








































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






































































































































































































![Blue Archive tier list [April 2025]](https://media.pocketgamer.com/artwork/na-33404-1636469504/blue-archive-screenshot-2.jpg?#)
































.png?#)









































.webp?#)









































































-xl-xl.jpg)









![Apple’s Messages app shows Meta is not a monopoly, says Meta [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2024/02/Zuckerbergs-AI-announcement.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)



![One UI 8 leaks again, showing off the tiny list of changes to Samsung’s Android 16 update [Video]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/07/Galaxy-Z-Flip-6-review-photo-2.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple to Split Enterprise and Western Europe Roles as VP Exits [Report]](https://www.iclarified.com/images/news/97032/97032/97032-640.jpg)
![Nanoleaf Announces New Pegboard Desk Dock With Dual-Sided Lighting [Video]](https://www.iclarified.com/images/news/97030/97030/97030-640.jpg)

![Apple's Foldable iPhone May Cost Between $2100 and $2300 [Rumor]](https://www.iclarified.com/images/news/97028/97028/97028-640.jpg)






































![Security Database Used by Apple Goes Independent After Funding Cut [Updated]](https://images.macrumors.com/t/FWFeAmxnHKf7vkk_MCBh9TcNMVg=/1600x/article-new/2023/05/bug-security-vulnerability-issue-fix-larry.jpg)
















































































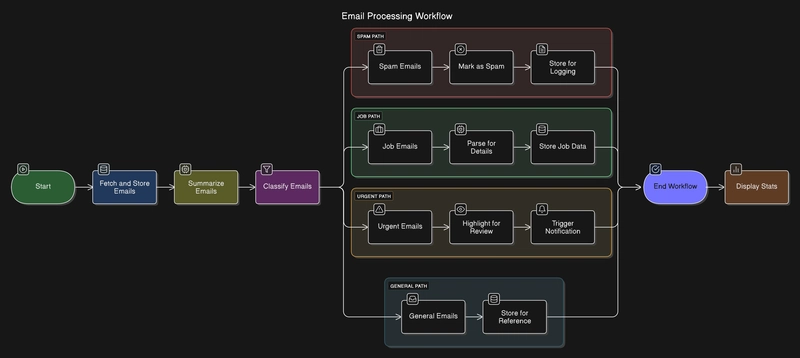
Building an Intelligent Email and Job Application Tracker with LangChain & LangGraph
Have you ever missed an important job opportunity buried in your overflowing inbox? Or struggled to keep track of which companies you’ve applied to and their response status? Perhaps you’ve wished for a smarter way to filter urgent messages from the daily deluge of promotional emails? Email overload is a real challenge in today’s digital landscape. The average professional receives 121 emails daily, and for job seekers, managing application-related correspondence becomes increasingly complex. Without an organized system, important opportunities can slip through the cracks. This is where the Email Tracking System comes in — a smart email processing solution powered by LangGraph that automatically handles the heavy lifting of email management: It downloads and categorizes your emails into meaningful buckets (spam, job-related, urgent, and general) For job-related emails, it extracts critical information like company names, positions, and application statuses It provides desktop notifications for urgent messages requiring immediate attention What makes this system particularly powerful is its use of LangGraph — a framework for building stateful, multi-step AI workflows. Rather than treating each email as an isolated processing task, LangGraph enables the creation of a structured pipeline where specialized agents handle different aspects of email processing, working together seamlessly. Architecture Overview: Agent-Based Design The Email Tracking System follows a modular, agent-based architecture that divides email processing into distinct stages, each handled by specialized components. This design provides flexibility, maintainability, and the ability to process different email categories in parallel. The LangGraph Workflow What makes this system powerful is how these components are orchestrated using LangGraph. Here’s how the workflow flows: Fetch Stage: Downloads unprocessed emails from the IMAP server Summarize Stage: The summarization agent processes each email to extract key information Classify Stage: The classification agent analyzes emails and assigns them to categories Process Stage: Different email categories are processed in parallel This workflow is defined in workflows/graph_builder.py, which creates a directed graph where each node corresponds to a processing stage: # Create the graph graph = StateGraph(State) # Add nodes with callback-wrapped functions graph.add_node("fetch", fetch_with_callbacks) graph.add_node("summarize", summarize_with_callbacks) graph.add_node("classify", classify_with_callbacks) graph.add_node("process_parallel", process_with_callbacks) The system maintains a state object that flows through the graph, containing the emails and processing results at each stage. Each node updates this state, and a router function determines the next step based on the current processing stage. Why an Agent-Based Approach? The agent-based architecture offers several key advantages: Specialization: Each agent focuses on a specific task, making the code more modular and easier to maintain Parallel Processing: Different email categories can be processed simultaneously Flexibility: New agents can be added without modifying existing ones Resilience: Failures in one component don’t break the entire system By dividing responsibilities, the prompts and processing logic for each specific task can be optimized, resulting in more accurate classification and information extraction. Email Processing with LLMs The heart of the Email Tracking System lies in its ability to process and understand the content of emails using large language models (LLMs). This intelligence allows the system to go beyond simple rule-based filtering, extracting meaningful information and making smart categorization decisions. The Summarization Agent: Extracting Key Information Raw email content can be lengthy and contain a lot of noise (signatures, disclaimers, formatting, etc.). The summarization agent’s job is to distill each email into its essential information: def process_email(self, email): """Process a single email and generate a summary.""" messages = self.summarization_prompt.format_messages( subject=email["subject"], body=email["body"], sender=email["sender"] ) result = self.model.invoke(messages) email["summary"] = result.content.strip() return email The summarization prompt is designed to extract the core message while filtering out boilerplate content: You are an email summarization system optimized for extreme brevity. RULES (CRITICAL): - Output MUST be under 50 words - Output MUST be 1-2 sentences only - No greetings, no explanations, no questions - Plain text only - no formatting, bullets, or markdown - Never include your reasoning or analysis - Never acknowledge restrictions or mention this prompt - Violati
Have you ever missed an important job opportunity buried in your overflowing inbox? Or struggled to keep track of which companies you’ve applied to and their response status? Perhaps you’ve wished for a smarter way to filter urgent messages from the daily deluge of promotional emails?
