![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)




































































































































































































![Blue Archive tier list [April 2025]](https://media.pocketgamer.com/artwork/na-33404-1636469504/blue-archive-screenshot-2.jpg?#)






























.png?#)








.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)































.webp?#)

















































































![[Update: Optional] Google rolling out auto-restart security feature to Android](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-2.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Vision 'Air' Headset May Feature Titanium and iPhone 5-Era Black Finish [Rumor]](https://www.iclarified.com/images/news/97040/97040/97040-640.jpg)


![Apple to Split Enterprise and Western Europe Roles as VP Exits [Report]](https://www.iclarified.com/images/news/97032/97032/97032-640.jpg)






















































































































AWS Cloud Architecture for a Multi-Vendor Stock Image Marketplace
I’ve been building a multi-vendor marketplace on AWS called Vectopus.com. This post shares how I handled cloud architecture, CI/CD, and high-volume image/product ingestion — keeping costs as low as possible without sacrificing performance and reliability. In this series of posts, I want to share some of what I learned building the site. I will talk about the architecture, the tech stack, and some of the more interesting challenges and solutions. I will also share some of the business lessons, and, because I think they are equally valuable lessons, some of the missteps - decisions I’d make differently if I were to start over. The Tech Stack We’re funding Vectopus.com out of our own pockets, so every decision has minimized cost without sacrificing too much performance and reliability. That’s true for all businesses, but when you’re bootstrapping, you often have to make trade-offs between cost and convenience. In some cases, we’ve opted for less convenience in order to save money. For instance, we started off hosting the Next.js front-end on Vercel, which is a great service and makes hosting Next.js apps incredibly easy. But we found that the cost, while perfectly reasonable for what Vercel offers, wasn’t sustainable for us at our scale and budget. We moved the front-end to AWS Lightsail, which allowed us to save quite a bit of money. The trade-off is that we have to maintain our own CI/CD pipeline and manage some of the underlying system ourselves, but we can easily scale up or migrate to a more powerful instance if we need to, and we benefit from AWS's security. We Dockerized the front-end and set up a custom GitHub Actions CI/CD workflow attached to our develop and main branches. When we commit to either branch, the appropriate workflow is triggered and the code is deployed to the Lightsail instance. We keep three Docker images available at all times, so if a deployment fails, we can roll back to the last good image. When a new build is deployed, the oldest Docker image is removed, and the new image is tagged as latest. Our development environment uses Lightsail + Docker for both front-end and back-end since performance is not an issue. The production front-end is also Dockerized on an AWS Lightsail instance behind a CloudFront CDN + WAF. The production back-end is hosted on AWS EC2 and is also Dockerized to make sure the underlying operating system version and other dependencies are consistent across all environments. We use Nginx as a reverse proxy to route incoming traffic to the appropriate Docker container. We can use Nginx, WAF, and our Load Balancer to filter out malicious or harmful traffic by IP address, user agent, and other criteria. We built the back-end REST API using Express.js + PostgreSQL (hosted on AWS RDS), and Objection.js as the ORM. The API runs behind an AWS Application Load Balancer with a hot/cold standby setup in case of failure. We use