


































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)
























































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)























































































































_roibu_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




 CISO’s Core Focus.webp?#)







































































































![M4 MacBook Air Drops to Just $849 - Act Fast! [Lowest Price Ever]](https://www.iclarified.com/images/news/97140/97140/97140-640.jpg)
![Apple Smart Glasses Not Close to Being Ready as Meta Targets 2025 [Gurman]](https://www.iclarified.com/images/news/97139/97139/97139-640.jpg)
![iPadOS 19 May Introduce Menu Bar, iOS 19 to Support External Displays [Rumor]](https://www.iclarified.com/images/news/97137/97137/97137-640.jpg)





























































































Use TypeScript instead of Python for ETL pipelines
Written by Muhammed Ali✏️ This article illustrates building an ETL pipeline entirely in TypeScript to extract weather data from the OpenWeatherMap API and COVID-19 statistics from a GitHub CSV, transform them into a unified structure, and load the results into a PostgreSQL database using Prisma. The process uses TypeScript’s static typing and async/await syntax for clearer API interactions and error handling, and it automates the workflow using node‑cron. Why TypeScript makes more sense for ETL ETL, or Extract, Transform, Load, is a data processing pattern where information is collected from external sources, transformed into a consistent structure, and stored in a database for further use or analysis. An ETL pipeline automates this flow, making sure data is ingested, transformed, and persisted in a repeatable way. TypeScript’s design enforces type safety from the start of this process, significantly reducing runtime errors that may occur when data from external sources doesn’t meet expectations. Projects that combine multiple APIs and file formats benefit from compile‑time checks, ensuring that every piece of data adheres to the defined structure. This approach minimizes debugging surprises that often plague dynamically typed Python applications and results in a maintainable codebase where refactoring is safe and predictable. Setting up the TypeScript project This section guides you through creating a new Node.js project and setting up TypeScript for building your ETL pipeline. The project structure is as follows: project/ ├── prisma/ │ └── schema.prisma ├── src/ │ ├── extract.ts │ ├── transform.ts │ ├── load.ts │ └── schedule.ts ├── package.json └── tsconfig.json Begin by creating a new Node.js project and configuring TypeScript. Paste the following code in your tsconfig.json in the project’s root. It might look like this: { "compilerOptions": { "target": "ES2019", "module": "commonjs", "strict": true, "esModuleInterop": true, "outDir": "./dist" }, "include": ["src/**/*"] } With this configuration, initialize your project and install dependencies. Use npm to install libraries for HTTP requests, scheduling, CSV parsing, and database interaction: npm init -y npm install axios node-cron papaparse @prisma/client npm install --save-dev typescript ts-node @types/node @types/papaparse npx prisma init Extracting data from external APIs The extraction phase involves calling the OpenWeatherMap API and downloading COVID-19 data hosted on GitHub. In a file named src/extract.ts, the code below fetches weather data for a specific city and retrieves CSV content for COVID-19 data: import axios from 'axios'; import Papa from 'papaparse'; export interface WeatherResponse { main: { temp: number; humidity: number }; weather: { description: string }[]; } export async function fetchWeatherData(city: string, apiKey: string): Promise { const url = `https://api.openweathermap.org/data/2.5/weather?q=${city}&appid=${apiKey}&units=metric`; const response = await axios.get(url); return response.data; } export async function fetchCovidData(): Promise { const csvUrl = 'https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_daily_reports/11-13-2022.csv'; const response = await axios.get(csvUrl, { responseType: 'text' }); const parsed = Papa.parse(response.data, { header: true, skipEmptyLines: true, // Ignores blank lines dynamicTyping: true, // Converts numbers correctly }); if (parsed.errors.length) { console.warn('CSV parsing errors:', parsed.errors); // Logs errors instead of throwing immediately } // Filter out completely invalid rows (rows missing essential fields) return parsed.data.filter(row => row.Country_Region && row.Last_Update) as any[]; } This code fetches weather data from the OpenWeatherMap API and COVID‑19 CSV data from GitHub using Axios, then parses and filters the CSV data with papaparse for structured, type-safe results. It defines a WeatherResponse interface to ensure the weather data adheres to expected types while gracefully handling CSV parsing errors and filtering out incomplete rows. TypeScript's async/await model allows developers to write asynchronous API calls in a linear, easy-to-read style, reducing callback nesting and simplifying error handling. In contrast, Python’s requests model is synchronous by default, requiring additional frameworks or workarounds for async behavior, which can complicate code and reduce clarity. Transforming data with TypeScript Transformation enforces a consistent schema before loading data into the database. In src/transform.ts, data from the weather API and COVID-19 CSV are normalized. The following example aggregates COVID-19 data for the United Kingdom and merges it with weather information: export interface TransformedData { city: string; temperature: nu
Written by Muhammed Ali✏️
This article illustrates building an ETL pipeline entirely in TypeScript to extract weather data from the OpenWeatherMap API and COVID-19 statistics from a GitHub CSV, transform them into a unified structure, and load the results into a PostgreSQL database using Prisma. The process uses TypeScript’s static typing and async/await syntax for clearer API interactions and error handling, and it automates the workflow using node‑cron.