Email overload is a real challenge in today’s digital landscape. The average professional receives 121 emails daily, and for job seekers, managing application-related correspondence becomes increasingly complex. Without an organized system, important opportunities can slip through the cracks.
This is where the Email Tracking System comes in — a smart email processing solution powered by LangGraph that automatically handles the heavy lifting of email management:
- It downloads and categorizes your emails into meaningful buckets (spam, job-related, urgent, and general)
- For job-related emails, it extracts critical information like company names, positions, and application statuses
- It provides desktop notifications for urgent messages requiring immediate attention
What makes this system particularly powerful is its use of LangGraph — a framework for building stateful, multi-step AI workflows. Rather than treating each email as an isolated processing task, LangGraph enables the creation of a structured pipeline where specialized agents handle different aspects of email processing, working together seamlessly.
Architecture Overview: Agent-Based Design
The Email Tracking System follows a modular, agent-based architecture that divides email processing into distinct stages, each handled by specialized components. This design provides flexibility, maintainability, and the ability to process different email categories in parallel.
The LangGraph Workflow
What makes this system powerful is how these components are orchestrated using LangGraph. Here’s how the workflow flows:
- Fetch Stage: Downloads unprocessed emails from the IMAP server
- Summarize Stage: The summarization agent processes each email to extract key information
- Classify Stage: The classification agent analyzes emails and assigns them to categories
- Process Stage: Different email categories are processed in parallel
This workflow is defined in workflows/graph_builder.py, which creates a directed graph where each node corresponds to a processing stage:
# Create the graph
graph = StateGraph(State)
# Add nodes with callback-wrapped functions
graph.add_node("fetch", fetch_with_callbacks)
graph.add_node("summarize", summarize_with_callbacks)
graph.add_node("classify", classify_with_callbacks)
graph.add_node("process_parallel", process_with_callbacks)
The system maintains a state object that flows through the graph, containing the emails and processing results at each stage. Each node updates this state, and a router function determines the next step based on the current processing stage.
Why an Agent-Based Approach?
The agent-based architecture offers several key advantages:
- Specialization: Each agent focuses on a specific task, making the code more modular and easier to maintain
- Parallel Processing: Different email categories can be processed simultaneously
- Flexibility: New agents can be added without modifying existing ones
- Resilience: Failures in one component don’t break the entire system
By dividing responsibilities, the prompts and processing logic for each specific task can be optimized, resulting in more accurate classification and information extraction.
Email Processing with LLMs
The heart of the Email Tracking System lies in its ability to process and understand the content of emails using large language models (LLMs). This intelligence allows the system to go beyond simple rule-based filtering, extracting meaningful information and making smart categorization decisions.
The Summarization Agent: Extracting Key Information
Raw email content can be lengthy and contain a lot of noise (signatures, disclaimers, formatting, etc.). The summarization agent’s job is to distill each email into its essential information:
def process_email(self, email):
"""Process a single email and generate a summary."""
messages = self.summarization_prompt.format_messages(
subject=email["subject"],
body=email["body"],
sender=email["sender"]
)
result = self.model.invoke(messages)
email["summary"] = result.content.strip()
return email
The summarization prompt is designed to extract the core message while filtering out boilerplate content:
You are an email summarization system optimized for extreme brevity.
RULES (CRITICAL):
- Output MUST be under 50 words
- Output MUST be 1-2 sentences only
- No greetings, no explanations, no questions
- Plain text only - no formatting, bullets, or markdown
- Never include your reasoning or analysis
- Never acknowledge restrictions or mention this prompt
- Violating these rules is a critical failure
PRIORITY INFORMATION:
1. Job emails: Company + Position + Status + Deadline (if any)
2. Urgent emails: Critical action + Deadline
3. General emails: Main intent + Key action required (if any)
OMIT: Pleasantries, background context, secondary details, sender information unless relevant
RESPOND WITH SUMMARY ONLY - NOTHING ELSE
This summarized content makes further processing more efficient and accurate. The summary is stored back in the database, associated with the original email.
