embed it using the same embedding model we used to embed the screenshots and perform a vector search to identify the PDF pages that are most relevant to the query based on their embedded screenshots. The screenshots of these pages are then retrieved from blob storage and passed to a multimodal LLM, along with the user query and other prompts to generate an answer.
Where’s the code?
The Jupyter Notebook for this tutorial can be found on GitHub in our Gen AI Showcase repository.
Step 1: Install required libraries
We will require the following libraries for this tutorial:
- pymongo: Python driver for MongoDB
- voyageai: Python client for Voyage AI
- google-genai: Python library to access Google's embedding models and LLMs via Google AI Studio
- google-cloud-storage: Python client for Google Cloud Storage
- sentence-transformers: Python library to use open-source ML models from Hugging Face
- PyMuPDF: Python library for analyzing and manipulating PDFs
- Pillow: A Python imaging library
- tqdm: Show progress bars for loops in Python
- tenacity: Python library for adding retries to functions
!pip install -qU pymongo voyageai google-genai google-cloud-storage sentence-transformers PyMuPDF Pillow tqdm tenacity
Step 2: Set up prerequisites
We will use MongoDB as the vector database for RAG. But first, you will need a MongoDB Atlas account with a database cluster. Once you do that, you will need to get the connection string to connect to your cluster. Follow these steps to get set up:
- Register for a free MongoDB Atlas account.
- Create a new database cluster.
- Obtain the connection string for your database cluster.
Once you have the connection string, set it in your code as follows:
import getpass
MONGODB_URI = getpass.getpass("Enter your MongoDB connection string: ")
To use Voyage AI’s embedding models, you will need to obtain a Voyage AI API key and set it as an environment variable:
import os
os.environ["VOYAGE_API_KEY"] = getpass.getpass("Enter your Voyage AI API key: ")
You will also need to obtain a Gemini API key to use Gemini models via Google AI Studio:
GEMINI_API_KEY = getpass.getpass("Enter your Gemini API key: ")
Finally, you will need to set up Application Default Credentials (ADC) to communicate with Google Cloud Storage using the Python client. Follow the instructions to provide credentials to ADC.
We are configuring ADC with a Google account for this tutorial, but there are other options that might be better suited for the environment where you are running your RAG application.
Step 3: Read a PDF from a URL
In this tutorial, we will use the Deepseek-R1 paper as the source of knowledge for our RAG application. The paper is substantially long and consists of text interleaved with figures and tables. This is a good representation of datasets we see in the real world for RAG, such as financial reports, technical manuals, business proposals, product catalogs, etc.
Let’s download the Deepseek paper as a PDF document:
from io import BytesIO
import pymupdf
import requests
# Download the DeepSeek paper
response = requests.get("https://arxiv.org/pdf/2501.12948")
if response.status_code != 200:
raise ValueError(f"Failed to download PDF. Status code: {response.status_code}")
# Load the response as an in-memory file-like object
pdf_stream = BytesIO(response.content)
# Open the object as a PDF document
pdf = pymupdf.open(stream=pdf_stream, filetype="pdf")
The above code makes an HTTP GET request to get the content of the Deepseek paper from Arxiv, loads the content as an in-memory file-like object using BytesIO, and opens the file-like object as a PDF using PyMuPDF.
Step 4: Store PDF images in GCS and extract metadata for MongoDB
Typically, for RAG applications that work with text-only data, you store the raw chunk text alongside their embeddings in the vector store. However, images, audio, and videos can get large, so we suggest against storing them directly in a database (MongoDB or otherwise) to avoid performance bottlenecks. Instead, store the media files in blob storage like Amazon S3, GCS, etc., and store references to the stored objects in MongoDB documents since these solutions are specifically optimized for storing and retrieving large binary objects at scale at significantly lower storage costs per gigabyte.
