





































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)











































































































































































































































































_Muhammad_R._Fakhrurrozi_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_NicoElNino_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)











































































































![Apple Releases iOS 18.5 Beta 4 and iPadOS 18.5 Beta 4 [Download]](https://www.iclarified.com/images/news/97145/97145/97145-640.jpg)
![Apple Seeds watchOS 11.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97147/97147/97147-640.jpg)
![Apple Seeds visionOS 2.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97150/97150/97150-640.jpg)
![Apple Seeds tvOS 18.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97153/97153/97153-640.jpg)






























































































O teorema CAP não é a ferramenta ideal para você! (E pra ninguém)
Contexto Esse texto não tem como propósito apresentar o teorema CAP de maneira aprofundada, e sim promover reflexões e um olhar crítico usando artigos, teoremas e textos feitos levando em consideração a aplicação do teorema no mundo real. Boa parte deste texto na real é baseada no paper A Critique of the CAP Theorem - de Martin Kleppmann, autor também do livro DDIA. Se este artigo te interessar, recomendo a leitura do material original, mais denso e aprofundado em aspectos científicos. Para textos que explicam o conceito do CAP, recomendo o incrível artigo do Matheus Fidelis Conceito Original O CAP é um teorema apresentado para classificar sistemas de banco de dados distribuídos, e foi apresentado originalmente na forma "Consistência, DIsponibilidade (Availability) ou Tolerância à Partições, escolha dois." - Significando que você pode ter CA (Consistência e Disponibilidade), CP (Consistência e Tolerância à Partições) ou AP (Disponibilidade e Tolerância à Partições), mas nunca os três. Esse conceito normalmente é representado por meio de um diagrama de Venn Debates futuros concluíram que essa formulação não é das melhores, principalmente porquê é difícil distinguir entre CA e CP. Se seu sistema não é resistente à partições de rede, como você pode chamar ele de altamente disponível? Mas, se ele é resistente, ele não pode ser classificado como disponível? Ambiguidades Hoje em dia, muitos autores preferem formular o CAP da seguinte forma: Se não existe partição de rede, um sistema pode ser Consistente e Disponível. Se existe partição de rede, você tem que escolher entre disponibilidade (AP) ou consistência (CP). Alguns autores definem um sistema CP como um sistema onde a maior parte dos nós de um lado de uma partição irão continuar operando normalmente, e um sistema CA como um sistema que pode falhar catastróficamente quando ocorrer uma partição de rede. Essas definições não são necessariamente "concordadas", é contraintuitivo chamar um sistema de "disponível", de maneira categórica, se ele pode falhar de maneira catastrófica sob uma partição de rede, enquanto um sistema que continua funcionando é chamado de "indisponível". Outro ponto apresentado pelo autor é que chamar um sistema