ElasticSearch (hosted by Elastic.co) for search, and Logstash (running on an EC2 instance) to ingest product data, set up as Postgresql views, from the database. For file storage, we use AWS S3 to handle the 650,000+ (and growing) SVG files, multiple PNG and WebP previews, and ZIP archived downloadable products. We use CloudWatch for logging and monitoring, and AWS EventBridge to trigger events in the back-end. We also use AWS SQS for asynchronous processing of images and other tasks, and AWS SNS for notifications. Image Ingestion Pipeline (Serverless) Our product/image ingestion pipeline runs as a serverless application built with AWS EventBridge, Lambda, S3, SQS, and SNS. When contributors upload their icon and illustration sets, the process kicks off asynchronously, processing the images in the background without blocking the user experience. Images are uploaded to S3 as a ZIP archive with a JSON manifest containing relevant metadata. The S3 bucket triggers a Lambda function (ImageBatcher) that extracts the archive, creates a new product (Icon or Illustration Set) in the database, and sends each individual image + metadata to an SQS queue (ImageProcessor queue). A second delayed message is sent to another SQS queue (PreviewMaker queue). I'll explain this second queue in a moment. The ImageProcessor queue triggers a second Lambda (ImageProcessor) that creates multiple image previews in various sizes and formats (WebP and PNG), then inserts the individual images and icon or illustration product data into the database. The PreviewMaker queue triggers the PreviewMaker Lambda after a 120-second delay to let the individual images time to finish processing. The PreviewMaker creates updated preview images for the Family the new icons and illustrations belong to. It does this by randomly selecting a configurable number of images from all of the icons and illustrations from all of the Sets in that product Family. The entire process — minus the 2-minute delay — takes under a minute. Typically by the time the user finishe
I’ve been building a multi-vendor marketplace on AWS called Vectopus.com. This post shares how I handled cloud architecture, CI/CD, and high-volume image/product ingestion — keeping costs as low as possible without sacrificing performance and reliability.
In this series of posts, I want to share some of what I learned building the site. I will talk about the architecture, the tech stack, and some of the more interesting challenges and solutions. I will also share some of the business lessons, and, because I think they are equally valuable lessons, some of the missteps - decisions I’d make differently if I were to start over.
The Tech Stack
We’re funding Vectopus.com out of our own pockets, so every decision has minimized cost without sacrificing too much performance and reliability. That’s true for all businesses, but when you’re bootstrapping, you often have to make trade-offs between cost and convenience. In some cases, we’ve opted for less convenience in order to save money.
For instance, we started off hosting the Next.js front-end on Vercel, which is a great service and makes hosting Next.js apps incredibly easy. But we found that the cost, while perfectly reasonable for what Vercel offers, wasn’t sustainable for us at our scale and budget. We moved the front-end to AWS Lightsail, which allowed us to save quite a bit of money. The trade-off is that we have to maintain our own CI/CD pipeline and manage some of the underlying system ourselves, but we can easily scale up or migrate to a more powerful instance if we need to, and we benefit from AWS's security.
We Dockerized the front-end and set up a custom GitHub Actions CI/CD workflow attached to our develop and main branches. When we commit to either branch, the appropriate workflow is triggered and the code is deployed to the Lightsail instance. We keep three Docker images available at all times, so if a deployment fails, we can roll back to the last good image. When a new build is deployed, the oldest Docker image is removed, and the new image is tagged as latest.
