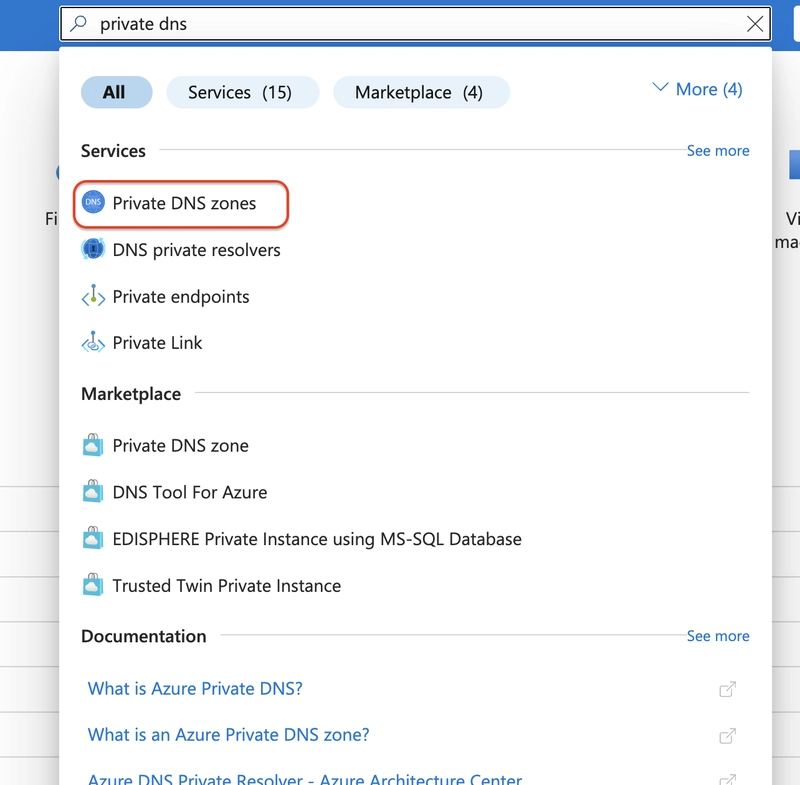























































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)
































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)







































































































(1).jpg?#)
































_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
















































































































![New Apple iPad mini 7 On Sale for $399! [Lowest Price Ever]](https://www.iclarified.com/images/news/96096/96096/96096-640.jpg)
![Apple to Split iPhone Launches Across Fall and Spring in Major Shakeup [Report]](https://www.iclarified.com/images/news/97211/97211/97211-640.jpg)
![Apple to Move Camera to Top Left, Hide Face ID Under Display in iPhone 18 Pro Redesign [Report]](https://www.iclarified.com/images/news/97212/97212/97212-640.jpg)
![Apple Developing Battery Case for iPhone 17 Air Amid Battery Life Concerns [Report]](https://www.iclarified.com/images/news/97208/97208/97208-640.jpg)

























































