Why TypeScript makes more sense for ETL
ETL, or Extract, Transform, Load, is a data processing pattern where information is collected from external sources, transformed into a consistent structure, and stored in a database for further use or analysis. An ETL pipeline automates this flow, making sure data is ingested, transformed, and persisted in a repeatable way.
TypeScript’s design enforces type safety from the start of this process, significantly reducing runtime errors that may occur when data from external sources doesn’t meet expectations.
Projects that combine multiple APIs and file formats benefit from compile‑time checks, ensuring that every piece of data adheres to the defined structure. This approach minimizes debugging surprises that often plague dynamically typed Python applications and results in a maintainable codebase where refactoring is safe and predictable.
Setting up the TypeScript project
This section guides you through creating a new Node.js project and setting up TypeScript for building your ETL pipeline. The project structure is as follows:
project/
├── prisma/
│ └── schema.prisma
├── src/
│ ├── extract.ts
│ ├── transform.ts
│ ├── load.ts
│ └── schedule.ts
├── package.json
└── tsconfig.json
Begin by creating a new Node.js project and configuring TypeScript. Paste the following code in your tsconfig.json in the project’s root. It might look like this:
{
"compilerOptions": {
"target": "ES2019",
"module": "commonjs",
"strict": true,
"esModuleInterop": true,
"outDir": "./dist"
},
"include": ["src/**/*"]
}
With this configuration, initialize your project and install dependencies. Use npm to install libraries for HTTP requests, scheduling, CSV parsing, and database interaction:
npm init -y
npm install axios node-cron papaparse @prisma/client
npm install --save-dev typescript ts-node @types/node @types/papaparse
npx prisma init
Extracting data from external APIs
The extraction phase involves calling the OpenWeatherMap API and downloading COVID-19 data hosted on GitHub. In a file named src/extract.ts, the code below fetches weather data for a specific city and retrieves CSV content for COVID-19 data:
import axios from 'axios';
import Papa from 'papaparse';
export interface WeatherResponse {
main: { temp: number; humidity: number };
weather: { description: string }[];
}
export async function fetchWeatherData(city: string, apiKey: string): Promise<WeatherResponse> {
const url = `https://api.openweathermap.org/data/2.5/weather?q=${city}&appid=${apiKey}&units=metric`;
const response = await axios.get<WeatherResponse>(url);
return response.data;
}
export async function fetchCovidData(): Promise<any[]> {
const csvUrl = 'https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_daily_reports/11-13-2022.csv';
const response = await axios.get(csvUrl, { responseType: 'text' });
const parsed = Papa.parse<{ Country_Region: string; Last_Update: string }>(response.data, {
header: true,
skipEmptyLines: true, // Ignores blank lines
dynamicTyping: true, // Converts numbers correctly
});
if (parsed.errors.length) {
console.warn('CSV parsing errors:', parsed.errors); // Logs errors instead of throwing immediately
}
// Filter out completely invalid rows (rows missing essential fields)
return parsed.data.filter(row => row.Country_Region && row.Last_Update) as any[];
}
This code fetches weather data from the OpenWeatherMap API and COVID‑19 CSV data from GitHub using Axios, then parses and filters the CSV data with papaparse for structured, type-safe results. It defines a WeatherResponse interface to ensure the weather data adheres to expected types while gracefully handling CSV parsing errors and filtering out incomplete rows. TypeScript's async/await model allows developers to write asynchronous API calls in a linear, easy-to-read style, reducing callback nesting and simplifying error handling. In contrast, Python’s requests model is synchronous by default, requiring additional frameworks or workarounds for async behavior, which can complicate code and reduce clarity.
