![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)

































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)









































































































.png?#)






(1).jpg?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)





























_NicoElNino_Alamy.png?#)
.webp?#)
.webp?#)




































































































![Apple to Source More iPhones From India to Offset China Tariff Costs [Report]](https://www.iclarified.com/images/news/96954/96954/96954-640.jpg)
![Blackmagic Design Unveils DaVinci Resolve 20 With Over 100 New Features and AI Tools [Video]](https://www.iclarified.com/images/news/96951/96951/96951-640.jpg)

























































































































Step-by-Step guide on Live Streaming weather data from Openweather api to MongoDB using Kafka
Introduction In this guide, we’ll stream data from the OpenWeather API and store it in MongoDB, using Kafka for fault tolerance. Before we start, make sure you’ve already set up a cloud server—I'm using an EC2 instance on AWS. Also, sign up on OpenWeatherMap and get your API key—we’ll use this to fetch the weather data. This guide is broken down into 5 parts: Setting up our cloud environment Setting up our Kafka environment Setting up our MongoDB environment Writing our producer and consumer Python files Tying everything together to complete the project 1. Setting Up Our Cloud Environment We'll SSH into our EC2 server and check if the Kafka port (default is 9092) is free. a) SSH into EC2 Open your terminal (I’m using Git Bash) and run the SSH command from the EC2 Connect section: ssh -i your-key.pem ec2-user@your-ec2-ip b) Check if Kafka Port is Free Once logged into the server, run the following: $ sudo lsof -i :9092 If it returns nothing, great—no service is using that port, so Kafka is good to go. 2. Setting Up Our Kafka Environment Head over to Kafka Downloads and copy the link for version 4.0. a) Download Kafka Run this command to download kafka binary files: $ wget https://downloads.apache.org/kafka/4.0.0/kafka_2.13-4.0.0.tgz b) Extract Kafka Run this command to extract the files: $ tar -xzvf kafka_2.13-4.0.0.tgz You can rename the folder for convenience if you want. 3. Setting Up Our MongoDB Environment We’ll use MongoDB Atlas to host our database. Sign up or log in, create a cluster, and grab your connection string (we’ll use this in our Python script). 4. Writing Our Producer and Consumer Python Files a)producer.py — Pulling from OpenWeather API and Writing to Kafka: from confluent_kafka import Producer import requests, json, os, time from dotenv import load_dotenv import pandas as pd # Load environment variables from .env file load_dotenv() weather_api_key = os.getenv('WEATHER_API_KEY') # Your OpenWeather API key city_name = 'Nairobi' # Build API URL weather_url = f'https://api.openweathermap.org/data/2.5/weather?q={city_name}&appid={weather_api_key}' # Kafka Producer Configuration config = { 'bootstrap.servers': 'localhost:9092', 'client.id': 'python-producer' } producer = Producer(config) topic = 'weather_topic' # Function to extract data from API def extract_data(): response = requests.get(weather_url) data = response.json() weather_df = pd.DataFrame(data['weather'], index=[0]) temp_df = pd.DataFrame(data['main'], index=[0]) location_df = pd.DataFrame({'country': data['sys']['country'], 'city': city_name}, index=[0]) merged_df = pd.merge(pd.merge(location_df, weather_df, left_index=True, right_index=True), temp_df, left_index=True, right_index=True) return merged_df # Function to transform the data def transform_data(df): df = df.drop(columns=['id', 'icon']) # Drop unnecessary columns cols = ['temp', 