










































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)


















































































































































































































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)











![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)






























































































































OpenAI GPT 4.1 is HUGE for developers, Nvidia's newest reasoning model, Google AI for dolphins, and more
Hello AI Enthusiasts! Welcome to the fifteenth edition of "This Week in AI Engineering"! OpenAI introduced the GPT-4.1 family with million-token context and breakthrough performance gains across three tiers, and NVIDIA released Llama-3.1-Nemotron-Ultra-253B achieving elite reasoning with reduced infrastructure requirements. Plus, we'll cover Google's groundbreaking AI for dolphins, DeepCoder's open-source achievement matching commercial models, and also some must-know tools to make developing AI agents and apps easier. OpenAI's GPT-4.1 Family is Made For Developers OpenAI has released its new GPT-4.1 model family, introducing three API-exclusive models: GPT-4.1, GPT-4.1 Mini, and GPT-4.1 Nano. All support a massive 1 million token context window while delivering significant performance improvements over GPT-4o in coding, instruction following, and long-context comprehension. The Practical Impact of Million-Token Context Full Codebase Processing: The 1M token context window enables processing 8 complete copies of the React codebase in a single query, eliminating the need to break large projects into artificially small chunks Cross-File Understanding: Developers can now reference dependencies across thousands of files, allowing AI to grasp complex project architectures and make changes that respect global code structure Document Analysis Revolution: Multi-document legal reviews that previously required manual correlation can now be processed as a unified context, improving analysis accuracy by 17% Response Time Management: First token generation takes ~15 seconds with 128K context and ~1 minute with 1M context for GPT-4.1, while Nano delivers sub-5-second responses even with large contexts SWE-bench 54.6%: GPT is finally Good for Coding Majority Success Rate: At 54.6% completion (vs. GPT-4o's 33.2%), GPT-4.1 successfully solves the majority of real-world software engineering tasks, better than any other model yet. Error Reduction: Extraneous code edits dropped from 9% to just 2%, meaning developers spend significantly less time correcting AI-generated code First-Attempt Acceptance: Success rates for code passing initial review increased by 60%, fundamentally changing the economics of AI-assisted development Frontend Quality Leap: Human evaluators preferred GPT-4.1's web interfaces 80% of the time, indicating mastery of both functional and aesthetic aspects of development This tiered approach allows organizations to deploy appropriate AI capabilities across their entire stack, using premium models only where genuinely required while leveraging more cost-effective options for routine tasks. What GPT-4.1 Means for the AI Model Ecosystem Google's Context Advantage Neutralized: Gemini 2.5 Pro's primary technical edge was its 1M token context—GPT-4.1 now matches this while outperforming it on coding benchmarks and offering more favorable pricing ($2.00/$8.00 vs $1.25/$10.00 for output) Claude's Extended Thinking Trade-off: Claude 3.7 Sonnet's reasoning capabilities now face a direct challenge from GPT-4.1's improved instruction following, while its 200K context limitation becomes a significant disadvantage for document-intensive workflows Cost-Prohibitive Models Under Pressure: o3-mini's premium pricing ($15.00/$75.00) now requires justifying a 7-15x cost differential against GPT-4.1, likely pushing it toward specialized domains like scientific reasoning where it maintains clear advantages Mini-Model Market Expansion: GPT-4.1 Mini outperforming GPT-4o at 83% lower cost creates opportunities for AI integration in previously cost-sensitive sectors like education, small businesses, and public services These competitive dynamics will likely accelerate specialized model development as general capabilities become commoditized, with top-tier providers focusing on domain-specific excellence rather than broad capability improvements. NVIDIA’s Elite Reasoning Model NVIDIA has released Llama-3.1-Nemotron-Ultra-253B-v1, a highly optimized model derived from Meta's Llama-3.1-405B-Instruct that achieves superior reasoning performance while requiring significantly fewer computational resources. The model establishes new benchmarks across several evaluation tasks while running on just a single 8xH100 node. Breaking the Size-Performance Trade-off for Enterprise AI Parameter Efficiency: 253B parameters (38% reduction from Meta's 405B version) while maintaining or improving performance Infrastructure Requirements: Runs on a single 8xH100 node instead of the multi-rack setups needed for 400B+ models Deployment Implications: Brings frontier model capabilities within reach of mid-sized AI labs and corporate research departments Cost Reduction: Significantly lower compute and energy costs for training and inference compared to larger models For companies deploying AI systems, this represents a crucial breakthrough—elite reasoning without the multi-million-dollar infrastructu
Hello AI Enthusiasts!