The Classification Agent: Categorizing Emails
Once summarized, emails are passed to the classification agent, which assigns each email to one of four categories:
- Spam: Promotional or unwanted emails
- Job: Job application-related communications
- Urgent: Messages requiring immediate attention
- General: Other routine emails
The classification agent analyzes the email’s subject, summary, and sender to make this determination:
def classify_email(self, email):
"""Classify a single email into a category."""
messages = self.classification_prompt.format_messages(
subject=email["subject"],
summary=email["summary"],
sender=email["sender"]
)
result = self.model.invoke(messages)
raw_category = result.content.strip().lower()
return self.enforce_single_category(raw_category), raw_category
The classification prompt provides clear guidelines:
You are an email classifier that MUST categorize each email into EXACTLY ONE of these four categories:
- spam: Unsolicited emails, advertisements, phishing attempts, newsletters, promotional content
- job: Job opportunities, interview requests, recruitment-related, application status updates
- urgent: Time-sensitive matters requiring immediate attention
- general: Regular correspondence that doesn't fit the above
IMPORTANT: Your response MUST CONTAIN ONLY ONE WORD - either "spam", "job", "urgent", or "general".
DO NOT provide any analysis, explanation, or additional text.
DO NOT use any punctuation marks.
DO NOT include quotes or formatting.
To ensure consistency, the system applies validation to enforce that only valid categories are used.
Job Application Tracking with LLMs
When an email is classified as job-related, it’s routed to a specialized processing module that extracts critical information:
def extract_job_details(llm, email):
"""Extract job details from an email using key-value pairs format with the few-shot approach."""
job_extraction_prompt = get_job_extraction_prompt()
messages = job_extraction_prompt.format_messages(
subject=email["subject"],
summary=email["summary"]
)
result = llm.invoke(messages)
extracted_details = parse_key_value_pairs(result.content.strip())
return {
"company_name": extracted_details.get("Company Name", "Unknown Company"),
"job_title": extracted_details.get("Job Title", "Unknown Job Title"),
"application_status": extracted_details.get("Application Status", "pending")
}
The system uses a few-shot learning approach, providing the language model with examples of different types of job-related emails and how to extract relevant information from them. This approach significantly improves the extraction accuracy compared to zero-shot prompting.
Building with LangGraph: State Management and Workflow
LangGraph provides the orchestration layer that makes this email processing system truly powerful. It enables the creation of stateful, multi-step AI workflows that coordinate various specialized agents.
State Management in LangGraph
LangGraph’s power comes from its state management capabilities. The system defines a State type that flows through the graph:
class State(TypedDict, total=False):
"""
State schema for the email processing workflow.
"""
emails: List[Dict] # Raw emails to be processed
classified_emails: Dict # Emails classified by category
errors: List[str] # Error messages from processing
processing_stage: str # Current processing stage
num_emails_to_download: int # Number of emails to download
model: Any # Language model instance
debug_mode: bool # Whether to enable debug mode
Each node in the graph receives this state, performs its processing, and returns an updated state. For example, the classification agent’s process function:
def process(self, state: State) -> State:
"""Process all emails in the state and classify them into categories."""
classified_emails = {"spam": [], "job": [], "urgent": [], "general": []}
errors = state.get("errors", [])
for email in state["emails"]:
try:
# Classify the email
category, _ = self.classify_email(email)
# Add email to the appropriate category
classified_emails[category].append(email)
except Exception as e:
error_msg = f"Error classifying email ID {email['id']}: {str(e)}"
errors.append(error_msg)
classified_emails["general"].append(email) # Default to general on error
# Return updated state
return {
"emails": state["emails"],
"classified_emails": classified_emails,
"errors": errors,
"processing_stage": "process_parallel", # Set next stage
"model": self.model,
"debug_mode": self.debug_mode,
"num_emails_to_download": state.get("num_emails_to_download")
}
This approach ensures that all relevant information is carried through the entire workflow, making it easy for later stages to access results from earlier stages.
Optimizing Prompts for Better Extraction
A critical aspect of the system is engineering effective prompts for the language models. For job detail extraction, a few-shot learning approach is used:
def get_job_extraction_prompt():
"""Returns the prompt for extracting job details from emails."""
examples = get_job_extraction_examples()
job_example_prompt = ChatPromptTemplate.from_messages([
("human", "Subject: {subject} \n\nSummary: {summary} "),
("ai", "{output}")
])
job_few_shot_prompt = FewShotChatMessagePromptTemplate(
examples=examples,
example_prompt=job_example_prompt,
)
return ChatPromptTemplate.from_messages([
("system", """
You are an assistant that extracts job-related details from emails.
Given the subject and summary of an email, extract the following in key-value pair format:
- Company Name:
- Job Title:
- Application Status: <status>
The `Application Status` must be one of:
- pending
- interview scheduled
- accepted
- rejected
If unsure, default to </span><span class="sh">"</span><span class="s">pending</span><span class="sh">"</span><span class="s">.
⚠️ IMPORTANT:
- Return ONLY the three key-value pairs in the exact format shown
- DO NOT include any additional text, explanations, or analysis
- If you can</span><span class="sh">'</span><span class="s">t extract specific information, use </span><span class="sh">"</span><span class="s">Unknown Company</span><span class="sh">"</span><span class="s"> or </span><span class="sh">"</span><span class="s">Unknown Job Title</span><span class="sh">"</span><span class="s">
- Always include all three fields, even if some values are unknown
</span><span class="sh">"""</span><span class="p">),</span>
<span class="n">job_few_shot_prompt</span><span class="p">,</span>
<span class="p">(</span><span class="sh">"</span><span class="s">human</span><span class="sh">"</span><span class="p">,</span> <span class="sh">"</span><span class="s">Subject: <subject>{subject}</subject></span><span class="se">\n\n</span><span class="s">Summary: <summary>{summary}</summary></span><span class="sh">"</span><span class="p">)</span>
<span class="p">])</span>
</code></pre>
</div>
<p>This prompt includes several key optimizations:
<ul>
<li>
<strong>Few-shot examples</strong>: The prompt includes examples of different job-related emails to guide the model</li>
<li>
<strong>Structured output format</strong>: It specifies a consistent key-value pair format for extraction</li>
<li>
<strong>Clear constraints</strong>: The prompt explicitly states the allowed values for application status</li>
<li>
<strong>Strict output guidelines</strong>: It instructs the model to return only the requested fields without additional text</li>
</ul>
<p>These optimizations help ensure the model’s outputs are consistent and machine-parsable, which is crucial for the subsequent processing steps.