Our development environment uses Lightsail + Docker for both front-end and back-end since performance is not an issue. The production front-end is also Dockerized on an AWS Lightsail instance behind a CloudFront CDN + WAF. The production back-end is hosted on AWS EC2 and is also Dockerized to make sure the underlying operating system version and other dependencies are consistent across all environments. We use Nginx as a reverse proxy to route incoming traffic to the appropriate Docker container. We can use Nginx, WAF, and our Load Balancer to filter out malicious or harmful traffic by IP address, user agent, and other criteria.
We built the back-end REST API using Express.js + PostgreSQL (hosted on AWS RDS), and Objection.js as the ORM. The API runs behind an AWS Application Load Balancer with a hot/cold standby setup in case of failure. We use ElasticSearch (hosted by Elastic.co) for search, and Logstash (running on an EC2 instance) to ingest product data, set up as Postgresql views, from the database.
For file storage, we use AWS S3 to handle the 650,000+ (and growing) SVG files, multiple PNG and WebP previews, and ZIP archived downloadable products. We use CloudWatch for logging and monitoring, and AWS EventBridge to trigger events in the back-end. We also use AWS SQS for asynchronous processing of images and other tasks, and AWS SNS for notifications.
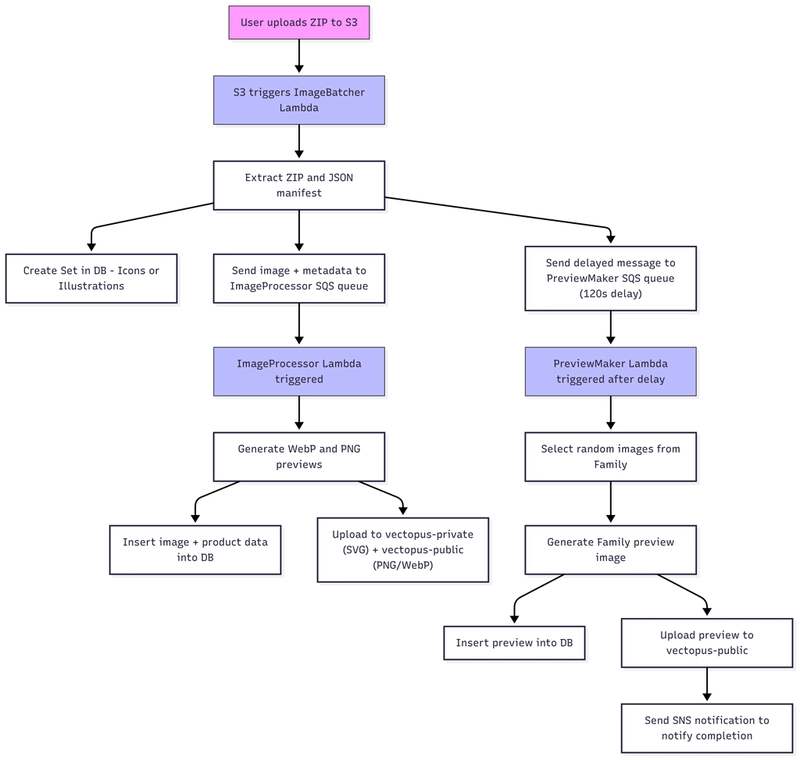
Image Ingestion Pipeline (Serverless)
Our product/image ingestion pipeline runs as a serverless application built with AWS EventBridge, Lambda, S3, SQS, and SNS. When contributors upload their icon and illustration sets, the process kicks off asynchronously, processing the images in the background without blocking the user experience.
Images are uploaded to S3 as a ZIP archive with a JSON manifest containing relevant metadata. The S3 bucket triggers a Lambda function (ImageBatcher) that extracts the archive, creates a new product (Icon or Illustration Set) in the database, and sends each individual image + metadata to an SQS queue (ImageProcessor queue). A second delayed message is sent to another SQS queue (PreviewMaker queue). I'll explain this second queue in a moment.
The ImageProcessor queue triggers a second Lambda (ImageProcessor) that creates multiple image previews in various sizes and formats (WebP and PNG), then inserts the individual images and icon or illustration product data into the database.
The PreviewMaker queue triggers the PreviewMaker Lambda after a 120-second delay to let the individual images time to finish processing. The PreviewMaker creates updated preview images for the Family the new icons and illustrations belong to. It does this by randomly selecting a configurable number of images from all of the icons and illustrations from all of the Sets in that product Family. The entire process — minus the 2-minute delay — takes under a minute. Typically by the time the user finishes creating the new product in the Contributor UI, the images are already processed and ready to display.
Why Serverless?
The event-driven design of the serverless app gives us a scalable, adjustable, and observable architecture that can process a large number of images concurrently without performance degradation. I love this pattern and have leveraged it on several projects. It’s insanely scalable and can be extended using AWS Step Functions for more complex workflows with configurable retries and error handling. Notifications can be sent to Slack, email, or other services. CloudWatch can also be used for monitoring, alerting, and detailed logging.
Up Next: WebP at Scale — The Image Processor
In the next post, I’ll share how we tackled a problem that came back to bite us because we skipped WebP preview generation at launch to save time. A few months later, when we started working on SEO and performance optimization, we needed to retroactively generate millions of WebP files from existing SVGs. I’ll walk through how we benchmarked Node, Python, and Go - and why we ultimately built a threaded CLI batch processor in Go that turned a multi-day job into one that took less than an hour. It’s a good example of how taking a step back, challenging assumptions and doing the math can ultimately save a lot of time.