












































































































































































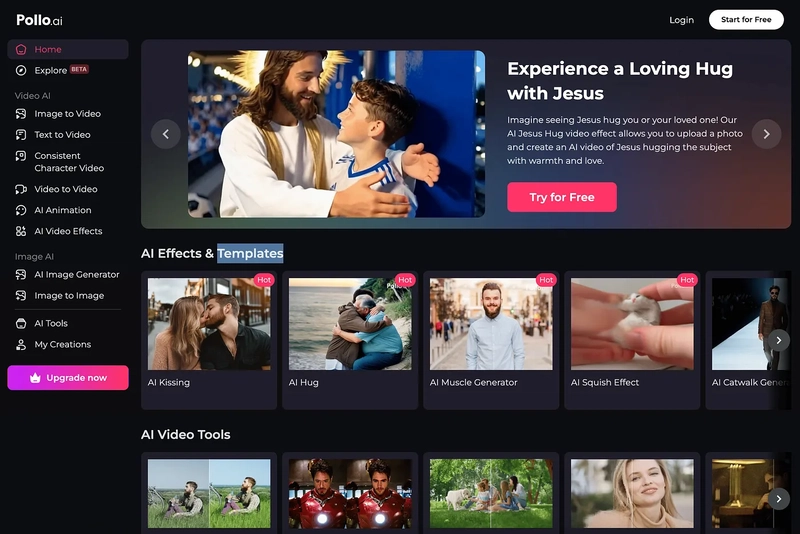
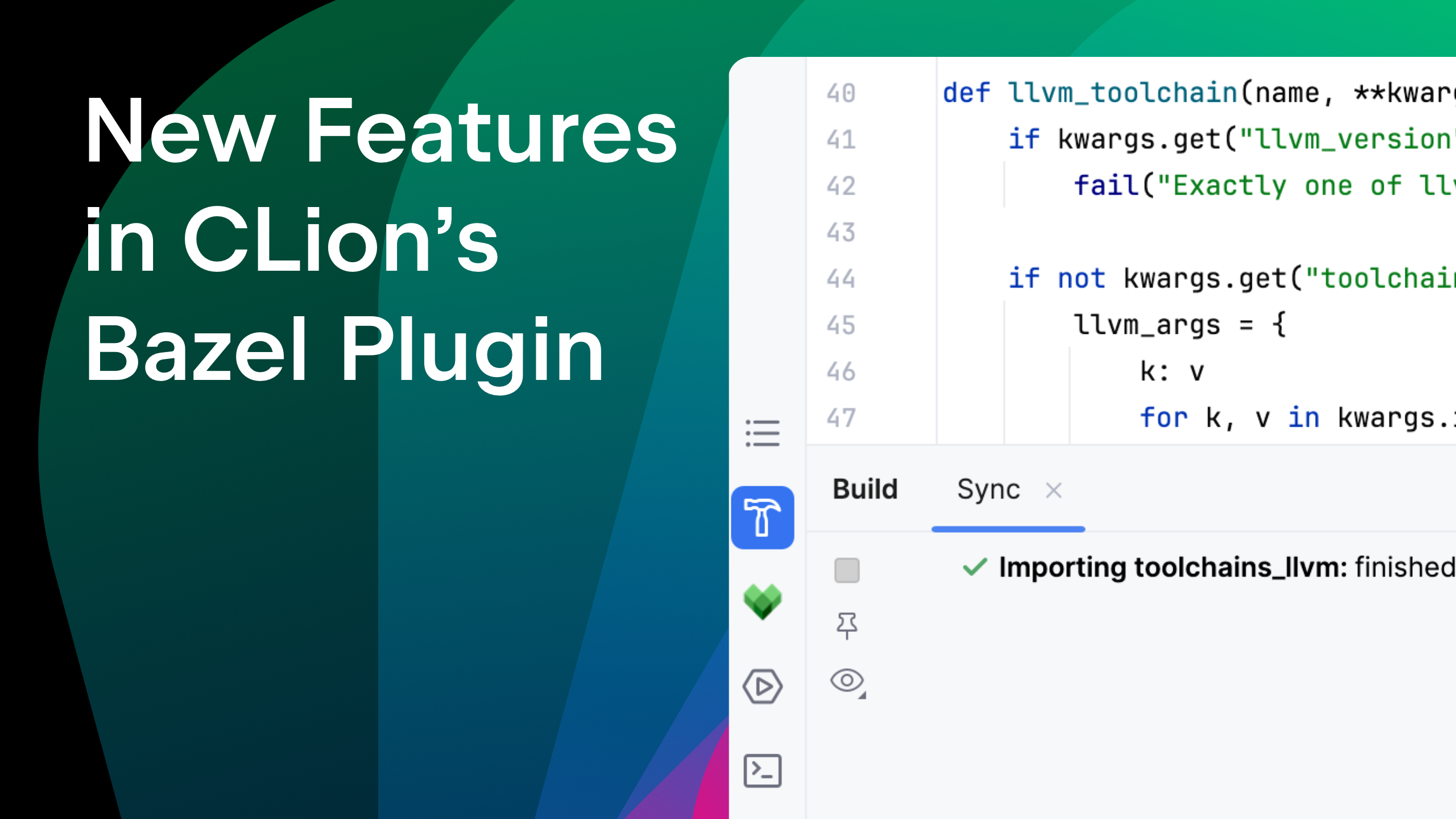
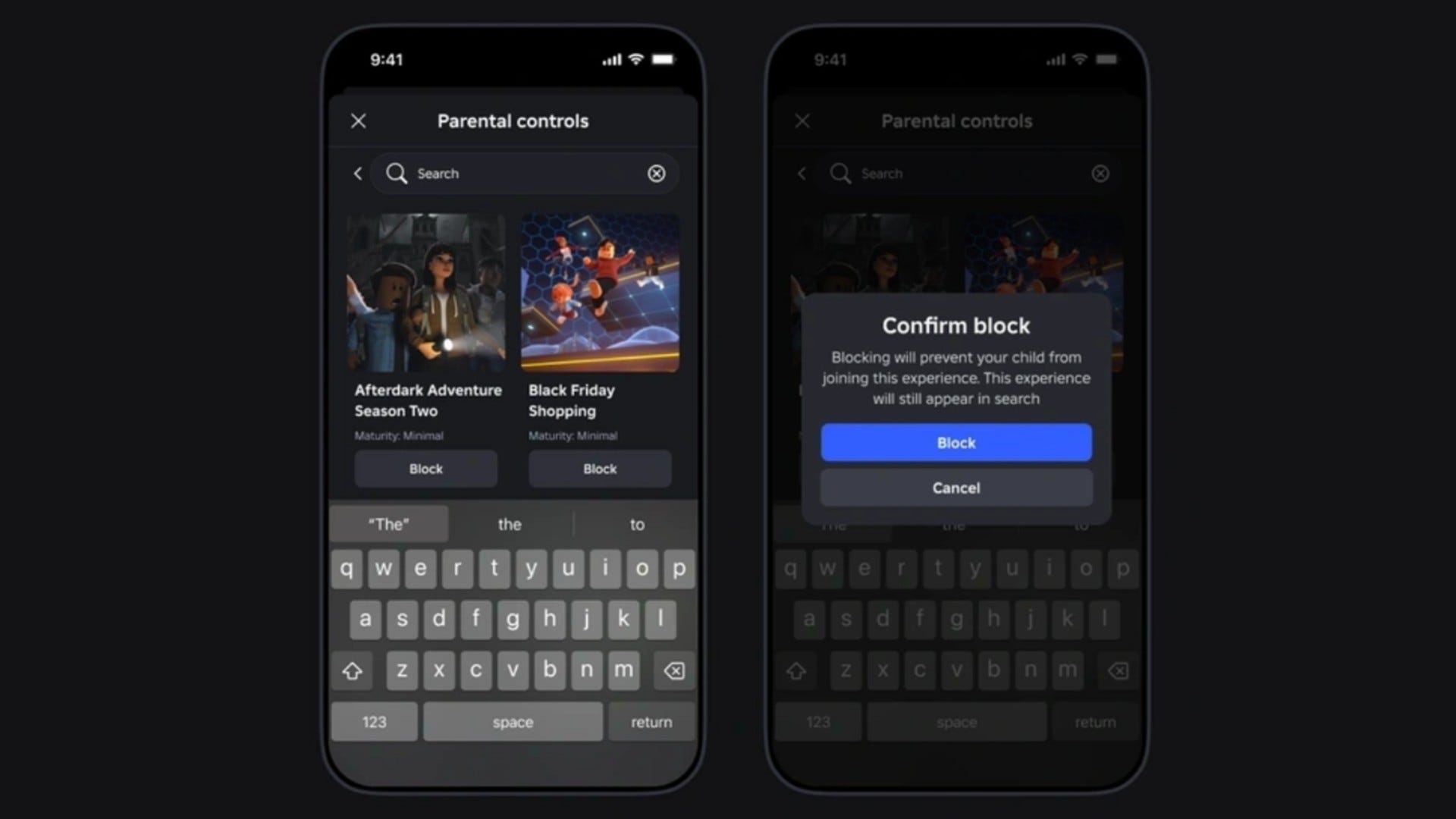
![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)












































































































































































































































