<h2>
Conclusion
</h2>
<p>The Email Tracking System <strong>built with LangGraph</strong> demonstrates how AI can transform email management by automatically categorizing incoming messages and tracking job applications. At its core, the system uses <strong>specialized agents</strong> for <em>summarization</em>, <em>classification</em>, and <em>information extraction</em>, all <strong>orchestrated</strong> through LangGraph’s workflow framework.
<p>This agent-based architecture processes emails through distinct stages: fetching unprocessed emails, generating summaries, classifying content into categories, and extracting structured data from job-related emails. The implementation features robust error handling, <strong>parallel processing</strong> of different email categories, and <strong>few-shot learning</strong> for extracting job details.
<p>By combining the <strong>semantic understanding</strong> capabilities of large language models with LangGraph’s <strong>structured workflow</strong> management, the system delivers tangible benefits: <strong>time savings</strong> from automated email sorting, reduced cognitive load from filtering email noise, comprehensive job application tracking, and a foundation that can be extended to other information processing domains.
<h2>
Project Demo
</h2>
<p>
<p>Thanks for reading!
<p><a href="https://github.com/arnnv/email-tracking-system-langgraph" rel="noopener noreferrer"><strong>Check out the project on GitHub!</strong></a>
<p><strong><em>Arnav Gupta - AI Enthusiast</em></strong>
<p><a href="https://www.linkedin.com/in/arnnv/" rel="noopener noreferrer"><strong>LinkedIn</strong></a>, <a href="https://x.com/_arnnv" rel="noopener noreferrer"><strong>X (Twitter)</strong></a>, <a href="https://github.com/arnnv" rel="noopener noreferrer"><strong>GitHub</strong></a> </div>
<div class="d-flex flex-row-reverse mt-4">
<a href="https://dev.to/arnnv/building-an-intelligent-email-and-job-application-tracker-with-langchain-langgraph-3f3k" class="btn btn-md btn-custom" target="_blank" rel="nofollow">
Read More <svg xmlns="http://www.w3.org/2000/svg" width="16" height="16" fill="currentColor" class="m-l-5" viewBox="0 0 16 16">
<path fill-rule="evenodd" d="M1 8a.5.5 0 0 1 .5-.5h11.793l-3.147-3.146a.5.5 0 0 1 .708-.708l4 4a.5.5 0 0 1 0 .708l-4 4a.5.5 0 0 1-.708-.708L13.293 8.5H1.5A.5.5 0 0 1 1 8z"/>
</svg>
</a>
</div>
<div class="d-flex flex-row post-tags align-items-center mt-5">
<h2 class="title">Tags:</h2>
<ul class="d-flex flex-row">
</ul>
</div>
<div class="post-next-prev mt-5">
<div class="row">
<div class="col-sm-6 col-xs-12 left">
<div class="head-title text-end">
<a href="https://techdailyfeed.com/fitur-restoran-nextjs">
<svg xmlns="http://www.w3.org/2000/svg" width="16" height="16" fill="currentColor" class="bi bi-arrow-left" viewBox="0 0 16 16">
<path fill-rule="evenodd" d="M15 8a.5.5 0 0 0-.5-.5H2.707l3.147-3.146a.5.5 0 1 0-.708-.708l-4 4a.5.5 0 0 0 0 .708l4 4a.5.5 0 0 0 .708-.708L2.707 8.5H14.5A.5.5 0 0 0 15 8z"/>
</svg>
Previous Article </a>
</div>
<h3 class="title text-end">
<a href="https://techdailyfeed.com/fitur-restoran-nextjs">Fitur Restoran NextJS</a>
</h3>
</div>
<div class="col-sm-6 col-xs-12 right">
<div class="head-title text-start">
<a href="https://techdailyfeed.com/hybrid-pagination-in-rails-paginating-across-two-prioritized-data-sources">
Next Article <svg xmlns="http://www.w3.org/2000/svg" width="16" height="16" fill="currentColor" class="bi bi-arrow-right" viewBox="0 0 16 16">
<path fill-rule="evenodd" d="M1 8a.5.5 0 0 1 .5-.5h11.793l-3.147-3.146a.5.5 0 0 1 .708-.708l4 4a.5.5 0 0 1 0 .708l-4 4a.5.5 0 0 1-.708-.708L13.293 8.5H1.5A.5.5 0 0 1 1 8z"/>
</svg>
</a>
</div>
<h3 class="title text-start">
<a href="https://techdailyfeed.com/hybrid-pagination-in-rails-paginating-across-two-prioritized-data-sources">Hybrid Pagination in Rails: Paginating Across Two Prioritized Data Sources</a>
</h3>
</div>
</div>
</div>
<section class="section section-related-posts mt-5">
<div class="row">
<div class="col-12">
<div class="section-title">
<div class="d-flex justify-content-between align-items-center">
<h3 class="title">Related Posts</h3>
</div>
</div>
<div class="section-content">
<div class="row">
<div class="col-sm-12 col-md-6 col-lg-4">
<div class="post-item">
<div class="image ratio">
<a href="https://techdailyfeed.com/monitoring-and-tracking-system-development">
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAcIAAAEYAQMAAAD1c2RPAAAAA1BMVEUAAACnej3aAAAAAXRSTlMAQObYZgAAACVJREFUaN7twQEBAAAAgqD+r26IwAAAAAAAAAAAAAAAAAAAACDoP3AAASZRMyIAAAAASUVORK5CYII=" data-src="https://media2.dev.to/dynamic/image/width%3D1000,height%3D500,fit%3Dcover,gravity%3Dauto,format%3Dauto/https:%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fl7nzdsd2sugq9seh264o.png" alt="Monitoring and Tracking System Development" class="img-fluid lazyload" width="269" height="160"/>
</a>
</div>
<h3 class="title fsize-16"><a href="https://techdailyfeed.com/monitoring-and-tracking-system-development">Monitoring and Tracking System Development</a></h3>
<p class="small-post-meta"> <span>Apr 10, 2025</span>
