![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)











































































































































































































































































_Muhammad_R._Fakhrurrozi_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_NicoElNino_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





















































































![macOS 15.5 beta 4 now available for download [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/macOS-Sequoia-15.5-b4.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)















![AirPods Pro 2 With USB-C Back On Sale for Just $169! [Deal]](https://www.iclarified.com/images/news/96315/96315/96315-640.jpg)
![Apple Releases iOS 18.5 Beta 4 and iPadOS 18.5 Beta 4 [Download]](https://www.iclarified.com/images/news/97145/97145/97145-640.jpg)
![Apple Seeds watchOS 11.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97147/97147/97147-640.jpg)
![Apple Seeds visionOS 2.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97150/97150/97150-640.jpg)





































![Apple Seeds Fourth Beta of iOS 18.5 to Developers [Update: Public Beta Available]](https://images.macrumors.com/t/uSxxRefnKz3z3MK1y_CnFxSg8Ak=/2500x/article-new/2025/04/iOS-18.5-Feature-Real-Mock.jpg)
![Apple Seeds Fourth Beta of macOS Sequoia 15.5 [Update: Public Beta Available]](https://images.macrumors.com/t/ne62qbjm_V5f4GG9UND3WyOAxE8=/2500x/article-new/2024/08/macOS-Sequoia-Night-Feature.jpg)






















































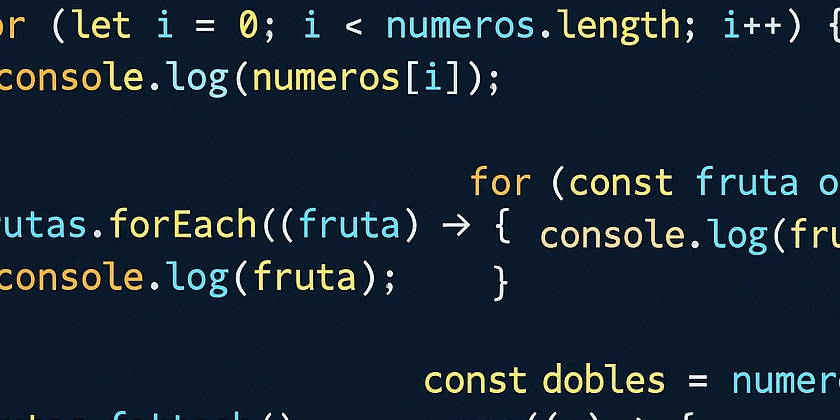
VSUM: Blazing-Fast Array Summation in C
VSUM is an open-source C library engineered for high-performance summation of numerical arrays. Designed for applications involving large datasets, scientific computing, and performance-critical systems, VSUM leverages multithreading, SIMD vectorization (AVX/AVX2/SSE2), and cache-conscious algorithms to achieve significant speedups over naive implementations. This library serves as both a practical tool for accelerating computations and a demonstration of advanced C programming techniques for hardware optimization. Core Features Type Support: Optimized routines for int, float, and double arrays. Parallel Execution: Utilizes POSIX threads for concurrent summation on multi-core processors. SIMD Acceleration: Employs AVX2, AVX, SSE2, and SSE intrinsics with runtime CPU feature detection for vectorized computation on compatible x86-64 architectures. Cache-Aware Sequential Processing: Includes a sequential summation method designed with cache locality in mind. Adaptive Implementation: Automatically selects the most suitable summation strategy (SIMD, parallel, sequential) based on runtime hardware capabilities and data characteristics. Ease of Integration: Provided as a .h header and .c source file for straightforward inclusion in C projects. Portability: Compatible with Linux, macOS, and other POSIX-compliant systems supporting pthreads. SIMD acceleration is specific to x86-64, with graceful fallbacks on other architectures. Technical Value Proposition Standard array summation, while conceptually simple, presents optimization opportunities critical for performance. VSUM addresses these by implementing and showcasing: Effective use of SIMD intrinsics for data-parallel arithmetic operations. Portable runtime CPU feature detection to ensure safe and optimal SIMD instruction usage. Workload distribution strategies for multithreaded execution. Memory alignment considerations for maximizing SIMD efficiency. Principles of clean, modular, and well-documented C code for maintainability and reuse. Installation and Build Process Obtain the Source Code: git clone https://github.com/davidesantangelo/vsum.git cd vsum Integrate into your Project: Add vsum.h and vsum.c to your project's source files. Compile: Build vsum.c into an object file. For optimal performance on x86-64, enable relevant SIMD instruction sets (e.g., -mavx2) and pthreads (-pthread). The library includes runtime checks, making it safe to compile with these flags even if the target machine lacks the features. # Example: Compile vsum.c with AVX2 and pthreads support gcc -O2 -Wall -Wextra -pthread -mavx2 -c vsum.c -o vsum.o Link: Link the resulting vsum.o object file with your application code. Ensure you link with the pthreads library (-pthread). # Example: Compile main application and link with vsum.o and pthreads gcc -O2 -Wall -Wextra -pthread main.c vsum.o -o my_application -lm # -lm if using math functions Usage Example #include "vsum.h" // Include the library header #include #include // For aligned_alloc, free #include // For int64_t int main() { size_t n = 10000000; // Example array size // Allocate memory aligned for potential SIMD optimization int *arr = (int*)aligned_alloc(VSUM_AVX_ALIGNMENT, n * sizeof(int)); if (!arr) { perror("aligned_alloc failed"); return 1; } // Initialize array data (example) for (size_t i = 0; i

