


































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)























































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)























































































































_roibu_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)




 CISO’s Core Focus.webp?#)







































































































![M4 MacBook Air Drops to Just $849 - Act Fast! [Lowest Price Ever]](https://www.iclarified.com/images/news/97140/97140/97140-640.jpg)
![Apple Smart Glasses Not Close to Being Ready as Meta Targets 2025 [Gurman]](https://www.iclarified.com/images/news/97139/97139/97139-640.jpg)
![iPadOS 19 May Introduce Menu Bar, iOS 19 to Support External Displays [Rumor]](https://www.iclarified.com/images/news/97137/97137/97137-640.jpg)
















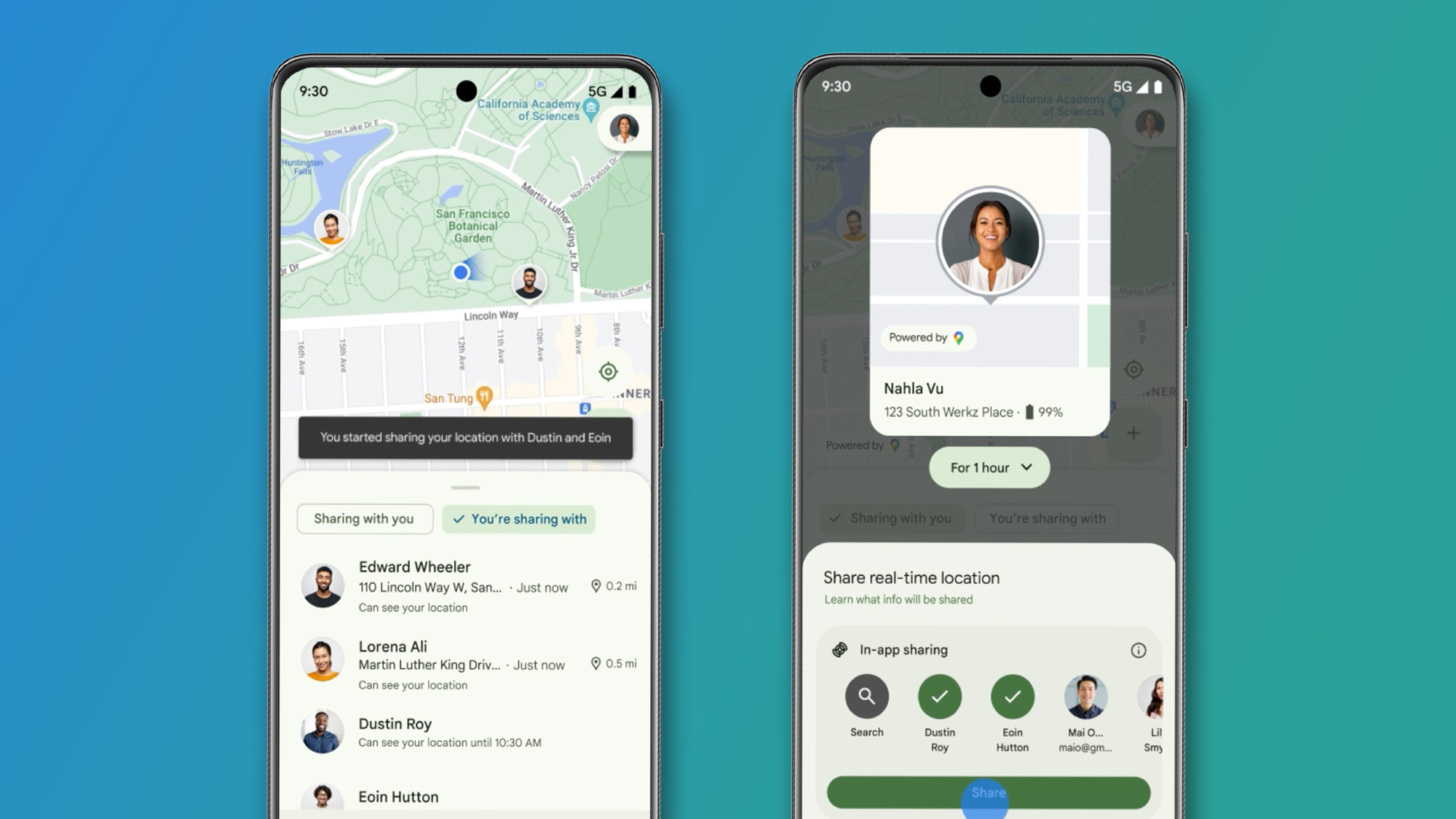













































































Building Fully Autonomous Data Analysis Pipelines with the PraisonAI Agent Framework: A Coding Implementation
In this tutorial, we demonstrate how PraisonAI Agents can elevate your data analysis from manual scripting to a fully autonomous, AI-driven pipeline. In a few natural-language prompts, you’ll learn to orchestrate every stage of the workflow, loading CSV or Excel files, filtering rows, summarizing trends, grouping by custom fields, pivoting tables, and exporting results to […] The post Building Fully Autonomous Data Analysis Pipelines with the PraisonAI Agent Framework: A Coding Implementation appeared first on MarkTechPost.

In this tutorial, we demonstrate how PraisonAI Agents can elevate your data analysis from manual scripting to a fully autonomous, AI-driven pipeline. In a few natural-language prompts, you’ll learn to orchestrate every stage of the workflow, loading CSV or Excel files, filtering rows, summarizing trends, grouping by custom fields, pivoting tables, and exporting results to both CSV and Excel, without writing traditional Pandas code. In this implementation, under the hood, PraisonAI leverages Google Gemini to interpret your instructions and invoke the appropriate tools. At the same time, features such as self-reflection and verbose logging provide you with full visibility into each intermediate reasoning step.