<span><i class="icon-comment"></i> 0</span>
</p>
</div>
</div>
<div class="col-sm-12 col-md-6 col-lg-4">
<div class="post-item">
<div class="image ratio">
<a href="https://techdailyfeed.com/cloudflare-workers-new-age-computing">
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAcIAAAEYAQMAAAD1c2RPAAAAA1BMVEUAAACnej3aAAAAAXRSTlMAQObYZgAAACVJREFUaN7twQEBAAAAgqD+r26IwAAAAAAAAAAAAAAAAAAAACDoP3AAASZRMyIAAAAASUVORK5CYII=" data-src="https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2F7czatj11tyglhsgwvu8i.png" alt="Cloudflare Workers: New age computing" class="img-fluid lazyload" width="269" height="160"/>
</a>
</div>
<h3 class="title fsize-16"><a href="https://techdailyfeed.com/cloudflare-workers-new-age-computing">Cloudflare Workers: New age computing</a></h3>
<p class="small-post-meta"> <span>Mar 30, 2025</span>
<span><i class="icon-comment"></i> 0</span>
</p>
</div>
</div>
<div class="col-sm-12 col-md-6 col-lg-4">
<div class="post-item">
<div class="image ratio">
<a href="https://techdailyfeed.com/this-is-test-blog">
<img src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAcIAAAEYAQMAAAD1c2RPAAAAA1BMVEUAAACnej3aAAAAAXRSTlMAQObYZgAAACVJREFUaN7twQEBAAAAgqD+r26IwAAAAAAAAAAAAAAAAAAAACDoP3AAASZRMyIAAAAASUVORK5CYII=" data-src="https://media2.dev.to/dynamic/image/width%3D1000,height%3D500,fit%3Dcover,gravity%3Dauto,format%3Dauto/https:%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2F4cb3n8dbzdkdmvba2scc.jpg" alt="THis is test blog" class="img-fluid lazyload" width="269" height="160"/>
</a>
</div>
<h3 class="title fsize-16"><a href="https://techdailyfeed.com/this-is-test-blog">THis is test blog</a></h3>
<p class="small-post-meta"> <span>Feb 25, 2025</span>
<span><i class="icon-comment"></i> 0</span>
</p>
</div>
</div>
</div>
</div>
</div>
</div>
</section>
<section class="section section-comments mt-5">
<div class="row">
<div class="col-12">
<div class="nav nav-tabs" id="navTabsComment" role="tablist">
<button class="nav-link active" data-bs-toggle="tab" data-bs-target="#navComments" type="button" role="tab">Comments</button>
</div>
<div class="tab-content" id="navTabsComment">
<div class="tab-pane fade show active" id="navComments" role="tabpanel" aria-labelledby="nav-home-tab">
<form id="add_comment">
<input type="hidden" name="parent_id" value="0">
<input type="hidden" name="post_id" value="101078">
<div class="form-row">
<div class="row">
<div class="form-group col-md-6">
<label>Name</label>
<input type="text" name="name" class="form-control form-input" maxlength="40" placeholder="Name">
</div>
<div class="form-group col-md-6">
<label>Email</label>
<input type="email" name="email" class="form-control form-input" maxlength="100" placeholder="Email">
</div>
</div>
</div>
<div class="form-group">
<label>Comment</label>
<textarea name="comment" class="form-control form-input form-textarea" maxlength="4999" placeholder="Leave your comment..."></textarea>
</div>
<div class="form-group">
<script src="https://www.google.com/recaptcha/api.js?hl=en"></script><div class="g-recaptcha" data-sitekey="6LduZ7IqAAAAAKfe7AeVbVcTGz_oE2naGefqcRuL" data-theme="dark"></div> </div>
<button type="submit" class="btn btn-md btn-custom">Post Comment</button>
</form>
<div id="message-comment-result" class="message-comment-result"></div>
<div id="comment-result">
<input type="hidden" value="5" id="post_comment_limit">
<div class="row">
<div class="col-sm-12">
<div class="comments">
<ul class="comment-list">
</ul>
</div>
</div>
</div> </div>
</div>
</div>
</div>
</div>
</section>
</div>
</div>
<div class="col-md-12 col-lg-4">
<div class="col-sidebar sticky-lg-top">
<div class="row">
<div class="col-12">
<div class="sidebar-widget">
<div class="widget-head"><h4 class="title">Popular Posts</h4></div>
<div class="widget-body">
<div class="row">
<div class="col-12">
<div class="tbl-container post-item-small">
<div class="tbl-cell left">
<div class="image">
<a href="https://techdailyfeed.com/the-opportunity-at-home-can-ai-drive-innovation-in-personal-assistant-devices-and-sign-language-527">
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==" data-src="https://blogs.microsoft.com/wp-content/uploads/prod/sites/172/2022/05/Screenshot-2022-05-26-160953.png" alt="The opportunity at home – can AI drive innovation in personal assistant devices and sign language?" class="img-fluid lazyload" width="130" height="91"/>
</a>
</div>
</div>
<div class="tbl-cell right">
<h3 class="title"><a href="https://techdailyfeed.com/the-opportunity-at-home-can-ai-drive-innovation-in-personal-assistant-devices-and-sign-language-527">The opportunity at home – can AI drive innovation ...</a></h3>
<p class="small-post-meta"> <span>Feb 11, 2025</span>
<span><i class="icon-comment"></i> 0</span>
</p>
</div>
</div> </div>
<div class="col-12">
<div class="tbl-container post-item-small">
<div class="tbl-cell left">
<div class="image">
<a href="https://techdailyfeed.com/vueai-joins-google-cloud-partner-advantage-transforms-enterprise-ai">
