











































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)

















































































































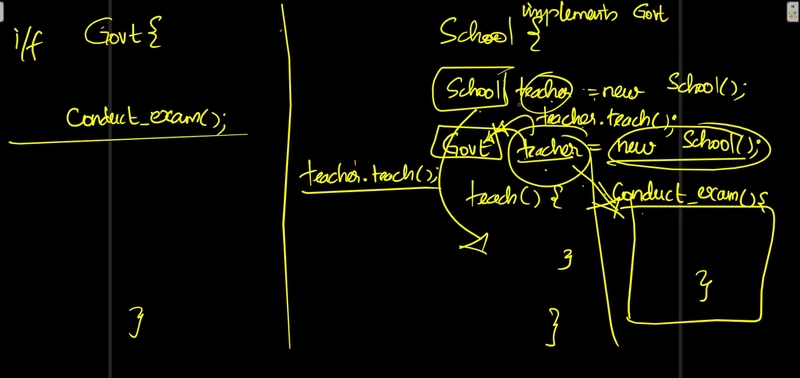



































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)



























































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)
































































































































OSD700 - RAG Integration: Stage 1 & 2
Table of Contents Preface Introduction Stage 1 PR Expansion Preface In the previous post, I shared with you that I successfully implemented RAG prototype locally and described the steps I've taken. Moreover, we decided to try to make this feature work in the ChatCraft.org which means that the implementation is going to differ a little bit, since unlike my prototype we will be working in a browser-like environment. Therefore, it requires a clear plan that will help land the feature step-by-step. Introduction After the prototype presentation, I filed an issue with the proposal plan. Within the next couple of hours, we had a discussion regarding the plan, and eventually professor has adjusted it and approved. That's how the final proposal issue looks like: RAG on DuckDB Implementation Based on Prototype #868 mulla028 posted on Mar 29, 2025 Description Recently, we have implemented a prototype of RAG on DuckDB, and it proves that implementation is doable for the ChatCraft it's time to start working on it! The implementation will take several steps, lets call them stages. Since we already have the set up of DuckDB using duckdb-wasm, the file loader, and format to text extractors, we are skipping some of the steps(stages). Therefore here are the steps we need to take in order successfully implement it: Proposed Implementation Stages Stage 1: Create Two New Tables in IndexedDB Embeddings Table, with foreign key to a file Chunks Table, with foreign key to a file Stage 2: Implement Chunking Logic Proper Chunking with overlap (cf. https://platform.openai.com/docs/assistants/tools/file-search#customizing-file-search-settings) Proper Chunking Storage in IndexedDB Stage 3: Implement Embeddings Generation Allow using a cloud-based model or local (transformers.js or tensorflow.js) Stage 4: Vector Search Use DuckDB's extension Called VSS Load Embeddings, Chunks, etc. into DuckDB Apply HNSW Indexing to Increase Speed of the Search ( HNSW Indexing Provided by VSS extension) Stage 5: LLM Integration Modify Prompt Construction to Include Retrieved Context Implement Source Attribution in Responses Adjust Token Management to Account For Context Stage 6: Query Processing Implement Embedding Generation for User Queries Use the Same Embedding Model as Documents for Consistency(text-embedding-3-small) @humphd, @tarasglek please take a look at the proposed implementation stages, and approve them. Let me know if I am missing something :) View on GitHub As you can see, it takes 6 stages. Could be more, but we already have these features: Automatic Text Extraction of Uploaded File to IndexedDB Chunking Logic (Thanks to one of the contributors) Stage 1 In the first stage, I had to add the chunking and embeddings tables to the file table in IndexedDB. During the implementation, we have decided to have the embeddings inside the chunks, therefore each chunk has its vector embeddings. It didn't require much time, just a couple of lines of code... PR Expansion I realized that the PR is too small to be landed, and I have to expand it a little more and implement the chunking logic for each file. Which means that I am implementing Stages 1 and 2 in a single PR. After a couple of hours, I pushed a bunch of commits: Created FileChunk[] type Implemented chunking logic Added condition that files with the size of >3MB are getting automatically chunked during the import The rest was a cleanup. However, one of the contributors pointed at the function that he has already implemented for the chunking. It helped me a lot, since I had to remake my chunking logic and it had some problems... Eventually, the PR was approved and merged, you may take a look right here: [RAG] Stages 1 & 2: New Columns and Chunking #870 mulla028 posted on Apr 01, 2025 Stage 1 for #868 Description This is the stage 1 of RAG implementation. Since we've decided to use vector search ChatCraft requires two new tables, as it is stated in the Proposed Implementation. However, @humphd suggested to add two new columns to the ChatCraftFileTable - chunks and embeddings. These are optional columns, chunks that will contain chunked text ( Planned to be implemented during the stage 2 - next.) Therefore, embeddings - will contain generated by model and based on chunks vector embeddings ( The implementation is planned to be done at stage - 3 .) Small Concern I totally understand that these columns are optional, but do we need to add them to data schema as the new fields in the indexedDB like this? I don't see that we have any other optional column, so I decided not to include them to PR.
