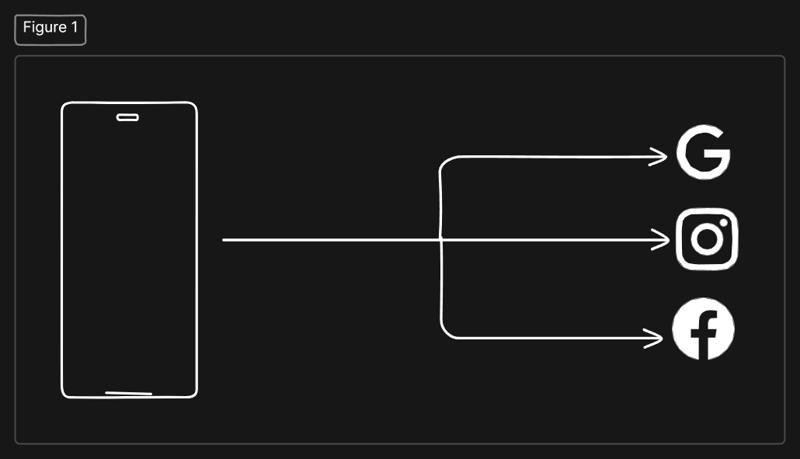
.jpg)
%20Abstract%20Background%20112024%20SOURCE%20Amazon.jpg)






















































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)

































































































































![From drop-out to software architect with Jason Lengstorf [Podcast #167]](https://cdn.hashnode.com/res/hashnode/image/upload/v1743796461357/f3d19cd7-e6f5-4d7c-8bfc-eb974bc8da68.png?#)







































































































.png?#)





.jpg?#)































_Christophe_Coat_Alamy.jpg?#)

















































































