











































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






















































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)



























































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)
































































































































Using only AI to debug Terraform: A Case Study of how good is OpenAI at debugging!
This is a story of debugging with AI — and debugging AI itself. I ran a real Terraform pipeline with GPT-4 helping. It wrote perfect YAML — then failed to debug variable scope and folder mismatches. Here’s what I learned about LLMs, infra state, and human intuition. This technical case study analyzes the performance of GPT-4-turbo as a co-pilot in a real-world infrastructure-as-code (IaC) deployment of Azure Key Vault, executed entirely through a GitHub Actions CI/CD pipeline using OpenID Connect (OIDC) authentication. We juxtapose the LLM’s predictive reasoning capabilities against practical DevOps constraints, revealing where generative models assist and where they break down in orchestrated infrastructure workflows. 1. Research Objective The goal of this experiment was to evaluate whether a state-of-the-art large language model (LLM) like GPT-4-turbo can effectively serve as a debugging assistant for IaC tooling such as Terraform, under real DevOps conditions: Secure-by-default: No secrets exposed in VCS or workflows. Reusable infra: Module-based architecture across environments. CI/CD Compliant: OIDC-authenticated pipelines, linting, testing, validation. Terraform Native: No use of Cloud shell, no portal usage beyond initial SPN. 2. Experimental Setup Current High-Level Azure Architecture Stack: Infra Language: Terraform v1.5.7 Cloud: Azure (free tier) Pipeline: GitHub Actions + OIDC + Federated Credential Security: Azure Key Vault with RBAC, purge protection, soft delete LLM Used: GPT-4-turbo (March-April 2024 weights, 128K token window) Scope: Terraform modules (key_vault) and environment overlays (dev) Multi-job GitHub workflows: linting, formatting, plan/apply via OIDC login Docker-based linting enforcement using tflint-ruleset-azurerm 3. Metrics & Observations Metric Value Model GPT-4-turbo (OpenAI) LLM Parameters ~175 Billion Avg. Response Latency 2.3s Prompts Issued ~450 Terraform Executions 20+ CI cycles Terraform Lint Failures 4 Terraform Validate/Plan Failures 9 Human-Caught Errors 6 unique classes LLM-Caught Errors 10 classes (mostly syntactic) 4. Results: Failure Modes of LLM-Driven Infra Debugging 4.1 Temporal Scope Leakage in CI/CD Observation: GPT suggested setting TF_VAR_env_name via run using echo "env_name=dev" >> $GITHUB_ENV, expecting availability in the same job. Root Cause: Misunderstanding of job-level env: vs step-level shell env evaluation timing. Failure Class: Predictive token modeling cannot simulate runtime execution graph. 4.2 Path Normalization Error Observation: GPT advised working-directory: environments/dev, while repo contained environments/DEV. Root Cause: GPT lacks real filesystem awareness and cannot verify path validity on Linux runners. Failure Class: Context-blind suggestion due to static text-based token continuation. 4.3 Invalid Provider Scoping Observation: GPT-generated multiple unaliased provider "azurerm" {} blocks at different scopes. Impact: Terraform failed with “duplicate provider configuration” due to ambiguous resolution hierarchy. Failure Class: Incomplete graph modeling of provider resolution context. 