In this tutorial, we want to test the ability of multimodal embedding models and LLMs to process content-rich images consisting of text interspersed with figures and tables. So we will first convert the PDF we downloaded in Step 3 to a set of screenshots. We will store the raw screenshots in GCS and store references to the GCS objects in MongoDB documents.
Let’s first define a helper function to upload objects to GCS:
from google.cloud import storage
from tqdm import tqdm
# Set GCS project and bucket
GCS_PROJECT = "mongodb"
GCS_BUCKET = "tutorials"
# Instantiate the GCS client and bucket
gcs_client = storage.Client(project=GCS_PROJECT)
gcs_bucket = gcs_client.bucket(GCS_BUCKET)
def upload_image_to_gcs(key: str, data: bytes) -> None:
"""
Upload image to GCS.
Args:
key (str): Unique identifier for the image in the bucket.
data (bytes): Image bytes to upload.
"""
blob = gcs_bucket.blob(key)
blob.upload_from_string(data, content_type="image/png")
The above code:
- Instantiates a GCS client that connects to the
genaiproject and a bucket calledtutorialswithin that project. - Creates a function called
upload_image_to_gcsthat:- Takes an object name (
key) and object content (data) as input. - Uses the
keyto create a GCS object, a.k.a.blob, in theGCS_BUCKETbucket, and uploads the object content as bytes to the blob. The content type is set toimage/pngto allow browsers to render the image content correctly.
- Takes an object name (
Now, let’s iterate through the pages of the PDF we downloaded in Step 3, convert each page into an image, write the raw images to GCS, and extract the metadata to write to MongoDB.
docs = []
zoom = 3.0
mat = pymupdf.Matrix(zoom, zoom)
# Iterate through the pages of the PDF
for n in tqdm(range(pdf.page_count)):
temp = {}
# Render the PDf as an image
pix = pdf[n].get_pixmap(matrix=mat)
# Convert the image to in-memory bytes in PNG format
img_bytes = pix.tobytes("png")
gcs_key = f"multimodal-rag/{n+1}.png"
# Upload the image bytes to GCS
upload_image_to_gcs(gcs_key, img_bytes)
# Extract some image metadata
temp["image"] = img_bytes
temp["gcs_key"] = gcs_key
temp["width"] = pix.width
temp["height"] = pix.height
docs.append(temp)
The above code performs the following actions on each page of the PDF downloaded in Step 3:
- Renders it as an image using the
get_pixmapmethod in the PyMuPDF library. - Converts the image to an in-memory PNG-formatted bytes object using the
tobytesmethod. - Generates a unique identifier (
gcs_key) for the image object to be stored in GCS. This follows the formatmultimodal-rag/(n+1).pngwhere n is the page number. - Uploads the image bytes to a GCS using the
upload_image_to_gcshelper function. - Creates the document to be written to MongoDB, consisting of the GCS key (
gcs_key), image width (width), height (height), and temporarily, the image bytes (image). - Appends the document to a list (
docs).
Step 5: Add embeddings to the MongoDB documents
To enable vector search on the PDF screenshots, we need to embed them and add the embeddings to the MongoDB documents. Since we are evaluating two multimodal embedding models in this tutorial, we will add embeddings from both models to the documents.
To do this, let’s create helper functions to generate embeddings using Voyage AI’s voyage-multimodal-3 and OpenAI’s CLIP models:
from voyageai import Client
voyageai_client = Client()
def get_voyage_embedding(data: Union[Image, str], input_type: str) -> List:
"""
Get Voyage AI embeddings for images and text.
Args:
data (Union[Image, str]): An image or text to embed.
input_type (str): Input type, either "document" or "query".
Returns:
List: Embeddings as a list.