Welcome to the fifteenth edition of "This Week in AI Engineering"!
OpenAI introduced the GPT-4.1 family with million-token context and breakthrough performance gains across three tiers, and NVIDIA released Llama-3.1-Nemotron-Ultra-253B achieving elite reasoning with reduced infrastructure requirements.
Plus, we'll cover Google's groundbreaking AI for dolphins, DeepCoder's open-source achievement matching commercial models, and also some must-know tools to make developing AI agents and apps easier.
OpenAI's GPT-4.1 Family is Made For Developers
OpenAI has released its new GPT-4.1 model family, introducing three API-exclusive models: GPT-4.1, GPT-4.1 Mini, and GPT-4.1 Nano. All support a massive 1 million token context window while delivering significant performance improvements over GPT-4o in coding, instruction following, and long-context comprehension.
The Practical Impact of Million-Token Context
- Full Codebase Processing: The 1M token context window enables processing 8 complete copies of the React codebase in a single query, eliminating the need to break large projects into artificially small chunks
- Cross-File Understanding: Developers can now reference dependencies across thousands of files, allowing AI to grasp complex project architectures and make changes that respect global code structure
- Document Analysis Revolution: Multi-document legal reviews that previously required manual correlation can now be processed as a unified context, improving analysis accuracy by 17%
- Response Time Management: First token generation takes ~15 seconds with 128K context and ~1 minute with 1M context for GPT-4.1, while Nano delivers sub-5-second responses even with large contexts
SWE-bench 54.6%: GPT is finally Good for Coding
- Majority Success Rate: At 54.6% completion (vs. GPT-4o's 33.2%), GPT-4.1 successfully solves the majority of real-world software engineering tasks, better than any other model yet.
- Error Reduction: Extraneous code edits dropped from 9% to just 2%, meaning developers spend significantly less time correcting AI-generated code
- First-Attempt Acceptance: Success rates for code passing initial review increased by 60%, fundamentally changing the economics of AI-assisted development
- Frontend Quality Leap: Human evaluators preferred GPT-4.1's web interfaces 80% of the time, indicating mastery of both functional and aesthetic aspects of development
This tiered approach allows organizations to deploy appropriate AI capabilities across their entire stack, using premium models only where genuinely required while leveraging more cost-effective options for routine tasks.
What GPT-4.1 Means for the AI Model Ecosystem
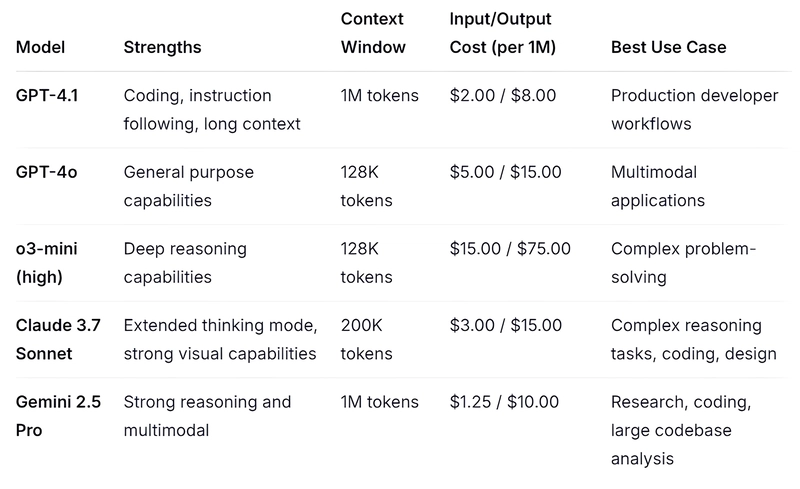
- Google's Context Advantage Neutralized: Gemini 2.5 Pro's primary technical edge was its 1M token context—GPT-4.1 now matches this while outperforming it on coding benchmarks and offering more favorable pricing ($2.00/$8.00 vs $1.25/$10.00 for output)
- Claude's Extended Thinking Trade-off: Claude 3.7 Sonnet's reasoning capabilities now face a direct challenge from GPT-4.1's improved instruction following, while its 200K context limitation becomes a significant disadvantage for document-intensive workflows
- Cost-Prohibitive Models Under Pressure: o3-mini's premium pricing ($15.00/$75.00) now requires justifying a 7-15x cost differential against GPT-4.1, likely pushing it toward specialized domains like scientific reasoning where it maintains clear advantages
- Mini-Model Market Expansion: GPT-4.1 Mini outperforming GPT-4o at 83% lower cost creates opportunities for AI integration in previously cost-sensitive sectors like education, small businesses, and public services
These competitive dynamics will likely accelerate specialized model development as general capabilities become commoditized, with top-tier providers focusing on domain-specific excellence rather than broad capability improvements.
