










































































































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)

































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)









































































































.png?#)






(1).jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)





























_NicoElNino_Alamy.png?#)
.webp?#)
.webp?#)




































































































![Apple to Source More iPhones From India to Offset China Tariff Costs [Report]](https://www.iclarified.com/images/news/96954/96954/96954-640.jpg)
![Blackmagic Design Unveils DaVinci Resolve 20 With Over 100 New Features and AI Tools [Video]](https://www.iclarified.com/images/news/96951/96951/96951-640.jpg)

























































































































What is shared memory, and how is it utilized in multi-core SoCs?
Shared memory is a fundamental concept in multi-core System-on-Chip (SoC) designs that enables efficient communication and data sharing between processor cores. Here's a comprehensive explanation of its implementation and usage: What is Shared Memory? Shared memory refers to a memory region that is accessible by multiple processing units (CPUs, GPUs, DSPs) in a multi-core system. Unlike private memory that is core-specific, shared memory allows different processors to access the same data without explicit data transfers. Key Characteristics Unified Address Space: All cores see the same memory addresses for shared regions Concurrent Access: Multiple cores can read/write simultaneously (with synchronization) Coherency Management: Hardware/software maintains data consistency across cores Low-Latency Communication: Faster than message passing for frequent data exchange Implementation in Modern SoCs 1. Hardware Architectures A. Uniform Memory Access (UMA) All cores share equal access latency to memory Example: Smartphone application processors (e.g., ARM big.LITTLE) B. Non-Uniform Memory Access (NUMA) Memory access time depends on physical location Example: Server CPUs (AMD EPYC, Intel Xeon) C. Hybrid Architectures Combination of shared and distributed memory Example: Heterogeneous SoCs (CPU+GPU+DSP) 2. Memory Hierarchy ┌───────────────────────┐ │ Core 1 Core 2 │ Cores └───┬───────┬─────┬─────┘ │L1 Cache│ │L1 Cache └───┬────┘ └───┬────┘ │L2 Cache │L2 Cache └───────┬──────┘ │Shared L3 Cache └───────┬──────┘ │DRAM Controller └───────┬──────┘ │Main Memory Utilization Techniques 1. Cache Coherency Protocols MESI/MOESI: Maintain consistency across core caches Hardware-Managed: Transparent to software (ARM CCI, AMD Infinity Fabric) Directory-Based: Tracks which cores have cache lines 2. Synchronization Mechanisms A. Atomic Operations c // ARMv8 atomic increment LDREX R0, [R1] // Load with exclusive monitor ADD R0, R0, #1 // Increment STREX R2, R0, [R1] // Store conditionally B. Hardware Spinlocks Dedicated synchronization IP blocks Lower power than software spinlocks C. Memory Barriers c // ARM Data Memory Barrier DMB ISH // Ensure all cores see writes in order 3. Shared Memory Programming Models A. OpenMP c #pragma omp parallel shared(matrix) { // Multiple threads access matrix } B. POSIX Shared Memory c int fd = shm_open("/shared_region", O_CREAT|O_RDWR, 0666); ftruncate(fd, SIZE); void* ptr = mmap(NULL, SIZE, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0); C. Linux Kernel Shared Memory c // Reserve shared memory region void *shmem = memremap(resource, size, MEMREMAP_WB); Performance Optimization Techniques False Sharing Mitigation Align data to cache line boundaries (typically 64B) c struct __attribute__((aligned(64))) { int core1_data; int core2_data; }; NUMA-Aware Allocation c // Linux NUMA policy set_mempolicy(MPOL_BIND, nodemask, sizeof(nodemask)); Write-Combining Buffers Batch writes to shared memory ARM STLR/STNP instructions Hardware Accelerator Access Shared virtual memory (SVM) for CPU-GPU sharing IOMMU address translation Real-World SoC Examples ARM DynamIQ Shared L3 cache with configurable slices DSU (DynamIQ Shared Unit) manages coherency Intel Client SoCs Last Level Cache (LLC) partitioning Mesh interconnect with home agents AMD Ryzen Infinity Fabric coherent interconnect Multi-chip module shared memory Debugging Challenges Race Conditions Use hardware watchpoints (ARM ETM, Intel PT) Memory tagging (ARM MTE) Coherency Issues Cache snoop filters Performance monitor unit (PMU) events Deadlocks Hardware lock elision (Intel TSX) Spinlock profiling Emerging Trends Chiplet Architectures Shared memory across dies (UCIe standard) Advanced packaging (2.5D/3D) Compute Express Link (CXL) Memory pooling between SoCs Type 3 devices for shared memory expansion Persistent Shared Memory NVDIMM integration Asynchronous DRAM refresh (ADR) Shared memory remains the most efficient communication mechanism for tightly-coupled processors in modern SoCs, though it requires careful design to avoid contention and maintain consistency in increasingly complex multi-core systems.