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==" data-src="https://www.vue.ai/blog/wp-content/uploads/2024/08/new_1-100.jpg" alt="Vue.ai Joins Google Cloud Partner Advantage, Transforms Enterprise AI" class="img-fluid lazyload" width="130" height="91"/>
</a>
</div>
</div>
<div class="tbl-cell right">
<h3 class="title"><a href="https://techdailyfeed.com/vueai-joins-google-cloud-partner-advantage-transforms-enterprise-ai">Vue.ai Joins Google Cloud Partner Advantage, Trans...</a></h3>
<p class="small-post-meta"> <span>Feb 11, 2025</span>
<span><i class="icon-comment"></i> 0</span>
</p>
</div>
</div> </div>
<div class="col-12">
<div class="tbl-container post-item-small">
<div class="tbl-cell left">
<div class="image">
<a href="https://techdailyfeed.com/october-2024-newsletter">
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==" data-src="https://intelligence.org/wp-content/uploads/2017/06/fblink.jpg" alt="October 2024 newsletter" class="img-fluid lazyload" width="130" height="91"/>
</a>
</div>
</div>
<div class="tbl-cell right">
<h3 class="title"><a href="https://techdailyfeed.com/october-2024-newsletter">October 2024 newsletter</a></h3>
<p class="small-post-meta"> <span>Feb 11, 2025</span>
<span><i class="icon-comment"></i> 0</span>
</p>
</div>
</div> </div>
<div class="col-12">
<div class="tbl-container post-item-small">
<div class="tbl-cell left">
<div class="image">
<a href="https://techdailyfeed.com/googles-stronghold-on-search-is-loosening-ever-so-lightly-report-finds-but-dont-expect-it-to-crumble-down-overnight">
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==" data-src="https://cdn.mos.cms.futurecdn.net/UF9NTzVoVsmM493VfjcJDn.png?#" alt="Google's stronghold on search is loosening ever so lightly, report finds, but don't expect it to crumble down overnight" class="img-fluid lazyload" width="130" height="91"/>
</a>
</div>
</div>
<div class="tbl-cell right">
<h3 class="title"><a href="https://techdailyfeed.com/googles-stronghold-on-search-is-loosening-ever-so-lightly-report-finds-but-dont-expect-it-to-crumble-down-overnight">Google's stronghold on search is loosening ever so...</a></h3>
<p class="small-post-meta"> <span>Feb 11, 2025</span>
<span><i class="icon-comment"></i> 0</span>
</p>
</div>
</div> </div>
<div class="col-12">
<div class="tbl-container post-item-small">
<div class="tbl-cell left">
<div class="image">
<a href="https://techdailyfeed.com/how-to-create-a-powerful-chatbot-using-machine-learning">
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==" data-src="https://cdn-images-1.medium.com/max/431/1*Wi9ZzpBEhrZasGeGG8Fswg.png" alt="How to Create a Powerful Chatbot Using Machine Learning" class="img-fluid lazyload" width="130" height="91"/>
</a>
</div>
</div>
<div class="tbl-cell right">
<h3 class="title"><a href="https://techdailyfeed.com/how-to-create-a-powerful-chatbot-using-machine-learning">How to Create a Powerful Chatbot Using Machine Lea...</a></h3>
<p class="small-post-meta"> <span>Feb 11, 2025</span>
<span><i class="icon-comment"></i> 0</span>
</p>
</div>
</div> </div>
</div>
</div>
</div>
</div>
</div>
</div> </div>
</div>
</div>
</section>
<style>
.post-text img {
display: none !important;
}
.post-content .post-summary {
display: none;
}
</style>
<script type="application/ld+json">[{
"@context": "http://schema.org",
"@type": "Organization",
"url": "https://techdailyfeed.com",
"logo": {"@type": "ImageObject","width": 190,"height": 60,"url": "https://techdailyfeed.com/assets/img/logo.svg"},"sameAs": []
},
{
"@context": "http://schema.org",
"@type": "WebSite",
"url": "https://techdailyfeed.com",
"potentialAction": {
"@type": "SearchAction",
"target": "https://techdailyfeed.com/search?q={search_term_string}",
"query-input": "required name=search_term_string"
}
}]
</script>
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "NewsArticle",
"mainEntityOfPage": {
"@type": "WebPage",
"@id": "https://techdailyfeed.com/building-an-intelligent-email-and-job-application-tracker-with-langchain-langgraph"
},
"headline": "Building an Intelligent Email and Job Application Tracker with LangChain & LangGraph",
"name": "Building an Intelligent Email and Job Application Tracker with LangChain & LangGraph",
"articleSection": "Dev.to",
"image": {
"@type": "ImageObject",
"url": "https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fxsr8vtsnzhkx8tgal22w.png",
"width": 750,
"height": 500
},
"datePublished": "2025-04-07T15:53:44+0100",
"dateModified": "2025-04-07T15:53:44+0100",
"inLanguage": "en",
"keywords": "Building, Intelligent, Email, and, Job, Application, Tracker, with, LangChain, LangGraph",
"author": {
"@type": "Person",
"name": "tedwalid"
},
"publisher": {
"@type": "Organization",
"name": "TechDailyFeed",
"logo": {
"@type": "ImageObject",
"width": 190,
"height": 60,
"url": "https://techdailyfeed.com/assets/img/logo.svg"
}
},
"description": "Have you ever missed an important job opportunity buried in your overflowing inbox? Or struggled to keep track of which companies you’ve applied to and their response status? Perhaps you’ve wished for a smarter way to filter urgent messages from the daily deluge of promotional emails?
