![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)
































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)





































































































(1).jpg?#)
































_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)









































































































![Apple to Split iPhone Launches Across Fall and Spring in Major Shakeup [Report]](https://www.iclarified.com/images/news/97211/97211/97211-640.jpg)
![Apple to Move Camera to Top Left, Hide Face ID Under Display in iPhone 18 Pro Redesign [Report]](https://www.iclarified.com/images/news/97212/97212/97212-640.jpg)
![Apple Developing Battery Case for iPhone 17 Air Amid Battery Life Concerns [Report]](https://www.iclarified.com/images/news/97208/97208/97208-640.jpg)
![AirPods 4 On Sale for $99 [Lowest Price Ever]](https://www.iclarified.com/images/news/97206/97206/97206-640.jpg)






























![[Updated] Samsung’s 65-inch 4K Smart TV Just Crashed to $299 — That’s Cheaper Than an iPad](https://www.androidheadlines.com/wp-content/uploads/2025/05/samsung-du7200.jpg)






























































Proof or Bluff? Why Today's AI Still Fails the Math Olympiad Test
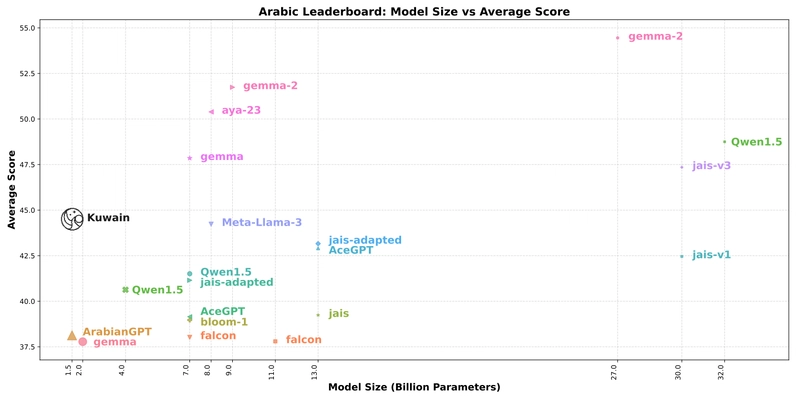
Can today’s most advanced AI models really solve math like a human genius? Recent math benchmarks have shown impressive results on problems like those in the AIME or HMMT competitions. But these tasks mostly need final answers — not full, rigorous proofs. That’s where the new study, “Proof or Bluff?” from ETH Zurich and INSAIT, steps in. Researchers challenged top-tier language models — including Gemini-2.5-PRO, Claude 3.7, and Grok-3 — with the 2025 USAMO (USA Mathematical Olympiad): a competition famous for its demand for deep thinking and bulletproof logic. The Verdict? AI Still Flops on Hard Math Even the best model, Gemini-2.5-PRO, scored only 10.1 out of 42 — that’s just about 24% accuracy. All others scored less than 5%. That’s not even close to human Olympiad-level performance. Why They Failed Human judges (all former IMO finalists) identified four common failure patterns: Flawed logic: Skipping reasoning steps or drawing false conclusions. Wrong assumptions: Using unsupported ideas to bridge gaps. Low creativity: Sticking to one (wrong) strategy across multiple runs. Hallucinations: Making up citations or boxing trivial answers due to training biases. Even more ironic — many models claimed they had solved the problem, even when their logic was clearly broken. The Hidden Bias of Optimization Training tricks like reinforcement learning (RLHF/GRPO) push models to "box the final answer," even when a box isn’t appropriate. Worse, models like QWQ and Gemini fabricated academic-sounding theorems that don’t exist — just to sound convincing. Automated Grading? Not Yet. The team also tried using LLMs to grade each other — a cool idea, but the results were inflated by up to 20x. Machines couldn’t distinguish a shallow bluff from real insight. What This Means for AI + Math This paper sends a clear signal: today’s LLMs aren’t ready for formal math reasoning that demands proof, creativity, and logical precision. We’re seeing polished performance in shallow tasks, but in-depth reasoning remains out of reach. The Road Ahead To build truly trustworthy AI mathematicians, we need a next-gen leap — beyond pattern matching and into genuine, provable reasoning. Whether through better alignment, curriculum learning, or symbolic tools — the future of math + AI is still wide open. Resources: matharena github TL;DR: AI models can bluff their way through simple math, but when it comes to real, Olympiad-level proofs — they break down. We’re not at the age of automated mathematicians yet — but this research is a solid step toward that future.

Can today’s most advanced AI models really solve math like a human genius? Recent math benchmarks have shown impressive results on problems like those in the AIME or HMMT competitions. But these tasks mostly need final answers — not full, rigorous proofs.
That’s where the new study, “Proof or Bluff?” from ETH Zurich and INSAIT, steps in. Researchers challenged top-tier language models — including Gemini-2.5-PRO, Claude 3.7, and Grok-3 — with the 2025 USAMO (USA Mathematical Olympiad): a competition famous for its demand for deep thinking and bulletproof logic.
The Verdict? AI Still Flops on Hard Math
Even the best model, Gemini-2.5-PRO, scored only 10.1 out of 42 — that’s just about 24% accuracy. All others scored less than 5%. That’s not even close to human Olympiad-level performance.
Why They Failed
Human judges (all former IMO finalists) identified four common failure patterns:
Flawed logic: Skipping reasoning steps or drawing false conclusions.
Wrong assumptions: Using unsupported ideas to bridge gaps.
Low creativity: Sticking to one (wrong) strategy across multiple runs.
Hallucinations: Making up citations or boxing trivial answers due to training biases.
Even more ironic — many models claimed they had solved the problem, even when their logic was clearly broken.
The Hidden Bias of Optimization
Training tricks like reinforcement learning (RLHF/GRPO) push models to "box the final answer," even when a box isn’t appropriate. Worse, models like QWQ and Gemini fabricated academic-sounding theorems that don’t exist — just to sound convincing.
Automated Grading? Not Yet.
The team also tried using LLMs to grade each other — a cool idea, but the results were inflated by up to 20x. Machines couldn’t distinguish a shallow bluff from real insight.
What This Means for AI + Math
This paper sends a clear signal: today’s LLMs aren’t ready for formal math reasoning that demands proof, creativity, and logical precision. We’re seeing polished performance in shallow tasks, but in-depth reasoning remains out of reach.
The Road Ahead
To build truly trustworthy AI mathematicians, we need a next-gen leap — beyond pattern matching and into genuine, provable reasoning. Whether through better alignment, curriculum learning, or symbolic tools — the future of math + AI is still wide open.
Resources:
TL;DR: AI models can bluff their way through simple math, but when it comes to real, Olympiad-level proofs — they break down. We’re not at the age of automated mathematicians yet — but this research is a solid step toward that future.