VSUM is an open-source C library engineered for high-performance summation of numerical arrays. Designed for applications involving large datasets, scientific computing, and performance-critical systems, VSUM leverages multithreading, SIMD vectorization (AVX/AVX2/SSE2), and cache-conscious algorithms to achieve significant speedups over naive implementations.
This library serves as both a practical tool for accelerating computations and a demonstration of advanced C programming techniques for hardware optimization.
Core Features
-
Type Support: Optimized routines for
int,float, anddoublearrays. - Parallel Execution: Utilizes POSIX threads for concurrent summation on multi-core processors.
- SIMD Acceleration: Employs AVX2, AVX, SSE2, and SSE intrinsics with runtime CPU feature detection for vectorized computation on compatible x86-64 architectures.
- Cache-Aware Sequential Processing: Includes a sequential summation method designed with cache locality in mind.
- Adaptive Implementation: Automatically selects the most suitable summation strategy (SIMD, parallel, sequential) based on runtime hardware capabilities and data characteristics.
-
Ease of Integration: Provided as a
.hheader and.csource file for straightforward inclusion in C projects. - Portability: Compatible with Linux, macOS, and other POSIX-compliant systems supporting pthreads. SIMD acceleration is specific to x86-64, with graceful fallbacks on other architectures.
Technical Value Proposition
Standard array summation, while conceptually simple, presents optimization opportunities critical for performance. VSUM addresses these by implementing and showcasing:
- Effective use of SIMD intrinsics for data-parallel arithmetic operations.
- Portable runtime CPU feature detection to ensure safe and optimal SIMD instruction usage.
- Workload distribution strategies for multithreaded execution.
- Memory alignment considerations for maximizing SIMD efficiency.
- Principles of clean, modular, and well-documented C code for maintainability and reuse.
Installation and Build Process
-
Obtain the Source Code:
git clone https://github.com/davidesantangelo/vsum.git cd vsum Integrate into your Project: Add
vsum.handvsum.cto your project's source files.-
Compile: Build
vsum.cinto an object file. For optimal performance on x86-64, enable relevant SIMD instruction sets (e.g.,-mavx2) and pthreads (-pthread). The library includes runtime checks, making it safe to compile with these flags even if the target machine lacks the features.
# Example: Compile vsum.c with AVX2 and pthreads support gcc -O2 -Wall -Wextra -pthread -mavx2 -c vsum.c -o vsum.o -
Link: Link the resulting
vsum.oobject file with your application code. Ensure you link with the pthreads library (-pthread).
# Example: Compile main application and link with vsum.o and pthreads gcc -O2 -Wall -Wextra -pthread main.c vsum.o -o my_application -lm # -lm if using math functions
Usage Example
#include "vsum.h" // Include the library header
#include Performance Characteristics
VSUM can achieve significant performance improvements compared to naive sequential summation loops, particularly on large arrays processed on multi-core CPUs equipped with AVX2 capabilities. Speedups ranging from 10x to 50x are possible under optimal conditions.
| Method | Relative Time | Illustrative Speedup | Notes |
|---|---|---|---|
| Sequential | High | 1x | Baseline scalar implementation. |
| Cache-friendly | Medium | ~2-3x | Sequential, optimized for cache access. |
| Parallel | Medium-Low | ~3-8x | Depends on core count and overhead. |
| SIMD (AVX2) | Low | ~10-50x | Highly dependent on CPU and data alignment. |
(Performance figures are illustrative and depend heavily on the specific hardware, compiler, data size, and system load. Refer to the project's README.md for detailed benchmarks.)
Implementation Details
1. Multithreading (Parallel Summation)
The vsum_parallel_sum_* functions partition the input array into segments. Each segment is processed by a separate worker thread using POSIX threads. Partial sums from each thread are aggregated to produce the final result. The number of threads is determined dynamically based on data size and available cores, capped by VSUM_MAX_THREADS.