'feels_like', 'temp_min', 'temp_max'] df[cols] = df[cols] - 273 # Convert from Kelvin to Celsius return df.to_dict(orient='records') # Optional callback for delivery status def delivery_report(err, msg): if err: print(f'Delivery failed: {err}') else: print(f'Delivered to {msg.topic()}[{msg.partition()}]') # Continuous streaming loop while True: data = extract_data() transformed = transform_data(data) for record in transformed: producer.produce(topic, value=json.dumps(record), callback=delivery_report) producer.poll(0) time.sleep(600) # Wait for 10 minutes before fetching again Explanation: We load API keys from .env for security.Extract weather data, clean it, and convert temperatures and send each data point to Kafka every 10 minutes since our api sends the data every 10 mins b)consumer.py — Consuming from Kafka and Pushing to MongoDB from confluent_kafka import Consumer, KafkaError, KafkaException from dotenv import load_dotenv import os, json, time from pymongo.mongo_client import MongoClient from pymongo.server_api import ServerApi # Load MongoDB connection string from .env load_dotenv() uri = os.getenv('DB_STRING') # Connect to MongoDB client = MongoClient(uri, server_api=ServerApi('1')) db = client.weather_data # You can name this whatever you want collection = db.reports # Kafka Consumer configuration config = { 'bootstrap.servers': 'localhost:9092', 'group.id': 'weather-consumer-group', 'auto.offset.reset': 'earliest' } consumer = Consumer(config) topic = 'weather_topic' consumer.subscribe([topic]) # Function to insert data into MongoDB def load_data(records): collection.insert_many(records) # Consume messages loop while True: try: msg = consumer.poll(1.0) if msg is None: print("No message received.") elif msg.error(): if msg.error().code() ==
Introduction
In this guide, we’ll stream data from the OpenWeather API and store it in MongoDB, using Kafka for fault tolerance. Before we start, make sure you’ve already set up a cloud server—I'm using an EC2 instance on AWS. Also, sign up on OpenWeatherMap and get your API key—we’ll use this to fetch the weather data.
This guide is broken down into 5 parts:
- Setting up our cloud environment
- Setting up our Kafka environment
- Setting up our MongoDB environment
- Writing our producer and consumer Python files
- Tying everything together to complete the project
1. Setting Up Our Cloud Environment
We'll SSH into our EC2 server and check if the Kafka port (default is 9092) is free.
a) SSH into EC2
Open your terminal (I’m using Git Bash) and run the SSH command from the EC2 Connect section:
ssh -i your-key.pem ec2-user@your-ec2-ip
b) Check if Kafka Port is Free
Once logged into the server, run the following:
$ sudo lsof -i :9092
If it returns nothing, great—no service is using that port, so Kafka is good to go.
2. Setting Up Our Kafka Environment
Head over to Kafka Downloads and copy the link for version 4.0.
a) Download Kafka
Run this command to download kafka binary files:
$ wget https://downloads.apache.org/kafka/4.0.0/kafka_2.13-4.0.0.tgz
b) Extract Kafka
Run this command to extract the files:
$ tar -xzvf kafka_2.13-4.0.0.tgz
You can rename the folder for convenience if you want.
3. Setting Up Our MongoDB Environment
We’ll use MongoDB Atlas to host our database. Sign up or log in, create a cluster, and grab your connection string (we’ll use this in our Python script).
4. Writing Our Producer and Consumer Python Files
a)producer.py — Pulling from OpenWeather API and Writing to Kafka:
from confluent_kafka import Producer
import requests, json, os, time
from dotenv import load_dotenv
import pandas as pd
# Load environment variables from .env file
load_dotenv()
weather_api_key = os.getenv('WEATHER_API_KEY') # Your OpenWeather API key
city_name = 'Nairobi'
# Build API URL
weather_url = f'https://api.openweathermap.org/data/2.5/weather?q={city_name}&appid={weather_api_key}'