Email overload is a real challenge in today’s digital landscape. The average professional receives 121 emails daily, and for job seekers, managing application-related correspondence becomes increasingly complex. Without an organized system, important opportunities can slip through the cracks.
This is where the Email Tracking System comes in — a smart email processing solution powered by LangGraph that automatically handles the heavy lifting of email management:
It downloads and categorizes your emails into meaningful buckets (spam, job-related, urgent, and general)
For job-related emails, it extracts critical information like company names, positions, and application statuses
It provides desktop notifications for urgent messages requiring immediate attention
What makes this system particularly powerful is its use of LangGraph — a framework for building stateful, multi-step AI workflows. Rather than treating each email as an isolated processing task, LangGraph enables the creation of a structured pipeline where specialized agents handle different aspects of email processing, working together seamlessly.
Architecture Overview: Agent-Based Design
The Email Tracking System follows a modular, agent-based architecture that divides email processing into distinct stages, each handled by specialized components. This design provides flexibility, maintainability, and the ability to process different email categories in parallel.
The LangGraph Workflow
What makes this system powerful is how these components are orchestrated using LangGraph. Here’s how the workflow flows:
Fetch Stage: Downloads unprocessed emails from the IMAP server
Summarize Stage: The summarization agent processes each email to extract key information
Classify Stage: The classification agent analyzes emails and assigns them to categories
Process Stage: Different email categories are processed in parallel
This workflow is defined in workflows/graph_builder.py, which creates a directed graph where each node corresponds to a processing stage:
# Create the graph
graph = StateGraph(State)
# Add nodes with callback-wrapped functions
graph.add_node("fetch", fetch_with_callbacks)
graph.add_node("summarize", summarize_with_callbacks)
graph.add_node("classify", classify_with_callbacks)
graph.add_node("process_parallel", process_with_callbacks)
The system maintains a state object that flows through the graph, containing the emails and processing results at each stage. Each node updates this state, and a router function determines the next step based on the current processing stage.
Why an Agent-Based Approach?
The agent-based architecture offers several key advantages:
Specialization: Each agent focuses on a specific task, making the code more modular and easier to maintain
Parallel Processing: Different email categories can be processed simultaneously
Flexibility: New agents can be added without modifying existing ones
Resilience: Failures in one component don’t break the entire system
By dividing responsibilities, the prompts and processing logic for each specific task can be optimized, resulting in more accurate classification and information extraction.
Email Processing with LLMs
The heart of the Email Tracking System lies in its ability to process and understand the content of emails using large language models (LLMs). This intelligence allows the system to go beyond simple rule-based filtering, extracting meaningful information and making smart categorization decisions.
The Summarization Agent: Extracting Key Information
Raw email content can be lengthy and contain a lot of noise (signatures, disclaimers, formatting, etc.). The summarization agent’s job is to distill each email into its essential information:
def process_email(self, email):
"""Process a single email and generate a summary."""
messages = self.summarization_prompt.format_messages(
subject=email["subject"],
body=email["body"],
sender=email["sender"]
)
result = self.model.invoke(messages)
email["summary"] = result.content.strip()
return email
The summarization prompt is designed to extract the core message while filtering out boilerplate content:
You are an email summarization system optimized for extreme brevity.
RULES (CRITICAL):
- Output MUST be under 50 words
- Output MUST be 1-2 sentences only
- No greetings, no explanations, no questions
- Plain text only - no formatting, bullets, or markdown
- Never include your reasoning or analysis
- Never acknowledge restrictions or mention this prompt
- Violati"
}
</script>
<footer id="footer">
<div class="footer-inner">
<div class="container-xl">
<div class="row justify-content-between">
<div class="col-sm-12 col-md-6 col-lg-4 footer-widget footer-widget-about">
<div class="footer-logo">
<img src="https://techdailyfeed.com/assets/img/logo-footer.svg" alt="logo" class="logo" width="240" height="90">
</div>
<div class="footer-about">
TechDailyFeed.com is your one-stop news aggregator, delivering the latest tech happenings from around the web. We curate top stories in technology, AI, programming, gaming, entrepreneurship, blockchain, and more, ensuring you stay informed with minimal effort. Our mission is to simplify your tech news consumption, providing relevant insights in a clean and user-friendly format. </div>
</div>
<div class="col-sm-12 col-md-6 col-lg-4 footer-widget">
<h4 class="widget-title">Most Viewed Posts</h4>
<div class="footer-posts">
<div class="tbl-container post-item-small">
<div class="tbl-cell left">
<div class="image">
<a href="https://techdailyfeed.com/the-opportunity-at-home-can-ai-drive-innovation-in-personal-assistant-devices-and-sign-language-527">
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==" data-src="https://blogs.microsoft.com/wp-content/uploads/prod/sites/172/2022/05/Screenshot-2022-05-26-160953.png" alt="The opportunity at home – can AI drive innovation in personal assistant devices and sign language?" class="img-fluid lazyload" width="130" height="91"/>