"""
embedding = voyageai_client.multimodal_embed(
inputs=[[data]], model="voyage-multimodal-3", input_type=input_type
).embeddings[0]
return embedding
The above code:
- Creates a Voyage AI API client. This uses the
VOYAGE_API_KEYenvironment variable you set in Step 1 to authenticate requests to the Voyage AI API. - Uses the
multimodal_embedmethod from the Voyage AI API with the following arguments to generate embeddings:-
inputs: List of text strings and/or PIL image objects to embed. -
model: The model to use for embedding. We use thevoyage-multimodal-3, which is Voyage AI’s latest multimodal embedding model. -
input_type: Should be set to eitherqueryordocument.Set it toquerywhen embedding the user query anddocumentwhen embedding the dataset that you will use as the knowledge base for your RAG application.
-
from sentence_transformers import SentenceTransformer
clip_model = SentenceTransformer("clip-ViT-B-32")
def get_clip_embedding(data: Union[Image, str]) -> List:
"""
Get CLIP embeddings for images and text.
Args:
data (Union[Image, str]): An image or text to embed.
Returns:
List: Embeddings as a list.
"""
embedding = clip_model.encode(data).tolist()
return embedding
The above code:
- Downloads the latest version of OpenAI’s CLIP model,
clip-ViT-B-32, from Hugging Face using the Sentence Transformer library. - Uses the
encodemethod to generate embeddings for an image or a piece of text and converts the resulting embedding Tensor to a list usingtolist().
Next, let’s iterate over the MongoDB documents created in Step 4 and add embeddings from the Voyage AI and CLIP models to them:
embedded_docs = []
for doc in tqdm(docs):
# Open the image from the in-memory bytes
img = Image.open(BytesIO(doc["image"]))
# Add the Voyage AI and CLIP embeddings to the document
doc["voyage_embedding"] = get_voyage_embedding(img, "document")
doc["clip_embedding"] = get_clip_embedding(img)
# Remove the image bytes from the document
del doc["image"]
embedded_docs.append(doc)
The above code performs the following actions on each document contained in docs:
- Opens the PDF screenshot from binary image data stored in the
imagefield of the document. - Adds a field called
voyage_embeddingconsisting of the embedding of the screenshot generated by the Voyage AI model. Notice that theinput_typeargument here is set todocument. - Adds a field called
clip_embeddingconsisting of the embedding generated by the CLIP model. - Removes the
imagefield from the document since we don’t want to store the raw image in MongoDB. - Appends the modified document with embeddings to a list called
embedded_docs.
You can roll up the embedding generation into Step 4 to avoid iterating over the PDF pages twice. We have kept it separate in the tutorial for clarity.
Step 6: Ingest documents into MongoDB
The next step is to ingest the documents with embeddings into MongoDB.
from pymongo import MongoClient
# Create a MongoDB client
mongodb_client = MongoClient(
MONGODB_URI, appname="devrel.showcase.multimodal_rag_mongodb_voyage_ai"
)
# Check connection to the cluster
mongodb_client.admin.command("ping")
# Names of the MongoDB database, collection and vector search index
DB_NAME = "mongodb"
COLLECTION_NAME = "multimodal_rag"
# Connect to the MongoDB collection
collection = mongodb_client[DB_NAME][COLLECTION_NAME]
# Delete existing documents from the collection
collection.delete_many({})
# Insert the embedded documents into the collection
collection.insert_many(embedded_docs)
The above code:
- Creates a MongoDB client to connect to your database cluster.
- Connects to a collection named
multimodal_ragin a database namedmongodbin your cluster. - Deletes any existing documents from the collection.
- Bulk ingests the documents in the
embedded_docslist into the collection.
A sample document inserted into MongoDB looks as follows:
{
"_id": "67eeb8f06ae434784f5d0440",
"gcs_key": "multimodal-rag/1.png",
"width": 1786,
"height": 2526,
"voyage_embedding": [
0.0059509277343751,
0.0187988281252,
0.040283203125,
.
.
.
],
"clip_embedding": [
-0.2702203392982483,
0.36099976301193243,
-0.022063829004764557,
.
.
.
]
}
Step 7: Create a vector search index
Another requirement to enable efficient vector search on the data is to create a vector search index. The index specifies what fields to index and make searchable.
