









































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






















































































































































































































































-All-will-be-revealed-00-35-05.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)













































































































![What iPhone 17 model are you most excited to see? [Poll]](https://9to5mac.com/wp-content/uploads/sites/6/2025/04/iphone-17-pro-sky-blue.jpg?quality=82&strip=all&w=290&h=145&crop=1)

















![Hands-On With 'iPhone 17 Air' Dummy Reveals 'Scary Thin' Design [Video]](https://www.iclarified.com/images/news/97100/97100/97100-640.jpg)
![Mike Rockwell is Overhauling Siri's Leadership Team [Report]](https://www.iclarified.com/images/news/97096/97096/97096-640.jpg)
![Instagram Releases 'Edits' Video Creation App [Download]](https://www.iclarified.com/images/news/97097/97097/97097-640.jpg)
![Inside Netflix's Rebuild of the Amsterdam Apple Store for 'iHostage' [Video]](https://www.iclarified.com/images/news/97095/97095/97095-640.jpg)





















































































































Every Database Will Support Iceberg — Here's Why
If you follow me on LinkedIn or Medium, you’ve probably noticed I’ve been talking a lot about Apache Iceberg. And as the founder of RisingWave — a stream processing and management system — I get this question a lot: “You’ve been posting so much about Iceberg lately. Are you pivoting away from stream processing?” Let me be clear: No, I’m not pivoting. I’m doubling down. What we’re seeing isn’t just a feature trend. It’s a structural change in how data infrastructure works. Iceberg is becoming the de facto standard for storing large-scale analytical data — not because it’s trendy, but because the current approach of proprietary storage formats doesn’t scale well across systems. I believe every modern database — whether OLTP or OLAP — will eventually support Iceberg. Not because it’s nice to have, but because it’ll be required for interoperability and long-term ownership of data. Vendor lock-in is already becoming unsustainable. Let me explain why. Proprietary Format vs Open Table Format Traditional databases — PostgreSQL, MySQL, etc. — store their data in proprietary formats. That format is optimized for that engine and can’t be directly accessed by anything else. Even if something like Trino can connect to Postgres, it’s still running queries through Postgres itself, not reading its storage directly. You’re just a client. This is fine for self-contained systems. But once you want to do analytics across multiple systems — or use different engines for different workloads — you hit a wall. Moving data between systems means copying it, which introduces a whole new set of problems: schema mismatches, sync issues, stale data, conflicting updates, and no clear source of truth. And then there’s lock-in. Some vendors offer big discounts to start with, then drastically raise the price once your data is locked into their system. At that point, it’s too expensive or painful to move out, and the business is stuck. Iceberg offers a way out. Iceberg Decouples Storage and Compute Apache Iceberg defines a table format that separates how data is stored from how data is queried. Any engine that implements the Iceberg integration — Spark, Flink, Trino, DuckDB, Snowflake, RisingWave — can read and/or write Iceberg data directly. This changes the architecture. You don’t need to move data between systems anymore. You don’t need to reprocess or convert formats. You can process data using one engine and query it using another. That also means you can avoid tying storage to a single execution engine. Instead of buying into a vertically integrated stack where you’re stuck using whatever engine the vendor ships, you can pick the right tool for the job. One format, multiple engines. It just works. The Future is Dual-Format I think the long-term architecture for most databases is going to be dual-format: A proprietary format, optimized for internal performance — low-latency access, in-memory workloads, transaction processing, etc. An open format, like Iceberg, for interoperability — long-term storage, external access, and sharing across systems This isn’t hypothetical. It’s already happening. Snowflake supports reading and writing Iceberg. Databricks added Iceberg interoperability via Unity Catalog. Redshift and BigQuery are working toward it. There’s still a role for proprietary formats. If you want to squeeze every bit of performance out of your OLTP engine, you need a tightly integrated format. But if your data lives inside only one engine, it’s not reusable. You can’t share it. You can’t migrate it. You can’t build cross-system pipelines easily. You’re locked in. That’s where Iceberg comes in. You can use your fast internal format when needed, and write a copy to Iceberg when the data needs to be accessed elsewhere. Over time, more and more systems will treat Iceberg as the default external representation of data. What We’re Building at RisingWave RisingWave started as a distributed streaming database with a PostgreSQL interface. We wanted to make it easy to process real-time data using standard SQL. But we quickly realized that many teams don’t just want to process streaming data — they want to store it in a way that’s reusable by other tools downstream. So we made Iceberg a native output. What does that mean, practically? Ingest real-time data from Kafka, Pulsar, or CDC sources like Postgresand MySQL, with built-in support for Debezium. Transform the data using Postgres-style SQL — joins, filters, aggregations, or even more complicated operators. Write the output directly to Iceberg tables, with schema evolution, partitioning, and compaction handled internally. Enforce primary keys using equality deletes, even though Iceberg doesn’t natively support constraints. Build materialized views on top of Iceberg, meaning that it reads Iceberg tables incrementally and keep the materialized views fresh in near real time. The end goal is simple: let streaming and b