Real-World Blue-Green Deployment: 10 Lessons I Wish I Knew Earlier
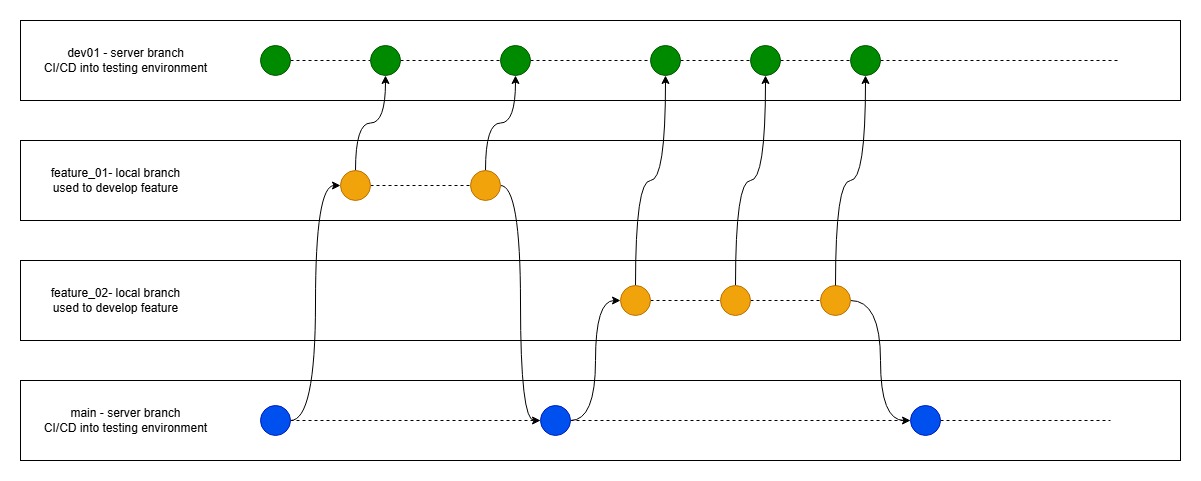
I started experimenting with blue-green deployment months ago—published a couple of slide decks (one, two), read the docs, thought I had it mostly figured out. Spoiler: I didn’t. Now, after rolling it out in real-world systems (and dealing with the chaos that followed), here are the 10 most valuable lessons I’ve learned—what worked, what broke, and how we made it through. 1. “Identical” environments? Easier said than done Even with Terraform and Ansible, subtle differences sneak in—especially after a few hotfixes. We had OpenSSL versions drift apart, and legacy clients couldn’t connect after a switch. Version control your infra and regularly diff live configs. 2. Your database is your weakest link Schema changes are where blue-green deployments get risky fast. One rollout crashed due to a new JSONB column in green that blue’s ORM couldn’t handle. Solution? Versioned migrations + compatibility shims. Still a nightmare. 3. Never trust DNS during cutover In one case, DNS took 83 minutes to propagate to parts of Southeast Asia. Use Layer 7 load balancers with weighted routing and health checks. Or better yet: service mesh with traffic splitting. 4. Cost doubles—then multiplies Our first month of dual-environment rollouts doubled compute costs. And that didn’t include logging, monitoring, or duplicated third-party services. Start small and isolate only the mission-critical pieces. 5. Monitoring tools don’t always like your setup Our Prometheus stack broke when environments flipped. We had to inject headers and rewrite queries to track metrics separately. Logging pipelines also needed refactoring to separate blue/green data streams. 6. Partial rollouts = safer experiments Blue-green doesn’t have to mean 100% traffic switch. We started with 5% rollout for a new cache layer and saw a 22% latency drop—without affecting the core user base. Combine BGD with A/B and canary logic. 7. Automate more than you think you need to The more manual steps, the more risk. Use GitOps tools like Argo CD to reconcile environments. Run automated smoke tests against green before switching. Avoid “eyeball checks” at all costs. 8. You need strong observability before your first switch It’s not just about uptime—what if metrics spike, but logs stay clean? Or users complain, but health checks pass? Have visibility into both platforms, and alert by environment tag. 9. Don’t blue-green everything It’s perfect for APIs, microservices, stateless apps. But for big monoliths or batch jobs? Rolling updates or feature flags are often better. Pick your battles. 10. Preparation beats panic Every incident we avoided was thanks to pre-switch testing, infra standardization, or rollback readiness. The ones we didn’t? Missed detail, bad assumptions, rushed decisions. Final thought Blue-green deployment is a powerful tool—but only if you respect its complexity. It’s not just a method, it’s a mindset shift. Plan more, automate more, and start small.

I started experimenting with blue-green deployment months ago—published a couple of slide decks (one, two), read the docs, thought I had it mostly figured out.
Spoiler: I didn’t.
Now, after rolling it out in real-world systems (and dealing with the chaos that followed), here are the 10 most valuable lessons I’ve learned—what worked, what broke, and how we made it through.
1. “Identical” environments? Easier said than done
Even with Terraform and Ansible, subtle differences sneak in—especially after a few hotfixes. We had OpenSSL versions drift apart, and legacy clients couldn’t connect after a switch. Version control your infra and regularly diff live configs.
2. Your database is your weakest link
Schema changes are where blue-green deployments get risky fast. One rollout crashed due to a new JSONB column in green that blue’s ORM couldn’t handle. Solution? Versioned migrations + compatibility shims. Still a nightmare.
3. Never trust DNS during cutover
In one case, DNS took 83 minutes to propagate to parts of Southeast Asia. Use Layer 7 load balancers with weighted routing and health checks. Or better yet: service mesh with traffic splitting.
4. Cost doubles—then multiplies
Our first month of dual-environment rollouts doubled compute costs. And that didn’t include logging, monitoring, or duplicated third-party services. Start small and isolate only the mission-critical pieces.
5. Monitoring tools don’t always like your setup
Our Prometheus stack broke when environments flipped. We had to inject headers and rewrite queries to track metrics separately. Logging pipelines also needed refactoring to separate blue/green data streams.
6. Partial rollouts = safer experiments
Blue-green doesn’t have to mean 100% traffic switch. We started with 5% rollout for a new cache layer and saw a 22% latency drop—without affecting the core user base. Combine BGD with A/B and canary logic.
7. Automate more than you think you need to
The more manual steps, the more risk. Use GitOps tools like Argo CD to reconcile environments. Run automated smoke tests against green before switching. Avoid “eyeball checks” at all costs.
8. You need strong observability before your first switch
It’s not just about uptime—what if metrics spike, but logs stay clean? Or users complain, but health checks pass? Have visibility into both platforms, and alert by environment tag.
9. Don’t blue-green everything
It’s perfect for APIs, microservices, stateless apps. But for big monoliths or batch jobs? Rolling updates or feature flags are often better. Pick your battles.
10. Preparation beats panic
Every incident we avoided was thanks to pre-switch testing, infra standardization, or rollback readiness. The ones we didn’t? Missed detail, bad assumptions, rushed decisions.
Final thought
Blue-green deployment is a powerful tool—but only if you respect its complexity. It’s not just a method, it’s a mindset shift. Plan more, automate more, and start small.