NVIDIA’s Elite Reasoning Model
NVIDIA has released Llama-3.1-Nemotron-Ultra-253B-v1, a highly optimized model derived from Meta's Llama-3.1-405B-Instruct that achieves superior reasoning performance while requiring significantly fewer computational resources. The model establishes new benchmarks across several evaluation tasks while running on just a single 8xH100 node.
Breaking the Size-Performance Trade-off for Enterprise AI
- Parameter Efficiency: 253B parameters (38% reduction from Meta's 405B version) while maintaining or improving performance
- Infrastructure Requirements: Runs on a single 8xH100 node instead of the multi-rack setups needed for 400B+ models
- Deployment Implications: Brings frontier model capabilities within reach of mid-sized AI labs and corporate research departments
- Cost Reduction: Significantly lower compute and energy costs for training and inference compared to larger models
For companies deploying AI systems, this represents a crucial breakthrough—elite reasoning without the multi-million-dollar infrastructure investments previously required. Research labs and AI startups can now work with top-tier models without securing massive funding rounds just for compute resources.
What These Benchmark Numbers Mean in Practice
- 76.0% GPQA, 97.0% MATH500, 72.5% AIME, 66.3% LiveCodeBench: PhD-level reasoning across scientific, mathematical, and coding domains
These capabilities enable practical applications in drug discovery, material science research, quantitative finance, complex engineering, and autonomous software development—domains where reasoning quality directly impacts business outcomes.
Training Methodology: Multi-Phase Approach to Preserve Knowledge
- Initial Distillation: 65 billion tokens of knowledge distillation from the reference model maintains core capabilities while reducing size
- Continual Pre-training: Additional 88 billion tokens to recover performance potentially lost during compression
- Multi-phase Post-training: Specialized supervised fine-tuning for Math, Code, Reasoning, Chat, and Tool Calling creates versatility across domains
- Reinforcement Learning: Multiple RL stages using Group Relative Policy Optimization (GRPO) enhances reasoning capabilities through feedback-based improvement
This sophisticated training approach allows NVIDIA to achieve the seemingly contradictory goals of reducing model size while improving performance, offering valuable insights for organizations developing their own optimized models.
Dual-Mode Operation: Flexibility for Different Use Cases
The model includes a unique capability controlled via system prompt, allowing users to toggle between:
- Standard Inference ("reasoning off"): Faster responses for routine tasks where computational efficiency matters more than reasoning depth
- Enhanced Reasoning ("reasoning on"): Step-by-step thinking process for complex problems where solution quality outweighs speed considerations
NVIDIA recommends using a temperature of 0.6 with Top-P of 0.95 for reasoning mode and greedy decoding for standard inference, providing operational flexibility for different business requirements without maintaining separate systems.
Google’s AI for Dolphins
Google has announced DolphinGemma, a specialized AI model designed to analyze and potentially decode dolphin vocalizations. Developed in collaboration with the Wild Dolphin Project (WDP) and Georgia Tech researchers, this 400M parameter model represents a significant advancement in interspecies communication research.