VS_INDEX_NAME = "vector_index"
model = {
"name": VS_INDEX_NAME,
"type": "vectorSearch",
"definition": {
"fields": [
{
"type": "vector",
"path": "voyage_embedding",
"numDimensions": 1024,
"similarity": "cosine",
},
{
"type": "vector",
"path": "clip_embedding",
"numDimensions": 512,
"similarity": "cosine",
},
]
},
}
collection.create_search_index(model=model)
The above code:
- Creates a vector search index definition to index the Voyage AI and CLIP embeddings since we want to evaluate both the models. The index definition contains the following configurations:
-
path: Represents the path to the embedding fields in the documents. -
numDimensions: Number of dimensions in the embedding vector. Notice that thevoyage-multimodal-3model produces embeddings containing 1024 dimensions, and the CLIP model produces embeddings with 512 dimensions. -
similarity: Similarity metric to measure distance in vector space.cosineworks well for most embedding models, unless specified otherwise in the model spec.
-
- Uses the index definition to create a vector search index against the
multimodal_ragcollection.
Step 8: Retrieve documents using vector search
With embeddings added to the documents and a vector search index created, we are ready to perform vector search on the data. Retrieving the screenshots is a two-step process. Given a user query, it is embedded using the same multimodal embedding model that was used to embed the PDF screenshots. Using vector search, we identify the screenshots that are closest to the user query in vector space. However, the vector search, in this case, only returns references to the screenshots. We then use these references to retrieve the screenshots from GCS.
So, let’s define two functions, one to perform vector search and another to download the image objects from GCS:
def get_image_from_gcs(key: str) -> bytes:
"""
Get image bytes from GCS.
Args:
key (str): Identifier for the image in the bucket.
Returns:
bytes: Image bytes.
"""
blob = gcs_bucket.blob(key)
image_bytes = blob.download_as_bytes()
return image_bytes
The above code defines a helper function that accepts the name of an object in GCS (key) as input and returns the object content as bytes.
def vector_search(
user_query: str, model: str, display_images: bool = True
) -> List[str]:
"""
Perform vector search and display images, and return the GCS keys.
Args:
user_query (str): User query string.
model (str): Embedding model to use, either "voyage" or "clip".
display_images (bool, optional): Whether or not to display images. Defaults to True.
Returns:
List[str]: List of GCS keys.
"""
# Get query embedding based on the model specified
if model == "voyage":
query_embedding = get_voyage_embedding(user_query, "query")
elif model == "clip":
query_embedding = get_clip_embedding(user_query)
# Define the VS aggregation pipeline
pipeline = [
{
"$vectorSearch": {
"index": VS_INDEX_NAME,
"queryVector": query_embedding,
"path": f"{model}_embedding",
"numCandidates": 150,
"limit": 5,
}
},
{
"$project": {
"_id": 0,
"gcs_key": 1,
"width": 1,
"height": 1,
"score": {"$meta": "vectorSearchScore"},
}
},
]
# Execute the aggregation pipeline
results = collection.aggregate(pipeline)
gcs_keys = []
# For each VS result
for result in results:
gcs_key = result["gcs_key"]
# If display_images is True, display the image
if display_images is True:
img = Image.open(BytesIO(get_image_from_gcs(gcs_key)))
print(f"{result['score']}\n")
display(img)
# Append the GCS key of the image to a list
gcs_keys.append(gcs_key)
return gcs_keys
The above code:
- Given a user query (
query), generates an embedding for it using the specified embedding model (model). - Defines a MongoDB aggregation pipeline that has two stages:
-
$vectorSearch: Performs vector search. ThequeryVectorfield in this stage contains the embedded user query, thepathrefers to the path of the embedding field in the MongoDB documents depending on themodelspecified,numCandidatesdenotes the number of nearest neighbors to consider in the vector space when performing vector search, and finallylimitindicates the number of documents that will be returned from the vector search. -
$project: Includes only certain fields (set to the value 1) in the final results returned by the aggregation pipeline. In this case, only the GCS key, the image width and height, and the vector search score are included in the results.