Transforming data with TypeScript
Transformation enforces a consistent schema before loading data into the database. In src/transform.ts, data from the weather API and COVID-19 CSV are normalized. The following example aggregates COVID-19 data for the United Kingdom and merges it with weather information:
export interface TransformedData {
city: string;
temperature: number;
humidity: number;
weatherDescription: string;
confirmedCases: number;
deaths: number;
recovered: number;
activeCases: number;
}
export function transformDataMultiple(
weather: { main: { temp: number; humidity: number }; weather: { description: string }[]; name?: string },
covidData: any[]
): TransformedData[] {
const ukData = covidData.filter((row) => row['Country_Region'] === 'United Kingdom');
if (!ukData.length) {
throw new Error('No COVID-19 data found for United Kingdom.');
}
return ukData.map((row) => ({
city: weather.name || 'London',
temperature: weather.main.temp,
humidity: weather.main.humidity,
weatherDescription: weather.weather.length > 0 ? weather.weather[0].description : 'Unknown',
confirmedCases: parseInt(row['Confirmed'], 10) || 0,
deaths: parseInt(row['Deaths'], 10) || 0,
recovered: parseInt(row['Recovered'], 10) || 0,
activeCases: parseInt(row['Active'], 10) || 0
}));
}
Using TypeScript interfaces and runtime validations ensures that if the API data changes unexpectedly, the error is caught early during transformation rather than after data insertion into the database.
Loading data into PostgreSQL with Prisma
The final stage uses Prisma to perform type-safe database operations. Define your schema in prisma/schema.prisma:
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
}
model Record {
id Int @id @default(autoincrement())
city String
temperature Float
humidity Float
weatherDescription String
confirmedCases Int
deaths Int
recovered Int
activeCases Int
}
This Prisma schema defines a PostgreSQL data source using an environment variable for the connection URL, configures a JavaScript client generator, and declares a Record model with fields for location, weather data (temperature, humidity, description), and COVID-19 case statistics (confirmed, deaths, recovered, active), using an auto-incrementing integer as the primary key. Now, generate the Prisma client with npx prisma generate, then create a src/load.ts file with the following code:
import { PrismaClient } from '@prisma/client';
import { TransformedData } from './transform';
const prisma = new PrismaClient();
export async function loadData(data: TransformedData[]): Promise<void> {
try {
for (const record of data) {
await prisma.record.create({
data: {
city: record.city,
temperature: record.temperature,
humidity: record.humidity,
weatherDescription: record.weatherDescription,
confirmedCases: record.confirmedCases,
deaths: record.deaths,
recovered: record.recovered,
activeCases: record.activeCases
}
});
}
} catch (error) {
console.error('Error loading data:', error);
throw error;
} finally {
await prisma.$disconnect();
}
}
This approach enforces the database schema at both design time and runtime. Prisma’s type-safe queries ensure that only valid data reaches the PostgreSQL database, preventing corruption due to schema mismatches.
Running and testing the ETL pipeline
Once the ETL pipeline is set up, you need to test it to ensure it correctly extracts, transforms, and loads the data into your PostgreSQL database. Follow these steps: Ensure that your PostgreSQL instance is running and accessible. If using Docker, you can start a PostgreSQL container with:
docker run --name postgres -e POSTGRES_USER=admin -e POSTGRES_PASSWORD=admin -e POSTGRES_DB=etl -p 5432:5432 -d postgres
Set the DATABASE_URL environment variable in a .env file. While you are in there, you can also paste in your OpenWeather API key:
DATABASE_URL="postgresql://admin:admin@localhost:5432/etl"
OPENWEATHER_API_KEY="xxxxxxxxxxxxxxxxxxxxx"
Now, run the following command to ensure that the database schema is properly applied:
npx prisma migrate dev --name init
This will create the necessary tables in your database. Next, run the extraction, transformation, and loading steps sequentially by creating a script src/index.ts:
import { fetchWeatherData, fetchCovidData } from './extract';
import { transformData } from './transform';
import { loadData } from './load';
const CITY = 'London';
const API_KEY = process.env.OPENWEATHER_API_KEY;
(async () => {
try {
if (!API_KEY) throw new Error("Missing OpenWeather API Key");
console.log('Fetching data...');
const weatherData = await fetchWeatherData(CITY, API_KEY);
const covidData = await fetchCovidData();
console.log('Transforming data...');
const transformedData = transformData(weatherData, covidData);
