


























































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)



















































































































































































































































-All-will-be-revealed-00-35-05.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

















































































































![What iPhone 17 model are you most excited to see? [Poll]](https://9to5mac.com/wp-content/uploads/sites/6/2025/04/iphone-17-pro-sky-blue.jpg?quality=82&strip=all&w=290&h=145&crop=1)
















![Hands-On With 'iPhone 17 Air' Dummy Reveals 'Scary Thin' Design [Video]](https://www.iclarified.com/images/news/97100/97100/97100-640.jpg)
![Mike Rockwell is Overhauling Siri's Leadership Team [Report]](https://www.iclarified.com/images/news/97096/97096/97096-640.jpg)
![Instagram Releases 'Edits' Video Creation App [Download]](https://www.iclarified.com/images/news/97097/97097/97097-640.jpg)
![Inside Netflix's Rebuild of the Amsterdam Apple Store for 'iHostage' [Video]](https://www.iclarified.com/images/news/97095/97095/97095-640.jpg)



















































































































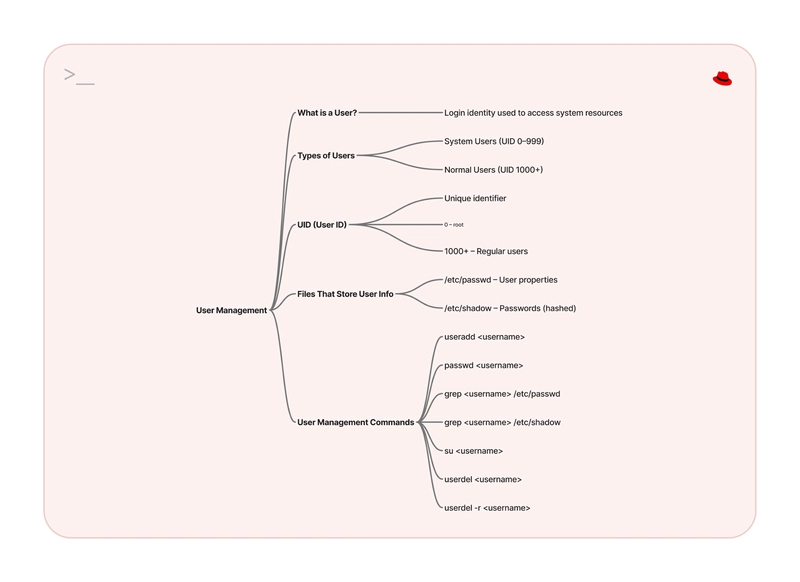
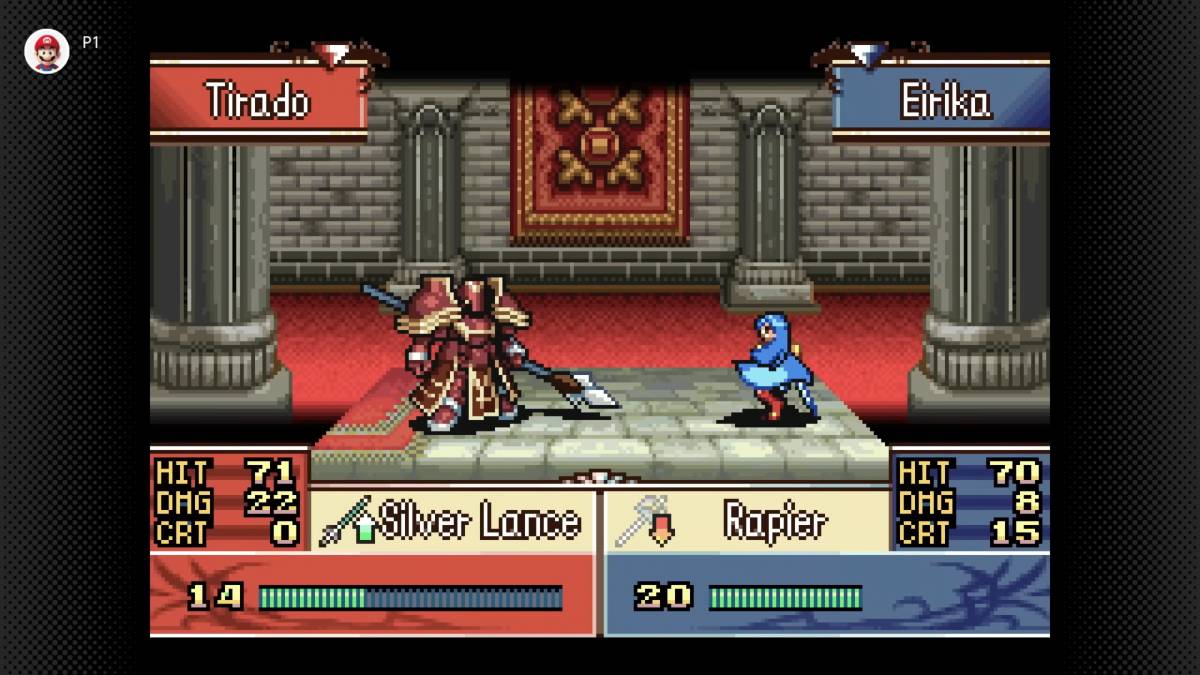
What is Data Dredging ?
Data dredging (also known as data snooping or p-hacking)[1][a] is the misuse of data analysis to find patterns in data that can be presented as statistically significant, thus dramatically increasing and understating the risk of false positives. This is done by performing many statistical tests on the data and only reporting those that come back with significant results.[2] Thus data dredging is also often a misused or misapplied form of data mining. A humorous example of a result produced by data dredging, showing a correlation between the number of letters in Scripps National Spelling Bee's winning word and the number of people in the United States killed by venomous spiders The process of data dredging involves testing multiple hypotheses using a single data set by exhaustively searching—perhaps for combinations of variables that might show a correlation, and perhaps for groups of cases or observations that show differences in their mean or in their breakdown by some other variable. Conventional tests of statistical significance are based on the probability that a particular result would arise if chance alone were at work, and necessarily accept some risk of mistaken conclusions of a certain type (mistaken rejections of the null hypothesis). This level of risk is called the significance. When large numbers of tests are performed, some produce false results of this type; hence 5% of randomly chosen hypotheses might be (erroneously) reported to be statistically significant at the 5% significance level, 1% might be (erroneously) reported to be statistically significant at the 1% significance level, and so on, by chance alone. When enough hypotheses are tested, it is virtually certain that some will be reported to be statistically significant (even though this is misleading), since almost every data set with any degree of randomness is likely to contain (for example) some spurious correlations. If they are not cautious, researchers using data mining techniques can be easily misled by these results. The term p-hacking (in reference to p-values) was coined in a 2014 paper by the three researchers behind the blog Data Colada, which has been focusing on uncovering such problems in social sciences research.[3][4][5] Data dredging is an example of disregarding the multiple comparisons problem. One form is when subgroups are compared without alerting the reader to the total number of subgroup comparisons examined.[6] When misused it is a questionable research practice that can undermine scientific integrity.