# Kafka Producer Configuration
config = {
'bootstrap.servers': 'localhost:9092',
'client.id': 'python-producer'
}
producer = Producer(config)
topic = 'weather_topic'
# Function to extract data from API
def extract_data():
response = requests.get(weather_url)
data = response.json()
weather_df = pd.DataFrame(data['weather'], index=[0])
temp_df = pd.DataFrame(data['main'], index=[0])
location_df = pd.DataFrame({'country': data['sys']['country'], 'city': city_name}, index=[0])
merged_df = pd.merge(pd.merge(location_df, weather_df, left_index=True, right_index=True), temp_df, left_index=True, right_index=True)
return merged_df
# Function to transform the data
def transform_data(df):
df = df.drop(columns=['id', 'icon']) # Drop unnecessary columns
cols = ['temp', 'feels_like', 'temp_min', 'temp_max']
df[cols] = df[cols] - 273 # Convert from Kelvin to Celsius
return df.to_dict(orient='records')
# Optional callback for delivery status
def delivery_report(err, msg):
if err:
print(f'Delivery failed: {err}')
else:
print(f'Delivered to {msg.topic()}[{msg.partition()}]')
# Continuous streaming loop
while True:
data = extract_data()
transformed = transform_data(data)
for record in transformed:
producer.produce(topic, value=json.dumps(record), callback=delivery_report)
producer.poll(0)
time.sleep(600) # Wait for 10 minutes before fetching again
Explanation:
We load API keys from .env for security.Extract weather data, clean it, and convert temperatures and send each data point to Kafka every 10 minutes since our api sends the data every 10 mins
b)consumer.py — Consuming from Kafka and Pushing to MongoDB
from confluent_kafka import Consumer, KafkaError, KafkaException
from dotenv import load_dotenv
import os, json, time
from pymongo.mongo_client import MongoClient
from pymongo.server_api import ServerApi
# Load MongoDB connection string from .env
load_dotenv()
uri = os.getenv('DB_STRING')
# Connect to MongoDB
client = MongoClient(uri, server_api=ServerApi('1'))
db = client.weather_data # You can name this whatever you want
collection = db.reports
# Kafka Consumer configuration
config = {
'bootstrap.servers': 'localhost:9092',
'group.id': 'weather-consumer-group',
'auto.offset.reset': 'earliest'
}
consumer = Consumer(config)
topic = 'weather_topic'
consumer.subscribe([topic])
# Function to insert data into MongoDB
def load_data(records):
collection.insert_many(records)
# Consume messages loop
while True:
try:
msg = consumer.poll(1.0)
if msg is None:
print("No message received.")
elif msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
print("End of partition reached.")
else:
raise KafkaException(msg.error())
else:
message_data = json.loads(msg.value().decode('utf-8'))
load_data([message_data])
print(f"Data stored: {message_data}")
time.sleep(600) # Optional: throttle for real-time feel
except Exception as e:
print(f"Error: {str(e)}")
break
Explanation:
Consumes data from Kafka topic.Parses JSON messages and pushes them to MongoDB. load_data() is where insertion happens.
5. Tying Everything Together
a) Start Kafka Server
Navigate to your Kafka directory and run:
$ nohup kafka/bin/kafka-server-start.sh kafka/config/server.properties
b) Run Python Files
In the same server session or another, run:
$ nohup python3 consumer.py
$ nohup python3 producer.py
The nohup command allows the scripts to keep running even after you disconnect from SSH.
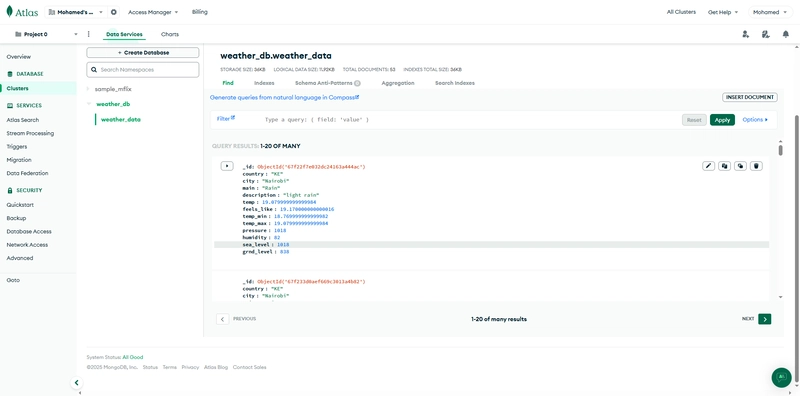
Final Step: Check MongoDB
Head over to MongoDB Atlas > Clusters > Browse Collections, and you should start seeing weather data coming in every 10 minutes.
Conclusion
You’ve now built a working real-time data pipeline that:
*Streams weather data from OpenWeather API
*Publishes it to Kafka
*Consumes it and stores it in MongoDB
This setup is highly scalable and gives you fault tolerance via Kafka. You can build on this with more processing or dashboard visualizations later.