console.log('Loading data into the database...');
await loadData(transformedData);
console.log('ETL process completed successfully.');
} catch (error) {
console.error('ETL process failed:', error);
}
})();
This script orchestrates the ETL (Extract, Transform, Load) process by sequentially fetching weather data for London from OpenWeather and COVID-19 statistics from GitHub, transforming them into a unified structure, and loading the processed data into a PostgreSQL database. It ensures the OpenWeather API key is set and logs each stage for visibility. Run the ETL process with the following command:
npx tsc
node dist/index.js
After running the script, check your database to verify the data was loaded correctly:
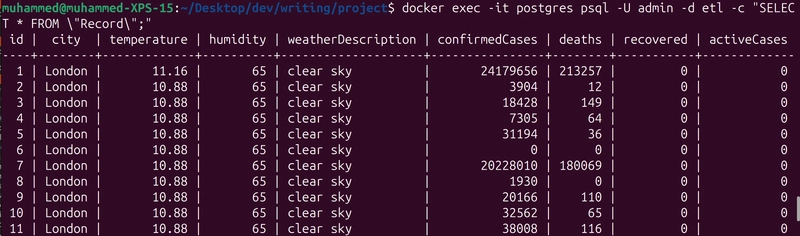
docker exec -it postgres psql -U admin -d etl -c "SELECT * FROM \"Record\";"
This should return the weather and COVID-19 data stored in your PostgreSQL database:
Automating and scheduling the ETL pipeline
The final stage involves automating the ETL process. With Python, you would need schedulers like Airflow or Celery. These third-party tools require a separate message broker and introduce additional layers of complexity for distributed task management. Meanwhile, TypeScript’s scheduling libraries, like node‑cron, integrate directly into the application without extra overhead. Automation is handled by node‑cron, which schedules the complete ETL process periodically. In src/schedule.ts, integrate the extraction, transformation, and loading steps into a scheduled task:
import cron from 'node-cron';
import { fetchWeatherData, fetchCovidData } from './extract';
import { transformData } from './transform';
import { loadData } from './load';
const OPENWEATHER_API_KEY = process.env.OPENWEATHER_API_KEY || '';
const CITY = 'London';
cron.schedule('0 * * * *', async () => {
console.log('Starting ETL job...');
try {
const weather = await fetchWeatherData(CITY, OPENWEATHER_API_KEY);
const covidData = await fetchCovidData();
const transformed = transformData(weather, covidData);
await loadData(transformed);
console.log('ETL job completed successfully.');
} catch (error) {
console.error('ETL job failed:', error);
}
});
This scheduled task triggers at the start of every hour. The integration of async/await ensures that each step is executed sequentially and that errors are caught and logged in a centralized manner. After setting the DATABASE_URL and OPENWEATHER_API_KEY environment variables, compile and run the scheduled ETL process using:
npx ts-node src/schedule.ts
This command starts the ETL process, executing extraction, transformation, and loading on the defined schedule. The console output will indicate the progress and success or failure of each task.
TypeScript vs. Python: Why TypeScript wins
The combination of static type checking, consistent data transformation, and a unified development environment gives TypeScript a clear advantage over Python for building ETL pipelines. With TypeScript, the entire stack, from API extraction to data loading, remains type-safe, reducing the debugging overhead that Python developers often face with runtime type errors.
Modern libraries like Prisma and node‑cron streamline development and deployment, ensuring that the entire pipeline can be built and maintained with fewer surprises.
TypeScript’s async/await model also enables clean, linear code that’s easier to maintain compared to Python’s often fragmented approach to asynchronous behavior. Overall, TypeScript offers a more maintainable and reliable ETL pipeline compared to Python’s approach. Developers gain a unified experience from API integration to database loading while minimizing unexpected runtime issues.
Even though some of the data we used doesn’t change very often and may not be up to date, this is a proof of concept, so feel free to apply it in your own projects.
LogRocket: Full visibility into your web and mobile apps
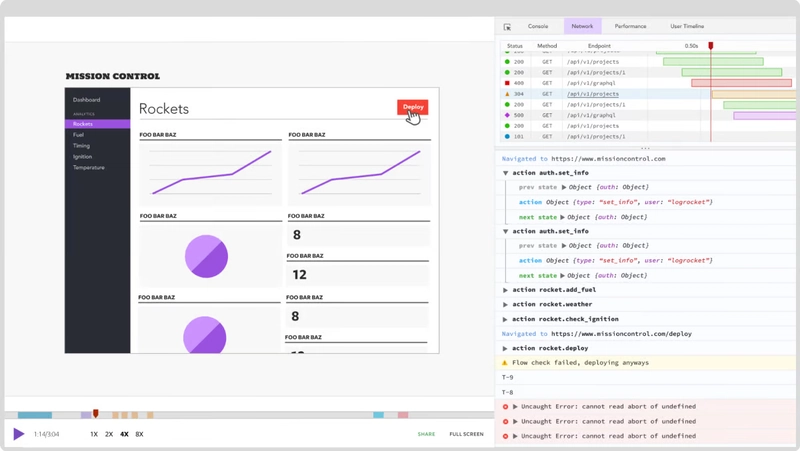
LogRocket is a frontend application monitoring solution that lets you replay problems as if they happened in your own browser. Instead of guessing why errors happen or asking users for screenshots and log dumps, LogRocket lets you replay the session to quickly understand what went wrong. It works perfectly with any app, regardless of framework, and has plugins to log additional context from Redux, Vuex, and @ngrx/store.
In addition to logging Redux actions and state, LogRocket records console logs, JavaScript errors, stacktraces, network requests/responses with headers + bodies, browser metadata, and custom logs. It also instruments the DOM to record the HTML and CSS on the page, recreating pixel-perfect videos of even the most complex single-page and mobile apps.