Data dredging (also known as data snooping or p-hacking)[1][a] is the misuse of data analysis to find patterns in data that can be presented as statistically significant, thus dramatically increasing and understating the risk of false positives. This is done by performing many statistical tests on the data and only reporting those that come back with significant results.[2] Thus data dredging is also often a misused or misapplied form of data mining.
A humorous example of a result produced by data dredging, showing a correlation between the number of letters in Scripps National Spelling Bee's winning word and the number of people in the United States killed by venomous spiders
The process of data dredging involves testing multiple hypotheses using a single data set by exhaustively searching—perhaps for combinations of variables that might show a correlation, and perhaps for groups of cases or observations that show differences in their mean or in their breakdown by some other variable.
Conventional tests of statistical significance are based on the probability that a particular result would arise if chance alone were at work, and necessarily accept some risk of mistaken conclusions of a certain type (mistaken rejections of the null hypothesis). This level of risk is called the significance. When large numbers of tests are performed, some produce false results of this type; hence 5% of randomly chosen hypotheses might be (erroneously) reported to be statistically significant at the 5% significance level, 1% might be (erroneously) reported to be statistically significant at the 1% significance level, and so on, by chance alone. When enough hypotheses are tested, it is virtually certain that some will be reported to be statistically significant (even though this is misleading), since almost every data set with any degree of randomness is likely to contain (for example) some spurious correlations. If they are not cautious, researchers using data mining techniques can be easily misled by these results. The term p-hacking (in reference to p-values) was coined in a 2014 paper by the three researchers behind the blog Data Colada, which has been focusing on uncovering such problems in social sciences research.[3][4][5]
Data dredging is an example of disregarding the multiple comparisons problem. One form is when subgroups are compared without alerting the reader to the total number of subgroup comparisons examined.[6] When misused it is a questionable research practice that can undermine scientific integrity.