!pip install "praisonaiagents[llm]"We install the core PraisonAI Agents library, along with its LLM integration extras, which bring in all necessary dependencies (such as Litellm and Gemini connectors) to drive autonomous workflows with large language models.
import os
os.environ["GEMINI_API_KEY"] = "Use Your API Key"
llm_id = "gemini/gemini-1.5-flash-8b"We configure your environment for Gemini access by setting your API key, then specify which Gemini model (the “1.5-flash-8b” variant) the PraisonAI Agent should use as its LLM backend.
from google.colab import files
uploaded = files.upload()
csv_path = next(iter(uploaded))
print("Loaded:", csv_path)We leverage Colab’s file‐upload widget to let you pick a local CSV, capture its filename into csv_path, and print a confirmation, making it easy to bring your data into the notebook interactively.
from praisonaiagents import Agent
from praisonaiagents.tools import (
read_csv, filter_data, get_summary, group_by, pivot_table, write_csv
)
agent = Agent(
instructions="You are a Data Analyst Agent using Google Gemini.",
llm=llm_id,
tools=[
read_csv, filter_data, get_summary, group_by, pivot_table, write_csv
],
self_reflect=True,
verbose=True
)We instantiate a PraisonAI Agent wired to Google Gemini, equipping it with data‐analysis tools (CSV I/O, filtering, summarization, grouping, pivoting, and export). Enabling self-reflect allows the agent to critique its reasoning, while verbose mode streams detailed tool-invocation logs for transparency.
result = agent.start(f"""
1. read_csv to load data from "{csv_path}"
2. get_summary to outline overall trends
3. filter_data to keep rows where Close > 800
4. group_by Year to average closing price
5. pivot_table to format the output table
""")
print(result)We send a clear, step-by-step prompt to your PraisonAI Agent, instructing it to load the CSV, summarize overall trends, filter for closing prices over $ 800, compute yearly averages, and pivot the table. The agent then prints out the combined response (including any generated summary or data output).



In conclusion, we have constructed an end-to-end data pipeline powered by PraisonAI Agents and Gemini, which goes from raw data upload to insightful visualizations and downloadable reports in just a few cells. We’ve seen how PraisonAI’s declarative toolset replaces dozens of lines of boilerplate code with concise, human-readable steps, and how built-in mechanisms, such as result caching and dual-mode API invocation, ensure both efficiency and reliability.
Sources
Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 90k+ ML SubReddit.