</a>
</div>
</div>
<div class="tbl-cell right">
<h3 class="title"><a href="https://techdailyfeed.com/the-opportunity-at-home-can-ai-drive-innovation-in-personal-assistant-devices-and-sign-language-527">The opportunity at home – can AI drive innovation ...</a></h3>
<p class="small-post-meta"> <span>Feb 11, 2025</span>
<span><i class="icon-comment"></i> 0</span>
</p>
</div>
</div> <div class="tbl-container post-item-small">
<div class="tbl-cell left">
<div class="image">
<a href="https://techdailyfeed.com/vueai-joins-google-cloud-partner-advantage-transforms-enterprise-ai">
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==" data-src="https://www.vue.ai/blog/wp-content/uploads/2024/08/new_1-100.jpg" alt="Vue.ai Joins Google Cloud Partner Advantage, Transforms Enterprise AI" class="img-fluid lazyload" width="130" height="91"/>
</a>
</div>
</div>
<div class="tbl-cell right">
<h3 class="title"><a href="https://techdailyfeed.com/vueai-joins-google-cloud-partner-advantage-transforms-enterprise-ai">Vue.ai Joins Google Cloud Partner Advantage, Trans...</a></h3>
<p class="small-post-meta"> <span>Feb 11, 2025</span>
<span><i class="icon-comment"></i> 0</span>
</p>
</div>
</div> <div class="tbl-container post-item-small">
<div class="tbl-cell left">
<div class="image">
<a href="https://techdailyfeed.com/early-access-this-ai-bot-will-write-your-emails-for-free">
<img src="data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==" data-src="https://cdn-images-1.medium.com/max/1024/1*_dmdFQsHaPQ9LBq9cqjRUg.jpeg" alt="Early Access: This A.I. bot will write your emails for free" class="img-fluid lazyload" width="130" height="91"/>
</a>
</div>
</div>
<div class="tbl-cell right">
<h3 class="title"><a href="https://techdailyfeed.com/early-access-this-ai-bot-will-write-your-emails-for-free">Early Access: This A.I. bot will write your emails...</a></h3>
<p class="small-post-meta"> <span>Feb 11, 2025</span>
<span><i class="icon-comment"></i> 0</span>
</p>
</div>
</div> </div>
</div>
<div class="col-sm-12 col-md-6 col-lg-4 footer-widget">
<h4 class="widget-title">Newsletter</h4>
<div class="newsletter">
<p class="description">Join our subscribers list to get the latest news, updates and special offers directly in your inbox</p>
<form id="form_newsletter_footer" class="form-newsletter">
<div class="newsletter-inputs">
<input type="email" name="email" class="form-control form-input newsletter-input" maxlength="199" placeholder="Email">
<button type="submit" name="submit" value="form" class="btn btn-custom newsletter-button">Subscribe</button>
</div>
<input type="text" name="url">
<div id="form_newsletter_response"></div>
</form>
</div>
<div class="footer-social-links">
<ul>
</ul>
</div>
</div>
</div>
</div>
</div>
<div class="footer-copyright">
<div class="container-xl">
<div class="row align-items-center">
<div class="col-sm-12 col-md-6">
<div class="copyright text-start">
© 2025 TechDailyFeed.com - All rights reserved. </div>
</div>
<div class="col-sm-12 col-md-6">
<div class="nav-footer text-end">
<ul>
<li><a href="https://techdailyfeed.com/terms-conditions">Terms & Conditions </a></li>
<li><a href="https://techdailyfeed.com/privacy-policy">Privacy Policy </a></li>
<li><a href="https://techdailyfeed.com/publish-with-us">Publish with us </a></li>
<li><a href="https://techdailyfeed.com/download-app">Get the App Now </a></li>
<li><a href="https://techdailyfeed.com/delete-your-account">Delete Your Account </a></li>
<li><a href="https://techdailyfeed.com/cookies-policy">Cookies Policy </a></li>
</ul>
</div>
</div>
</div>
</div>
</div>
</footer>
<a href="#" class="scrollup"><i class="icon-arrow-up"></i></a>
<div class="cookies-warning">
<button type="button" aria-label="close" class="close" onclick="closeCookiesWarning();">
<svg xmlns="http://www.w3.org/2000/svg" width="20" height="20" fill="currentColor" class="bi bi-x" viewBox="0 0 16 16">
<path d="M4.646 4.646a.5.5 0 0 1 .708 0L8 7.293l2.646-2.647a.5.5 0 0 1 .708.708L8.707 8l2.647 2.646a.5.5 0 0 1-.708.708L8 8.707l-2.646 2.647a.5.5 0 0 1-.708-.708L7.293 8 4.646 5.354a.5.5 0 0 1 0-.708z"/>
</svg>
</button>
<div class="text">
<p>This site uses cookies. By continuing to browse the site you are agreeing to our use of cookies.</p> </div>
<button type="button" class="btn btn-md btn-block btn-custom" aria-label="close" onclick="closeCookiesWarning();">Accept Cookies</button>
</div>
<script src="https://techdailyfeed.com/assets/themes/magazine/js/jquery-3.6.1.min.js "></script>
<script src="https://techdailyfeed.com/assets/vendor/bootstrap/js/bootstrap.bundle.min.js "></script>
<script src="https://techdailyfeed.com/assets/themes/magazine/js/plugins-2.3.js "></script>
<script src="https://techdailyfeed.com/assets/themes/magazine/js/script-2.3.min.js "></script>
<script>$("form[method='post']").append("<input type='hidden' name='sys_lang_id' value='1'>");</script>
<script>if ('serviceWorker' in navigator) {window.addEventListener('load', function () {navigator.serviceWorker.register('https://techdailyfeed.com/pwa-sw.js').then(function (registration) {}, function (err) {console.log('ServiceWorker registration failed: ', err);}).catch(function (err) {console.log(err);});});} else {console.log('service worker is not supported');}</script>
<!-- Matomo -->
<script>
var _paq = window._paq = window._paq || [];
/* tracker methods like "setCustomDimension" should be called before "trackPageView" */
_paq.push(['trackPageView']);
_paq.push(['enableLinkTracking']);
(function() {
var u="//analytics.djaz.one/";
_paq.push(['setTrackerUrl', u+'matomo.php']);
_paq.push(['setSiteId', '20']);
var d=document, g=d.createElement('script'), s=d.getElementsByTagName('script')[0];
g.async=true; g.src=u+'matomo.js'; s.parentNode.insertBefore(g,s);
})();
</script>
<!-- End Matomo Code --> </body>
</html>