_Anthony_Brown_Alamy.jpg?#)
_Hanna_Kuprevich_Alamy.jpg?#)




.png?#)





















































































![Hands-on: We got to play Nintendo Switch 2 for nearly six hours yesterday [Video]](https://i0.wp.com/9to5toys.com/wp-content/uploads/sites/5/2025/04/Switch-FI-.jpg.jpg?resize=1200%2C628&ssl=1)














![YouTube Announces New Creation Tools for Shorts [Video]](https://www.iclarified.com/images/news/96923/96923/96923-640.jpg)

![Apple Faces New Tariffs but Has Options to Soften the Blow [Kuo]](https://www.iclarified.com/images/news/96921/96921/96921-640.jpg)























































































































An AI Watchdog accused OpenAI of using copyrighted books without permission
An artificial intelligence watchdog is accusing OpenAI of training its default ChatGPT model on copyrighted book content without permission. In a new paper published this week, the AI Disclosures Project alleges that OpenAI likely trained its GPT-4o model using non-public material from O’Reilly Media. The researchers used a legally obtained dataset of 34 copyrighted O’Reilly books and found that GPT-4o showed “strong recognition” of the company’s paywalled content. By contrast, GPT-3.5 Turbo appeared more familiar with publicly accessible O’Reilly book samples. “These results highlight the urgent need for increased corporate transparency regarding pre-training data sources as a means to develop formal licensing frameworks for AI content training,” the authors wrote in the paper. One of the nonprofit’s founders and paper’s authors, Tim O’Reilly, is the CEO of O’Reilly Media. An OpenAI spokesperson didn’t immediately respond to Fast Company‘s request for comment. Training data lies at the heart of all artificial intelligence models. Large language models require an incredible amount of information that it uses to guide back on when it churns out text or images for users. OpenAI has struck up some licensing deals to be able to train their models on certain content. But the company, which recently fundraised and is worth $300 billion, has also come under fire for sourcing certain content. The New York Times, for example, is leading a charge against OpenAI and minority owner Microsoft over alleged copyright infringement. The researchers acknowledged limitations in their study but argued the issue is likely part of a broader systemic problem in how large language models are developed. “Sustainable ecosystems need to be designed so that both creators and developers can benefit from generative AI,” the authors said. “Otherwise, model developers are likely to rapidly plateau in their progress, especially as newer content becomes produced less and less by humans.”

An artificial intelligence watchdog is accusing OpenAI of training its default ChatGPT model on copyrighted book content without permission.
In a new paper published this week, the AI Disclosures Project alleges that OpenAI likely trained its GPT-4o model using non-public material from O’Reilly Media. The researchers used a legally obtained dataset of 34 copyrighted O’Reilly books and found that GPT-4o showed “strong recognition” of the company’s paywalled content. By contrast, GPT-3.5 Turbo appeared more familiar with publicly accessible O’Reilly book samples.
“These results highlight the urgent need for increased corporate transparency regarding pre-training data sources as a means to develop formal licensing frameworks for AI content training,” the authors wrote in the paper. One of the nonprofit’s founders and paper’s authors, Tim O’Reilly, is the CEO of O’Reilly Media.
An OpenAI spokesperson didn’t immediately respond to Fast Company‘s request for comment.
Training data lies at the heart of all artificial intelligence models. Large language models require an incredible amount of information that it uses to guide back on when it churns out text or images for users.
OpenAI has struck up some licensing deals to be able to train their models on certain content. But the company, which recently fundraised and is worth $300 billion, has also come under fire for sourcing certain content. The New York Times, for example, is leading a charge against OpenAI and minority owner Microsoft over alleged copyright infringement.
The researchers acknowledged limitations in their study but argued the issue is likely part of a broader systemic problem in how large language models are developed.
“Sustainable ecosystems need to be designed so that both creators and developers can benefit from generative AI,” the authors said. “Otherwise, model developers are likely to rapidly plateau in their progress, especially as newer content becomes produced less and less by humans.”