If you follow me on LinkedIn or Medium, you’ve probably noticed I’ve been talking a lot about Apache Iceberg. And as the founder of RisingWave — a stream processing and management system — I get this question a lot:
“You’ve been posting so much about Iceberg lately. Are you pivoting away from stream processing?”
Let me be clear: No, I’m not pivoting. I’m doubling down.
What we’re seeing isn’t just a feature trend. It’s a structural change in how data infrastructure works. Iceberg is becoming the de facto standard for storing large-scale analytical data — not because it’s trendy, but because the current approach of proprietary storage formats doesn’t scale well across systems.
I believe every modern database — whether OLTP or OLAP — will eventually support Iceberg. Not because it’s nice to have, but because it’ll be required for interoperability and long-term ownership of data. Vendor lock-in is already becoming unsustainable.
Let me explain why.
Proprietary Format vs Open Table Format
Traditional databases — PostgreSQL, MySQL, etc. — store their data in proprietary formats. That format is optimized for that engine and can’t be directly accessed by anything else. Even if something like Trino can connect to Postgres, it’s still running queries through Postgres itself, not reading its storage directly. You’re just a client.
This is fine for self-contained systems. But once you want to do analytics across multiple systems — or use different engines for different workloads — you hit a wall. Moving data between systems means copying it, which introduces a whole new set of problems: schema mismatches, sync issues, stale data, conflicting updates, and no clear source of truth.
And then there’s lock-in. Some vendors offer big discounts to start with, then drastically raise the price once your data is locked into their system. At that point, it’s too expensive or painful to move out, and the business is stuck.
Iceberg offers a way out.
Iceberg Decouples Storage and Compute
Apache Iceberg defines a table format that separates how data is stored from how data is queried. Any engine that implements the Iceberg integration — Spark, Flink, Trino, DuckDB, Snowflake, RisingWave — can read and/or write Iceberg data directly.
This changes the architecture. You don’t need to move data between systems anymore. You don’t need to reprocess or convert formats. You can process data using one engine and query it using another.
That also means you can avoid tying storage to a single execution engine. Instead of buying into a vertically integrated stack where you’re stuck using whatever engine the vendor ships, you can pick the right tool for the job. One format, multiple engines. It just works.
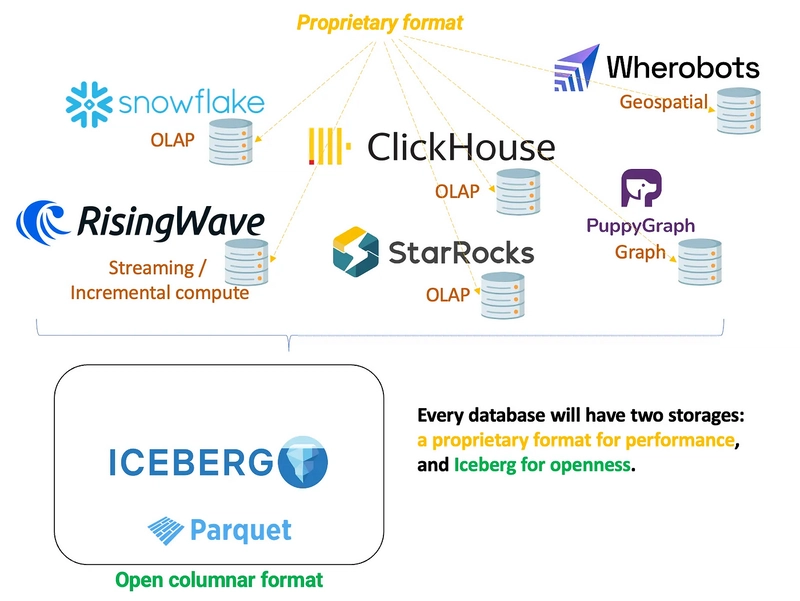
The Future is Dual-Format
I think the long-term architecture for most databases is going to be dual-format:
- A proprietary format, optimized for internal performance — low-latency access, in-memory workloads, transaction processing, etc.
- An open format, like Iceberg, for interoperability — long-term storage, external access, and sharing across systems
This isn’t hypothetical. It’s already happening. Snowflake supports reading and writing Iceberg. Databricks added Iceberg interoperability via Unity Catalog. Redshift and BigQuery are working toward it.
There’s still a role for proprietary formats. If you want to squeeze every bit of performance out of your OLTP engine, you need a tightly integrated format. But if your data lives inside only one engine, it’s not reusable. You can’t share it. You can’t migrate it. You can’t build cross-system pipelines easily. You’re locked in.
That’s where Iceberg comes in. You can use your fast internal format when needed, and write a copy to Iceberg when the data needs to be accessed elsewhere. Over time, more and more systems will treat Iceberg as the default external representation of data.
What We’re Building at RisingWave
RisingWave started as a distributed streaming database with a PostgreSQL interface. We wanted to make it easy to process real-time data using standard SQL. But we quickly realized that many teams don’t just want to process streaming data — they want to store it in a way that’s reusable by other tools downstream.
So we made Iceberg a native output.
What does that mean, practically?
- Ingest real-time data from Kafka, Pulsar, or CDC sources like Postgresand MySQL, with built-in support for Debezium.
- Transform the data using Postgres-style SQL — joins, filters, aggregations, or even more complicated operators.
- Write the output directly to Iceberg tables, with schema evolution, partitioning, and compaction handled internally.
- Enforce primary keys using equality deletes, even though Iceberg doesn’t natively support constraints.
- Build materialized views on top of Iceberg, meaning that it reads Iceberg tables incrementally and keep the materialized views fresh in near real time.
The end goal is simple: let streaming and batch workloads converge on the same open table format.
Open Protocols Always Win
We’ve seen this pattern before:
- JDBC and ODBC standardized access to relational databases
- S3 became the universal interface for object storage
- The PostgreSQL wire protocol became the standard for many open-source databases.
Now Iceberg is doing the same for table formats.
Open protocols win because they lower friction. They give users control. They force vendors to compete on performance and features instead of relying on lock-in. And they make it easier to compose systems from multiple components, without worrying about whether the storage format will be the bottleneck.
If your system doesn’t support open formats, it’s not future-proof.
Summary
So no, I’m not walking away from stream processing.
I’m building toward a future where data don’t live in separate silos, and where data can move freely across engines, systems, and tools.
That future is built on Apache Iceberg.