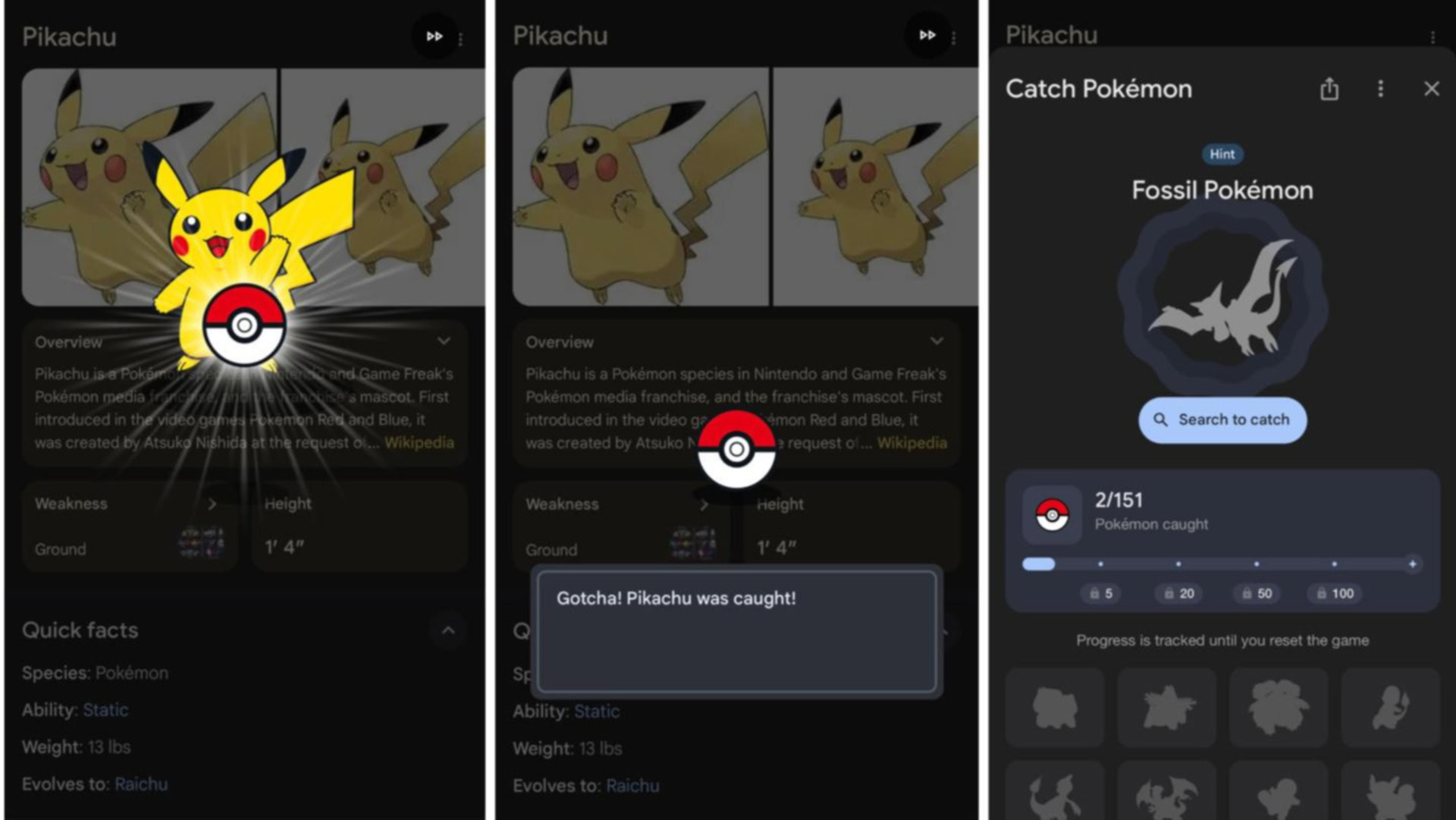




















![Rapidus in Talks With Apple as It Accelerates Toward 2nm Chip Production [Report]](https://www.iclarified.com/images/news/96937/96937/96937-640.jpg)
































































































































Solving pandas pickle compatibility issues across different versions
Have you ever encountered the frustrating error when trying to read a pickle file created with a different version of pandas? You're not alone. This common issue affects many data scientists and developers working in collaborative environments or maintaining long-term projects. Let's explore how to solve this problem effectively. When you save a pandas DataFrame using to_pickle(), the serialization process is specific to the pandas version used. This means that pickle files created with newer versions of pandas may not be readable by older versions, leading to compatibility errors. Solution Options Option 1: Use the Same Version (Simple but Limited) The most straightforward solution is to ensure you're using the same version (or a later one) of pandas as the one used to create the pickle file. However, this isn't always practical, especially in team environments or when working with legacy systems. Option 2: Convert to CSV (Universal but Limited) For simple dataframes without complex objects, converting to CSV offers excellent compatibility: # With newer pandas version import pandas as pd data = pd.read_pickle('path/to/file.pkl') data.to_csv('path/to/file.csv', index=False) # With older pandas version data = pd.read_csv('path/to/file.csv') This approach works well for most tabular data but has limitations when dealing with complex data types. Option 3: Use HDF Format (Best for Complex Data) For dataframes containing objects like lists and arrays in individual cells, the HDF format provides better compatibility: Step 1: Load data with the newest version of Python and pandas import pandas as pd import pickle data = pd.read_pickle('path/to/file.pkl') Step 2: Save as HDF with protocol 4 pickle.HIGHEST_PROTOCOL = 4 data.to_hdf('output/folder/path/to/file.hdf', 'df') You may need to install the required dependency: pip install tables

Have you ever encountered the frustrating error when trying to read a pickle file created with a different version of pandas? You're not alone. This common issue affects many data scientists and developers working in collaborative environments or maintaining long-term projects. Let's explore how to solve this problem effectively.
When you save a pandas DataFrame using to_pickle(), the serialization process is specific to the pandas version used. This means that pickle files created with newer versions of pandas may not be readable by older versions, leading to compatibility errors.
Solution Options
Option 1: Use the Same Version (Simple but Limited)
The most straightforward solution is to ensure you're using the same version (or a later one) of pandas as the one used to create the pickle file. However, this isn't always practical, especially in team environments or when working with legacy systems.
Option 2: Convert to CSV (Universal but Limited)
For simple dataframes without complex objects, converting to CSV offers excellent compatibility:
# With newer pandas version
import pandas as pd
data = pd.read_pickle('path/to/file.pkl')
data.to_csv('path/to/file.csv', index=False)
# With older pandas version
data = pd.read_csv('path/to/file.csv')
This approach works well for most tabular data but has limitations when dealing with complex data types.
Option 3: Use HDF Format (Best for Complex Data)
For dataframes containing objects like lists and arrays in individual cells, the HDF format provides better compatibility:
Step 1: Load data with the newest version of Python and pandas
import pandas as pd
import pickle
data = pd.read_pickle('path/to/file.pkl')
Step 2: Save as HDF with protocol 4
pickle.HIGHEST_PROTOCOL = 4
data.to_hdf('output/folder/path/to/file.hdf', 'df')
You may need to install the required dependency:
pip install tables