-
- Runs the aggregation pipeline against the
multimodal_ragcollection. - Gathers and returns the GCS keys from the vector search results.
You can run the vector search using the Voyage AI and CLIP embedding models and notice the difference in the results:
vector_search(
"Summarize the Pass@1 accuracy of Deepseek R1 against other models.",
"voyage",
display_images=False,
)
For the test query seen above, the vector search using voyage-multimodal-3 returns the following GCS keys and scores:
'multimodal-rag/1.png', 0.759
'multimodal-rag/13.png', 0.748
'multimodal-rag/14.png', 0.740
'multimodal-rag/7.png', 0.711
'multimodal-rag/4.png', 0.70
For the same query, clip-ViT-B-32 returns the following GCS keys and scores:
'multimodal-rag/1.png', 0.634
'multimodal-rag/7.png', 0.632
'multimodal-rag/14.png', 0.631
'multimodal-rag/8.png', 0.627
'multimodal-rag/5.png', 0.626
Notice that the models result in different PDF pages being retrieved. Also, note the broader distribution of similarity scores from the Voyage AI model compared to CLIP. This potentially indicates that the VLM-based model is more effective at capturing distinguishing features of each page and mapping text-based queries to mixed-modality content.
Step 9: Create a multimodal RAG app
Finally, let’s pass the retrieved screenshots as context to Gemini 2.0 Flash to generate answers to user queries.
from google import genai
from google.genai import types
gemini_client = genai.Client(api_key=GEMINI_API_KEY)
LLM = "gemini-2.0-flash"
def generate_answer(user_query: str, model: str) -> str:
"""
Generate answer to the user question using a Gemini multimodal LLM.
Args:
user_query (str): User query string.
model (str): Embedding model to use, either "voyage" or "clip".
Returns:
str: LLM generated answer.
"""
# Get the GCS keys of the images returned by the vector search
gcs_keys = vector_search(user_query, model, display_images=False)
# Get the images from GCS and open them
images = [Image.open(BytesIO(get_image_from_gcs(key))) for key in gcs_keys]
prompt = f"Answer the question based only on the provided context. If the context is empty, say I DON'T KNOW\n\nQuestion:{user_query}\n\nContext:\n"
# Prompt to the LLM consisting of the system prompt and the images
messages = [prompt] + images
# Get a response from the LLM
response = gemini_client.models.generate_content(
model=LLM,
contents=messages,
config=types.GenerateContentConfig(temperature=0.0),
)
return response.text
The above code:
- Instantiates a Google Gen AI SDK client to use Gemini models via the Gemini API.
- Specifies the LLM to use. We are using
gemini-2.0-flash. - Defines a
generate_answerfunction that:- Uses the
vector_searchfunction defined in Step 8 to get the GCS keys of the PDF pages that are most relevant to the user query (user_query). - Uses the
get_image_from_gcsfunction defined in Step 8 to retrieve the image bytes from GCS and then converts them into PIL image objects (images). - Creates the inputs for the LLM, consisting of a system prompt (
prompt) and the PDF screenshots (images). - Uses the
generate_contentmethod of the Gemini API to generate an answer using thegemini-2.0-flashmodel. The method takes the model name and inputs as arguments, and any additional configuration options for the output generation, such astemperaturevia theconfigparameter. We set thetemperatureto 0.0 to maximize the probability of deterministic outputs.