4.4 Misrepresentation of Module Semantics Observation: GPT attempted to define a module within another module, breaching Terraform semantics. Failure Class: Lack of abstract syntax tree (AST) enforcement in output generation. 4.5 Improper Plugin Reference Observation: GPT suggested a non-existent terraform-linters/tflint-action instead of the official tflint-ruleset-azurerm. Fix: Manual research and verification through the GHCR registry and plugin author docs. Failure Class: Dataset skew from outdated or hallucinated references. 5. Final Architecture and Output Terraform Structure: modules/key_vault + environments/dev CI/CD Workflow: Lint, fmt, validate, plan, apply Auth Flow: OIDC using Federated Credential tied to GitHub Actions Key Vault Configuration: RBAC enabled, soft delete (7d), purge protection Code Quality Gate: TFLint inside custom Docker container via GHCR 6. LLM Behavior Analysis 7. Conclusion While GPT-4-turbo accelerated code generation, linting scaffolds, and identity federation concepts, it lacked awareness of temporal context, runtime behavior, and Terraform’s execution model. It served well for: Generating Terraform scaffolding Writing initial workflows Prototyping access policy logic It failed in areas requiring: Filesystem introspection GitHub Actions runner behavior modeling Terraform variable scope comprehension Plugin compatibility resolution Endless DevOps pipeline runs to test OpenAI debugs Verdict: ChatGPT = excellent code generator, mediocre Terraform runtime debugger. 8. Human Engineering Edge I was able to: Infer variable propagation issues across GitHub Actions jobs Map Terraform’s graph to outputs and error context Catch real-time path mismatches from CI log traces Identify red
This is a story of debugging with AI — and debugging AI itself.
I ran a real Terraform pipeline with GPT-4 helping. It wrote perfect YAML — then failed to debug variable scope and folder mismatches. Here’s what I learned about LLMs, infra state, and human intuition.
This technical case study analyzes the performance of GPT-4-turbo as a co-pilot in a real-world infrastructure-as-code (IaC) deployment of Azure Key Vault, executed entirely through a GitHub Actions CI/CD pipeline using OpenID Connect (OIDC) authentication. We juxtapose the LLM’s predictive reasoning capabilities against practical DevOps constraints, revealing where generative models assist and where they break down in orchestrated infrastructure workflows.
1. Research Objective
The goal of this experiment was to evaluate whether a state-of-the-art large language model (LLM) like GPT-4-turbo can effectively serve as a debugging assistant for IaC tooling such as Terraform, under real DevOps conditions:
Secure-by-default: No secrets exposed in VCS or workflows.
Reusable infra: Module-based architecture across environments.
CI/CD Compliant: OIDC-authenticated pipelines, linting, testing, validation.
Terraform Native: No use of Cloud shell, no portal usage beyond initial SPN.
2. Experimental Setup
Current High-Level Azure Architecture
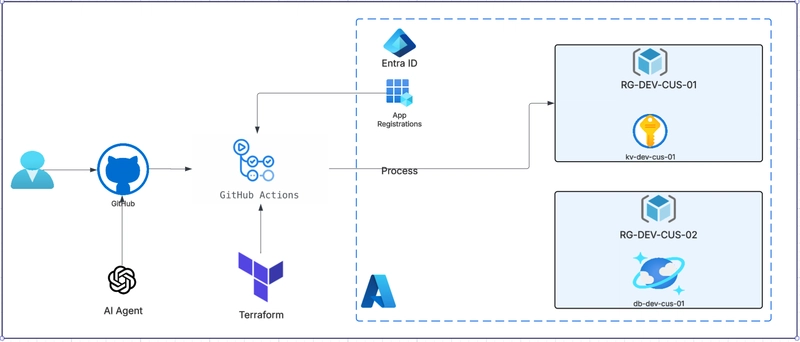
Stack:
Infra Language: Terraform v1.5.7
Cloud: Azure (free tier)
Pipeline: GitHub Actions + OIDC + Federated Credential
Security: Azure Key Vault with RBAC, purge protection, soft delete
LLM Used: GPT-4-turbo (March-April 2024 weights, 128K token window)
Scope:
- Terraform modules (key_vault) and environment overlays (dev)
- Multi-job GitHub workflows: linting, formatting, plan/apply via OIDC login
- Docker-based linting enforcement using tflint-ruleset-azurerm

