![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)







































































































































































































![Blue Archive tier list [April 2025]](https://media.pocketgamer.com/artwork/na-33404-1636469504/blue-archive-screenshot-2.jpg?#)





























.png?#)











-Baldur’s-Gate-3-The-Final-Patch---An-Animated-Short-00-03-43.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

































































































































![Apple's Foldable iPhone May Cost Between $2100 and $2300 [Rumor]](https://www.iclarified.com/images/news/97028/97028/97028-640.jpg)
![Apple Releases Public Betas of iOS 18.5, iPadOS 18.5, macOS Sequoia 15.5 [Download]](https://www.iclarified.com/images/news/97024/97024/97024-640.jpg)
![Apple to Launch In-Store Recycling Promotion Tomorrow, Up to $20 Off Accessories [Gurman]](https://www.iclarified.com/images/news/97023/97023/97023-640.jpg)
























































































































Amazon S3 Object Lambda
What is an Object Lambda ? S3 Object Lambda is a new feature that lets you customize how data from Amazon S3 is handled before it’s sent back to your application. This means you can process and change the data using your own code without having to modify your application. It works by using AWS Lambda functions to automatically process the data each time it’s fetched from S3. This way, you can easily create different versions or views of your data without changing your app, and you can update how the data is processed whenever you need to. How to setup s3 object lambda Step 1: First, we will create an access point for S3 bucket Go to your S3 bucket and open access points We will have to create a bucket access point Name you access point and select internet in network origin Step 2: Create Lambda import boto3 import requests import pandas as pd def lambda_handler(event, context): print(event) object_get_context = event["getObjectContext"] request_route = object_get_context["outputRoute"] request_token = object_get_context["outputToken"] s3_url = object_get_context["inputS3Url"] # Get object from S3 response = requests.get(s3_url) original_object = response.content.decode('utf-8') # Transform object columns = original_object.split('\r\n')[0].replace('"','').replace('\ufeff','').split(',') user_data = [] for data in original_object.split('\r\n')[1:-1] : user_data.append(data.replace('"','').split(',')) user_df = pd.DataFrame(user_data,columns=columns) user_df.drop(columns=['password'],inplace=True) # Write object back to S3 Object Lambda s3 = boto3.client('s3') s3.write_get_object_response( Body=bytes(user_df.to_csv(index=False),encoding = 'utf-8'), RequestRoute=request_route, RequestToken=request_token) return {'status_code': 200} Step 3: Create object lambda access points from left hand side menu of S3 Click on ‘Create Object Lambda Access Point’ Select your bucket access point Select all transformation Select Lambda that you have created above Leave other things as default. Step 4: Get object using boto3 Csv Data : Copy the below data and store it in csv file with name user_daily_data.csv id,email,username,password,name__firstname,name__lastname,phone,__v,address__geolocation__lat,address__geolocation__long,address__city,address__street,address__number,address__zipcode 1,sarahreyes@example.org,cameronrobert,&RnzRNczN6,Tracy,Doyle,9-087-607-2043,0,-81.123854,-158.066853,Thompsonland,166 Hammond Stravenue,8812,56265 2,amandawallace@example.net,lambertfranklin,$BQGXjt49y,Christopher,Hansen,6-507-543-5500,0,-56.4904755,-47.427614,Pageburgh,716 Leonard Haven Suite 277,8776,42149 import boto3 import pandas as pd s3 = boto3.client('s3') print('Original object from the S3 bucket:') original = s3.get_object( Bucket='your_bucket_name', Key='user_daily_data.csv') data_str = original['Body'].read().decode('utf-8') print(data_str) print('Object processed by S3 Object Lambda:') transformed = s3.get_object( Bucket='bucket_access_point', Key='user_daily_data.csv') data_str = transformed['Body'].read().decode('utf-8') print(data_str) Author Bio : Yashupadhyaya is a Certified AWS Data Engineer with over 2.5 years of experience in architecting and optimizing data pipelines using AWS and Azure services. Specializing in cloud-based solutions, Yashupadhyaya is proficient in technologies like Python, PySpark, Airflow, dBt, and Flask. He has a proven track record of leveraging AWS and Azure services to build scalable analytics platforms and streamline data ingestion processes. With a passion for driving data-driven decision-making, he continues to innovate in the realm of multi-cloud environments and open-source tools.