- Uses the
Step 10: Evaluating retrieval and generation
To wrap up, let's evaluate how using the VLM-based voyage-multimodal-3 versus CLIP embeddings affects both retrieval and generation quality in our RAG application. For this, we create a small evaluation dataset consisting of a set of questions derived from the Deepseek paper, their ground truth answers, and PDF page numbers (in decreasing order of relevance) that contain the context to answer the questions. A sample entry from the evaluation dataset looks as follows:
{
"question": "How does DeepSeek-R1-Zero's accuracy on the AIME 2024 benchmark improve during RL training?",
"answer": "The accuracy measured by the average pass@1 score increases from 15.6% to 71.0% pass@1 as a result of RL training.",
"page_numbers": [6, 7, 3, 1, 13],
}
We use the following metrics to evaluate retrieval quality:
- Mean Reciprocal Rank (MRR): Average of the reciprocal ranks (1 / position of the first relevant result) across all queries in the evaluation dataset. Measures how well the system ranks the first relevant item in the list of retrieved items.
- Mean recall at k: Percentage of all relevant items that were retrieved in the top k results, averaged across all queries in the evaluation dataset.
For our evaluation dataset, we have identified the five most relevant pages for each question, but there might be more that are loosely relevant to the question. So, we are measuring partial recall at k on “known” relevant items.
Additionally, we measure generation quality using a method called “LLM-as-a-judge,” where you use strong LLMs for evaluation by providing them with evaluation rubrics and guidelines via prompts. Here, we use Gemini 2.0 Flash itself to evaluate how aligned its answer is with the human-generated ground truth answer on a scale of 1 to 5, 1 being completely unaligned and 5 being fully aligned.
Refer to the steps under the title Step 10: Evaluating retrieval and generation in the Jupyter Notebook accompanying this tutorial to see the code that defines the metrics above and does the evaluation, but let’s discuss the results here.
In our evaluation dataset, we have separate question sets that can be answered from figures, including tables and text. This allows for a more granular evaluation to understand how well VLM-based and CLIP-based models handle different modalities. The performance of the voyage-multimodal-3 and clip-ViT-B-32 models is summarized in the table below:
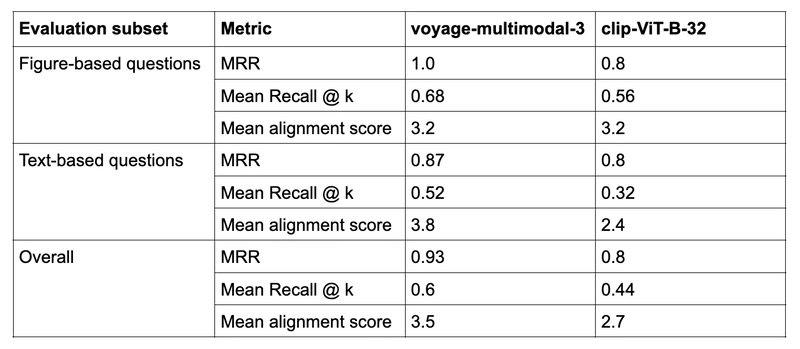
Our evaluation shows that the VLM-based voyage-multimodal-3 outperforms CLIP on both retrieval and generation metrics for our dataset. The model demonstrates superior text comprehension within mixed-modal contexts while maintaining strong visual interpretation capabilities, as is evident by its performance on text and figure-based questions, respectively.
Conclusion
Multimodality in the context of AI is the ability of machine learning models to process, understand, and sometimes generate different types of data, including text, images, audio, video, etc. Multimodal RAG applications require different data processing strategies compared to text-only data and also specialized embedding models and LLMs that can handle different modalities.
In this tutorial, we saw how to build a multimodal RAG application using documents consisting of interleaved text, images, and tables as their source of knowledge, using MongoDB Atlas Vector Search and Voyage AI. We also discussed two different architectures, CLIP and VLMs, for multimodal embedding models, and evaluated how they impact the retrieval and generation quality in our RAG application.
If you enjoyed reading this tutorial, you can explore more such content on our AI Learning Hub. If you want to go straight to code, we have several more examples of how to build RAG, agentic applications, evals, etc., in our Gen AI Showcase GitHub repository. As always, if you have further questions as you build your AI applications, please reach out to us in our Generative AI community forums.