Table of Contents
- Preface
- Introduction
- Stage 1
- PR Expansion
Preface
In the previous post, I shared with you that I successfully implemented RAG prototype locally and described the steps I've taken. Moreover, we decided to try to make this feature work in the ChatCraft.org which means that the implementation is going to differ a little bit, since unlike my prototype we will be working in a browser-like environment. Therefore, it requires a clear plan that will help land the feature step-by-step.
Introduction
After the prototype presentation, I filed an issue with the proposal plan. Within the next couple of hours, we had a discussion regarding the plan, and eventually professor has adjusted it and approved.
That's how the final proposal issue looks like:
 RAG on DuckDB Implementation Based on Prototype
#868
RAG on DuckDB Implementation Based on Prototype
#868
Description
Recently, we have implemented a prototype of RAG on DuckDB, and it proves that implementation is doable for the ChatCraft it's time to start working on it!
The implementation will take several steps, lets call them stages. Since we already have the set up of DuckDB using duckdb-wasm, the file loader, and format to text extractors, we are skipping some of the steps(stages). Therefore here are the steps we need to take in order successfully implement it:
Proposed Implementation Stages
-
Stage 1: Create Two New Tables in IndexedDB
- Embeddings Table, with foreign key to a file
- Chunks Table, with foreign key to a file
-
Stage 2: Implement Chunking Logic
- Proper Chunking with overlap (cf. https://platform.openai.com/docs/assistants/tools/file-search#customizing-file-search-settings)
- Proper Chunking Storage in IndexedDB
-
Stage 3: Implement Embeddings Generation
- Allow using a cloud-based model or local (transformers.js or tensorflow.js)
-
Stage 4: Vector Search
- Use DuckDB's extension Called VSS
- Load Embeddings, Chunks, etc. into DuckDB
- Apply HNSW Indexing to Increase Speed of the Search (
HNSWIndexing Provided by VSS extension)
-
Stage 5: LLM Integration
- Modify Prompt Construction to Include Retrieved Context
- Implement Source Attribution in Responses
- Adjust Token Management to Account For Context
-
Stage 6: Query Processing
- Implement Embedding Generation for User Queries
- Use the Same Embedding Model as Documents for Consistency(
text-embedding-3-small)
@humphd, @tarasglek please take a look at the proposed implementation stages, and approve them. Let me know if I am missing something :)
As you can see, it takes 6 stages. Could be more, but we already have these features:
- Automatic Text Extraction of Uploaded File to IndexedDB
- Chunking Logic (Thanks to one of the contributors)
Stage 1
In the first stage, I had to add the chunking and embeddings tables to the file table in IndexedDB. During the implementation, we have decided to have the embeddings inside the chunks, therefore each chunk has its vector embeddings. It didn't require much time, just a couple of lines of code...
PR Expansion
I realized that the PR is too small to be landed, and I have to expand it a little more and implement the chunking logic for each file. Which means that I am implementing Stages 1 and 2 in a single PR.
After a couple of hours, I pushed a bunch of commits:
- Created
FileChunk[]type - Implemented chunking logic
- Added condition that files with the size of >3MB are getting automatically chunked during the import
The rest was a cleanup. However, one of the contributors pointed at the function that he has already implemented for the chunking. It helped me a lot, since I had to remake my chunking logic and it had some problems...
Eventually, the PR was approved and merged, you may take a look right here:
[RAG] Stages 1 & 2: New Columns and Chunking
#870
Stage 1 for #868
Description
This is the stage 1 of RAG implementation. Since we've decided to use vector search ChatCraft requires two new tables, as it is stated in the Proposed Implementation. However, @humphd suggested to add two new columns to the ChatCraftFileTable - chunks and embeddings. These are optional columns, chunks that will contain chunked text ( Planned to be implemented during the stage 2 - next.) Therefore, embeddings - will contain generated by model and based on chunks vector embeddings ( The implementation is planned to be done at stage - 3 .)
Small Concern
I totally understand that these columns are optional, but do we need to add them to data schema as the new fields in the indexedDB like this? I don't see that we have any other optional column, so I decided not to include them to PR.
this.version(13).stores({
files: "id, name, type, size, text, created, chunks, embeddings",
});
UPD: Decided to implement chunking here as well
Now it means that stages 1,2 are done, and we have to move forward to the stage 3 - embeddings generation, it will be interesting :)