Technical Architecture
- Model Foundation: Built on Google's Gemma architecture, optimized for audio pattern recognition
- Input Processing: Uses SoundStream tokenizer to efficiently represent complex dolphin audio signals
- Parameter Size: ~400M parameters, deliberately sized to run directly on Pixel phones in field conditions
- Training Dataset: Trained on WDP's extensive acoustic database of wild Atlantic spotted dolphins
- Operation Mode: Audio-in, audio-out model that predicts likely subsequent sounds in dolphin communication sequences
Research Applications
- Pattern Detection: Identifies recurring sound patterns, clusters, and reliable sequences to uncover hidden structures in natural dolphin communication
- Field Deployment: Implemented on Pixel phones within the CHAT (Cetacean Hearing Augmentation Telemetry) system for real-time analysis
- Two-Way Interaction: Works alongside synthetic whistles associated with specific objects to establish a shared vocabulary
- Device Integration: Next-generation system (summer 2025) will use Pixel 9 phones to integrate speaker/microphone functions with simultaneous deep learning and template matching
Performance Features
- Real-Time Analysis: Processes high-fidelity dolphin sounds in noisy ocean environments
- Vocalization Prediction: Anticipates potential mimics earlier in vocalization sequences for faster researcher responses
- Hardware Efficiency: Dramatically reduces the need for custom hardware, improving system maintainability while lowering power consumption
- Adaptability: Designed to be fine-tuned for different cetacean species beyond the Atlantic spotted dolphins
For marine biologists, this technology transforms decades of passive observation into active communication possibilities. The 40-year dataset from the Wild Dolphin Project now serves as both training material and a contextual foundation for interpreting new vocalizations, potentially revealing communication structures previously impossible to identify through human analysis alone.
DeepCoder Matches O3-mini Performance in Code Generation
Agentica and Together AI have released DeepCoder-14B-Preview, a fully open-source code reasoning model that achieves performance on par with OpenAI's o3-mini despite having only 14B parameters. This breakthrough demonstrates that smaller, open models can match commercial systems through advanced reinforcement learning techniques.
Technical Implementation
- Base Model: Fine-tuned from DeepSeek-R1-Distilled-Qwen-14B using distributed reinforcement learning
- Training Scale: 24K verifiable coding problems over 2.5 weeks on 32 H100 GPUs
- Context Window: Trained at 32K context but generalizes effectively to 64K without additional training
- System Optimization: Introduces verl-pipe with 2x acceleration in end-to-end RL training
Performance Metrics
- LiveCodeBench: 60.6% Pass@1 accuracy, matching o3-mini's 60.9% and exceeding o1's 59.5%
- Codeforces Rating: Achieves 1936 (95.3 percentile), comparable to o3-mini (1918) and approaching o1 (1991)
- HumanEval+: 92.6% success rate, identical to o3-mini and significantly above o1-preview
- Mathematical Reasoning: 73.8% on AIME 2024, showing strong cross-domain transfer despite being trained solely on coding
Technical Innovations
- GRPO+ Algorithm: Enhanced Group Relative Policy Optimization featuring No Entropy Loss, No KL Loss, Overlong Filtering, and Clip High mechanisms
- Iterative Context Lengthening: Enables the model to learn effective reasoning at shorter contexts before generalizing to longer ones
- One-Off Pipelining: Novel system optimization that fully masks trainer and reward computation times
- Rigorous Data Filtering: Implemented programmatic verification, test filtering, and cross-dataset deduplication
The researchers have open-sourced the entire training pipeline, including dataset, code, training logs, and system optimizations. This comprehensive release allows the community to reproduce their results and further accelerate progress in open-source AI development. The accompanying smaller model, DeepCoder-1.5 B-Preview, demonstrates the scalability of their approach, achieving a 25.1% LCB score that represents an 8.2% improvement over its base model.
Tools & Releases YOU Should Know About
AI coding assistant that understands entire codebases. Automates code generation, refactoring and debugging with contextual awareness of both high-level architecture and implementation details. Accelerates prototyping and reduces technical debt while preserving developer control. Ideal for teams seeking productivity gains without compromising quality.
Open-source semantic code search tool enabling natural language queries instead of exact keyword matching. Creates a vector database of your codebase to find functionality, not just syntax. Runs locally with no code sent to external servers. Perfect for navigating large, unfamiliar codebases where grep falls short.
Automated unit test generator for Java applications. Analyzes classes, determines test inputs, mocks dependencies, and verifies outputs. Integrates with Maven/Gradle and maintains tests as code evolves. Especially valuable for legacy codebases lacking coverage or during major refactoring. Dramatically improves test coverage with minimal developer effort.
Minimalist AI coding assistant in ~200 lines of JavaScript. Terminal-based tool with local file awareness and project context. Connects to LLM APIs without the bloat of larger applications. Perfect for developers who want customizable, transparent AI assistance rather than black-box solutions.
And that wraps up this issue of "This Week in AI Engineering", brought to you by jam.dev— your flight recorder for AI apps! Non-deterministic AI issues are hard to repro, unless you have Jam! Instant replay the session, prompt + logs to debug ⚡️
Thank you for tuning in! Be sure to share this newsletter with your fellow AI enthusiasts and follow for more weekly updates.
Until next time, happy building!