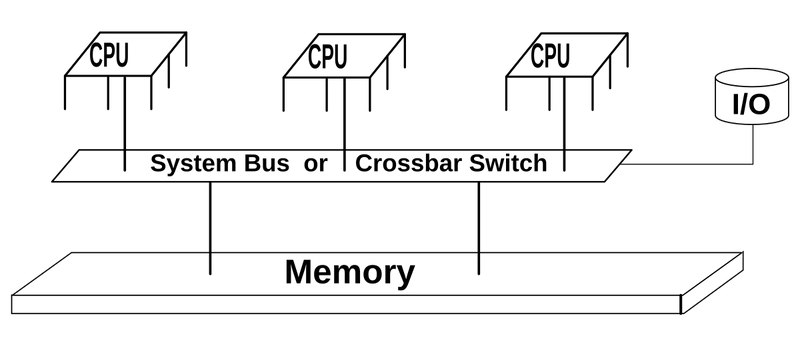
Shared memory is a fundamental concept in multi-core System-on-Chip (SoC) designs that enables efficient communication and data sharing between processor cores. Here's a comprehensive explanation of its implementation and usage:
What is Shared Memory?
Shared memory refers to a memory region that is accessible by multiple processing units (CPUs, GPUs, DSPs) in a multi-core system. Unlike private memory that is core-specific, shared memory allows different processors to access the same data without explicit data transfers.
Key Characteristics
- Unified Address Space: All cores see the same memory addresses for shared regions
- Concurrent Access: Multiple cores can read/write simultaneously (with synchronization)
- Coherency Management: Hardware/software maintains data consistency across cores
- Low-Latency Communication: Faster than message passing for frequent data exchange
Implementation in Modern SoCs
1. Hardware Architectures
A. Uniform Memory Access (UMA)
All cores share equal access latency to memory
Example: Smartphone application processors (e.g., ARM big.LITTLE)
B. Non-Uniform Memory Access (NUMA)
Memory access time depends on physical location
Example: Server CPUs (AMD EPYC, Intel Xeon)
C. Hybrid Architectures
Combination of shared and distributed memory
Example: Heterogeneous SoCs (CPU+GPU+DSP)
2. Memory Hierarchy
┌───────────────────────┐
│ Core 1 Core 2 │ Cores
└───┬───────┬─────┬─────┘
│L1 Cache│ │L1 Cache
└───┬────┘ └───┬────┘
│L2 Cache │L2 Cache
└───────┬──────┘
│Shared L3 Cache
└───────┬──────┘
│DRAM Controller
└───────┬──────┘
│Main Memory
Utilization Techniques
1. Cache Coherency Protocols
- MESI/MOESI: Maintain consistency across core caches
- Hardware-Managed: Transparent to software (ARM CCI, AMD Infinity Fabric)
- Directory-Based: Tracks which cores have cache lines
2. Synchronization Mechanisms
A. Atomic Operations
c
// ARMv8 atomic increment
LDREX R0, [R1] // Load with exclusive monitor
ADD R0, R0, #1 // Increment
STREX R2, R0, [R1] // Store conditionally
B. Hardware Spinlocks
- Dedicated synchronization IP blocks
- Lower power than software spinlocks
C. Memory Barriers
c
// ARM Data Memory Barrier
DMB ISH // Ensure all cores see writes in order
3. Shared Memory Programming Models
A. OpenMP
c
#pragma omp parallel shared(matrix)
{
// Multiple threads access matrix
}
B. POSIX Shared Memory
c
int fd = shm_open("/shared_region", O_CREAT|O_RDWR, 0666);
ftruncate(fd, SIZE);
void* ptr = mmap(NULL, SIZE, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);
C. Linux Kernel Shared Memory
c
// Reserve shared memory region
void *shmem = memremap(resource, size, MEMREMAP_WB);
Performance Optimization Techniques
- False Sharing Mitigation
Align data to cache line boundaries (typically 64B)
c
struct __attribute__((aligned(64))) {
int core1_data;
int core2_data;
};
- NUMA-Aware Allocation
c
// Linux NUMA policy
set_mempolicy(MPOL_BIND, nodemask, sizeof(nodemask));
- Write-Combining Buffers
- Batch writes to shared memory
- ARM STLR/STNP instructions
- Hardware Accelerator Access
- Shared virtual memory (SVM) for CPU-GPU sharing
- IOMMU address translation
Real-World SoC Examples
- ARM DynamIQ
- Shared L3 cache with configurable slices
- DSU (DynamIQ Shared Unit) manages coherency
- Intel Client SoCs
- Last Level Cache (LLC) partitioning
- Mesh interconnect with home agents
- AMD Ryzen
- Infinity Fabric coherent interconnect
- Multi-chip module shared memory
Debugging Challenges
- Race Conditions
- Use hardware watchpoints (ARM ETM, Intel PT)
- Memory tagging (ARM MTE)
- Coherency Issues
- Cache snoop filters
- Performance monitor unit (PMU) events
- Deadlocks
- Hardware lock elision (Intel TSX)
- Spinlock profiling
Emerging Trends
- Chiplet Architectures
- Shared memory across dies (UCIe standard)
- Advanced packaging (2.5D/3D)
- Compute Express Link (CXL)
- Memory pooling between SoCs
- Type 3 devices for shared memory expansion
- Persistent Shared Memory
- NVDIMM integration
- Asynchronous DRAM refresh (ADR)
Shared memory remains the most efficient communication mechanism for tightly-coupled processors in modern SoCs, though it requires careful design to avoid contention and maintain consistency in increasingly complex multi-core systems.