// Example function signature
int64_t vsum_parallel_sum_int(const int *array, size_t total_elements);
2. SIMD Vectorization (SIMD Summation)
The vsum_simd_sum_* functions utilize Single Instruction, Multiple Data (SIMD) intrinsics (AVX2, AVX, SSE2, SSE) available on x86-64 processors. Runtime checks (cpuid) ensure that only supported instructions are executed. The implementation selects the highest available instruction set (preferring AVX2 > AVX > SSE2 > SSE) and processes data in vector chunks (e.g., 8 integers or 4 doubles simultaneously with AVX2). It handles memory alignment for optimal performance, falling back to unaligned loads if necessary. Scalar processing is used as a final fallback.
// Example function signature
int64_t vsum_simd_sum_int(const int *array, size_t total_elements);
3. Cache-Friendly Sequential Summation
The vsum_cache_friendly_sum_* functions perform a sequential sum but process data in chunks roughly corresponding to typical CPU cache line sizes (VSUM_CACHE_LINE_SIZE). This aims to improve data locality and reduce cache misses compared to a completely naive loop, although modern CPU prefetchers often mitigate the need for manual cache blocking in simple summation.
// Example function signature
int64_t vsum_cache_friendly_sum_int(const int *array, size_t total_elements);
API Reference
The library exposes functions for each summation strategy and data type:
Parallel Summation:
vsum_parallel_sum_int(const int *array, size_t n)vsum_parallel_sum_float(const float *array, size_t n)vsum_parallel_sum_double(const double *array, size_t n)
SIMD Summation:
vsum_simd_sum_int(const int *array, size_t n)vsum_simd_sum_float(const float *array, size_t n)vsum_simd_sum_double(const double *array, size_t n)
Cache-Friendly Sequential Summation:
vsum_cache_friendly_sum_int(const int *array, size_t n)vsum_cache_friendly_sum_float(const float *array, size_t n)vsum_cache_friendly_sum_double(const double *array, size_t n)
All functions require a pointer to the data array and the total number of elements (n). Integer sums return int64_t to prevent overflow. Floating-point sums return double for enhanced precision.
Example: Floating-Point SIMD Summation
// Assume 'float_array' is a pointer to your float data and 'num_elements' is its size.
float *float_array = /* ... allocation and initialization ... */;
size_t num_elements = /* ... size of array ... */;
// Calculate the sum using the SIMD-optimized function.
// VSUM automatically detects AVX/SSE support and uses the best available path.
double sum_result = vsum_simd_sum_float(float_array, num_elements);
printf("SIMD Sum of float array: %f\n", sum_result);
Technical Considerations
-
Runtime CPU Feature Detection: Uses
cpuidon x86-64 to dynamically enable SIMD paths, ensuring portability and preventing illegal instruction errors. -
Memory Alignment: SIMD functions perform best with memory aligned to vector width (e.g., 32 bytes for AVX).
VSUM_AVX_ALIGNMENTconstant is provided. Aligned loads are used when possible; unaligned loads serve as a fallback. -
Integer Overflow: Integer summation uses
int64_taccumulators to handle large sums without overflow. -
Floating-Point Precision: Floating-point summations use
doublefor accumulation where appropriate to mitigate precision loss. -
Error Handling: Basic checks for null pointers and zero elements are included. Thread creation errors are reported to
stderr.
Contribution Guidelines
Contributions via GitHub issues and pull requests are welcome. Please refer to the project repository for any specific contribution guidelines.
Licensing
VSUM is distributed under the BSD 2-Clause License. See the LICENSE file for full details.
Conclusion
VSUM offers a robust and efficient solution for array summation in C, demonstrating practical applications of multithreading, SIMD optimization, and cache-aware programming. It is suitable for developers seeking to accelerate numerical computations or explore advanced system-level optimization techniques.
Explore the repository and integrate VSUM into your projects:
git clone https://github.com/davidesantangelo/vsum.git