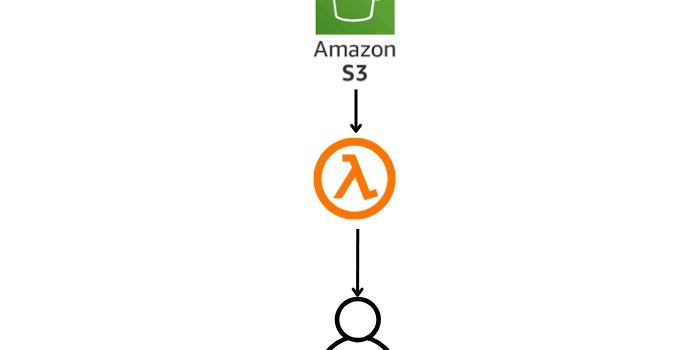
What is an Object Lambda ?
S3 Object Lambda is a new feature that lets you customize how data from Amazon S3 is handled before it’s sent back to your application. This means you can process and change the data using your own code without having to modify your application. It works by using AWS Lambda functions to automatically process the data each time it’s fetched from S3. This way, you can easily create different versions or views of your data without changing your app, and you can update how the data is processed whenever you need to.
How to setup s3 object lambda
Step 1: First, we will create an access point for S3 bucket
- Go to your S3 bucket and open access points
- We will have to create a bucket access point
- Name you access point and select internet in network origin
Step 2: Create Lambda
import boto3
import requests
import pandas as pd
def lambda_handler(event, context):
print(event)
object_get_context = event["getObjectContext"]
request_route = object_get_context["outputRoute"]
request_token = object_get_context["outputToken"]
s3_url = object_get_context["inputS3Url"]
# Get object from S3
response = requests.get(s3_url)
original_object = response.content.decode('utf-8')
# Transform object
columns = original_object.split('\r\n')[0].replace('"','').replace('\ufeff','').split(',')
user_data = []
for data in original_object.split('\r\n')[1:-1] :
user_data.append(data.replace('"','').split(','))
user_df = pd.DataFrame(user_data,columns=columns)
user_df.drop(columns=['password'],inplace=True)
# Write object back to S3 Object Lambda
s3 = boto3.client('s3')
s3.write_get_object_response(
Body=bytes(user_df.to_csv(index=False),encoding = 'utf-8'),
RequestRoute=request_route,
RequestToken=request_token)
return {'status_code': 200}
Step 3: Create object lambda access points from left hand side menu of S3
- Click on ‘Create Object Lambda Access Point’
- Select your bucket access point
- Select all transformation
- Select Lambda that you have created above
- Leave other things as default.
Step 4: Get object using boto3
Csv Data : Copy the below data and store it in csv file with name user_daily_data.csv
id,email,username,password,name__firstname,name__lastname,phone,__v,address__geolocation__lat,address__geolocation__long,address__city,address__street,address__number,address__zipcode
1,sarahreyes@example.org,cameronrobert,&RnzRNczN6,Tracy,Doyle,9-087-607-2043,0,-81.123854,-158.066853,Thompsonland,166 Hammond Stravenue,8812,56265
2,amandawallace@example.net,lambertfranklin,$BQGXjt49y,Christopher,Hansen,6-507-543-5500,0,-56.4904755,-47.427614,Pageburgh,716 Leonard Haven Suite 277,8776,42149
import boto3
import pandas as pd
s3 = boto3.client('s3')
print('Original object from the S3 bucket:')
original = s3.get_object(
Bucket='your_bucket_name',
Key='user_daily_data.csv')
data_str = original['Body'].read().decode('utf-8')
print(data_str)
print('Object processed by S3 Object Lambda:')
transformed = s3.get_object(
Bucket='bucket_access_point',
Key='user_daily_data.csv')
data_str = transformed['Body'].read().decode('utf-8')
print(data_str)
Author Bio :
Yashupadhyaya is a Certified AWS Data Engineer with over 2.5 years of experience in architecting and optimizing data pipelines using AWS and Azure services. Specializing in cloud-based solutions, Yashupadhyaya is proficient in technologies like Python, PySpark, Airflow, dBt, and Flask. He has a proven track record of leveraging AWS and Azure services to build scalable analytics platforms and streamline data ingestion processes. With a passion for driving data-driven decision-making, he continues to innovate in the realm of multi-cloud environments and open-source tools.