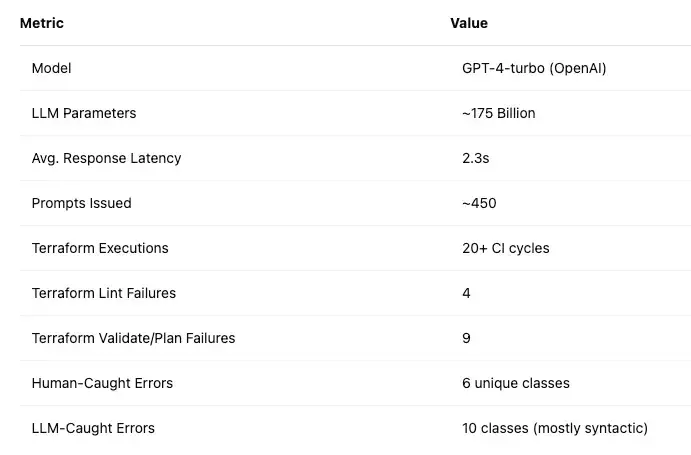
3. Metrics & Observations
Metric Value Model GPT-4-turbo (OpenAI) LLM Parameters ~175 Billion Avg. Response Latency 2.3s Prompts Issued ~450 Terraform Executions 20+ CI cycles Terraform Lint Failures 4 Terraform Validate/Plan Failures 9 Human-Caught Errors 6 unique classes LLM-Caught Errors 10 classes (mostly syntactic)
4. Results: Failure Modes of LLM-Driven Infra Debugging
4.1 Temporal Scope Leakage in CI/CD
Observation: GPT suggested setting TF_VAR_env_name via run using echo "env_name=dev" >> $GITHUB_ENV, expecting availability in the same job.
Root Cause: Misunderstanding of job-level env: vs step-level shell env evaluation timing.
Failure Class: Predictive token modeling cannot simulate runtime execution graph.
4.2 Path Normalization Error
Observation: GPT advised working-directory: environments/dev, while repo contained environments/DEV.
Root Cause: GPT lacks real filesystem awareness and cannot verify path validity on Linux runners.
Failure Class: Context-blind suggestion due to static text-based token continuation.
4.3 Invalid Provider Scoping
Observation: GPT-generated multiple unaliased provider "azurerm" {} blocks at different scopes.
Impact: Terraform failed with “duplicate provider configuration” due to ambiguous resolution hierarchy.
Failure Class: Incomplete graph modeling of provider resolution context.
4.4 Misrepresentation of Module Semantics
Observation: GPT attempted to define a module within another module, breaching Terraform semantics.
Failure Class: Lack of abstract syntax tree (AST) enforcement in output generation.
4.5 Improper Plugin Reference
Observation: GPT suggested a non-existent terraform-linters/tflint-action instead of the official tflint-ruleset-azurerm.
Fix: Manual research and verification through the GHCR registry and plugin author docs.
Failure Class: Dataset skew from outdated or hallucinated references.
5. Final Architecture and Output
- Terraform Structure: modules/key_vault + environments/dev
- CI/CD Workflow: Lint, fmt, validate, plan, apply
- Auth Flow: OIDC using Federated Credential tied to GitHub Actions
- Key Vault Configuration: RBAC enabled, soft delete (7d), purge protection
- Code Quality Gate: TFLint inside custom Docker container via GHCR
6. LLM Behavior Analysis
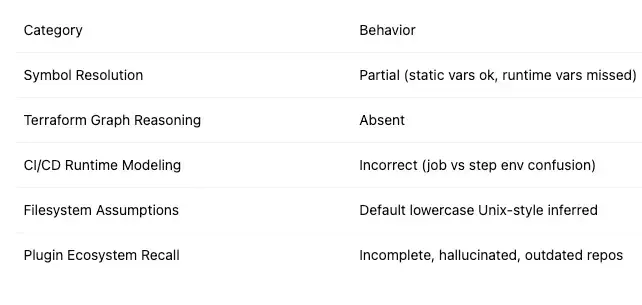
7. Conclusion
While GPT-4-turbo accelerated code generation, linting scaffolds, and identity federation concepts, it lacked awareness of temporal context, runtime behavior, and Terraform’s execution model. It served well for:
- Generating Terraform scaffolding
- Writing initial workflows
- Prototyping access policy logic
- It failed in areas requiring:
- Filesystem introspection
- GitHub Actions runner behavior modeling
- Terraform variable scope comprehension
- Plugin compatibility resolution
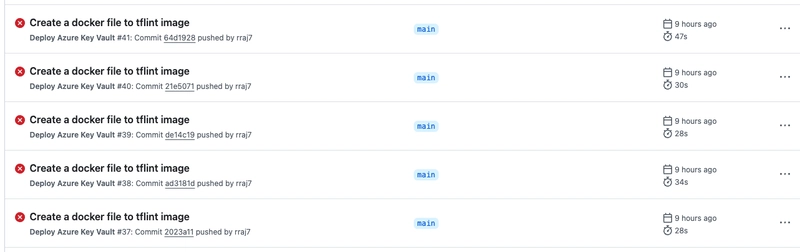
Endless DevOps pipeline runs to test OpenAI debugs
Verdict: ChatGPT = excellent code generator, mediocre Terraform runtime debugger.
8. Human Engineering Edge
I was able to:
Infer variable propagation issues across GitHub Actions jobs
Map Terraform’s graph to outputs and error context
Catch real-time path mismatches from CI log traces
Identify redundant provider declarations
Correct plugin references manually from public sources
9. Future Work
Integrate AI feedback loops with plan output parsing
Feed logs into LLM in real time for context-aware reasoning
Experiment with fine-tuning on the Terraform-specific corpus
Add multi-step retry decision trees for common CI errors.