de maneira categórica de "Disponível" ou "Indisponível" não necessariamente tem muito sentido, visto que disponibilidade é algo a ser observado, uma métrica, e nenhum sistema será 100% disponível ou indisponível. Desta forma, alguns textos 2 defendem que você não deve deixar a resistência à partições de rede de lado, portanto o CA torna-se inviável em termos realistas. Tradeoff entre latência e consistência O Ponto do teorema CAP são os tradeoffs que você deve levar em consideração ao escrever e utilizar software. Martin Kleppmann abrange isso de outra forma, em minha opinião, mais simples de entender que o modelo original e com tradeoffs mais claros! O teorema CAP é simplista demais e mal compreendido demais para ser útil na caracterização de sistemas. Portanto, peço que retiremos todas as referências ao teorema CAP, paremos de falar sobre ele e o deixemos de lado. Em vez disso, deveríamos usar uma terminologia mais precisa para raciocinar sobre nossas compensações. - Martin Kleppman, em seu blog, no post # Por favor, pare de chamar os bancos de dados de CP ou AP Se há um delay (latência) de rede, você deve esperar pelo menos pelo tempo do delay d para realizar alguma operação (escrita ou leitura) em um software, esse conceito faz sentido porquê seria impossível escrever e ler antes da rede em si, a menos que você tenha memória compartilhada (atualizada só na leitura, ou só na escrita) ou a menos que tenha uma baixa consistência (casual consistency). Um novo Modelo: Sensível à Latência Um ponto importante é considerar que o CAP (Como teorema) não leva em conta fatores importantes ao escrever e avaliar software para o mundo real. Se você responde uma chamada em 10 horas por conta de um problema no seu banco de dados, pode classificá-lo como disponível? Quais são os SLA's que devemos levar em consideração para discutir essas terminologias? Aqui, o foco principal do modelo proposto por Kleppmann é a latência. Aplicada ao mundo real. To find a replacement for CAP with a latency-centric viewpoint we need to examine how operation latency is affected by network latency at different levels of consistency. Na hora de classificarmos modelos, usaremos uma notação similar ao Big(O), só que ao invés de ser o tamanho do Input, descrevemos a latência de uma operação como uma função de uma latência de rede. A notação big O para latência operacional ignora fatores constantes, como o número de round-trips que um algorítmo realiza, mas captura a essência do que precisamos saber para construir sistemas que podem tolerar falhas de rede: O que acontece quando a latência da rede piora drásticamente Um exemplo apresentado no artigo, mostra, diferentes níveis de consistência e
Contexto
Esse texto não tem como propósito apresentar o teorema CAP de maneira aprofundada, e sim promover reflexões e um olhar crítico usando artigos, teoremas e textos feitos levando em consideração a aplicação do teorema no mundo real.
Boa parte deste texto na real é baseada no paper A Critique of the CAP Theorem - de Martin Kleppmann, autor também do livro DDIA. Se este artigo te interessar, recomendo a leitura do material original, mais denso e aprofundado em aspectos científicos.
Para textos que explicam o conceito do CAP, recomendo o incrível artigo do Matheus Fidelis
Conceito Original
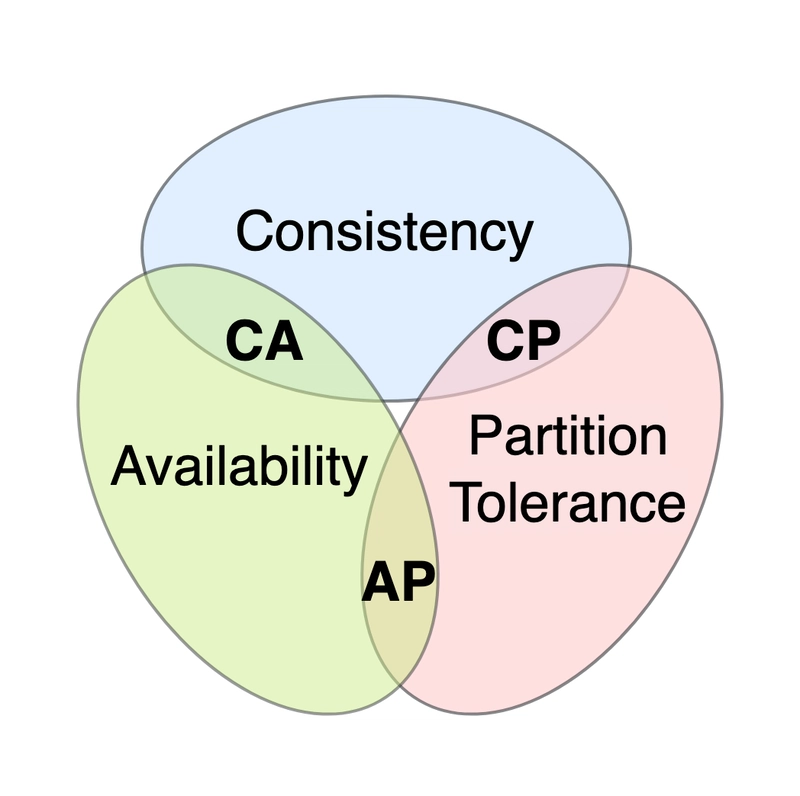
O CAP é um teorema apresentado para classificar sistemas de banco de dados distribuídos, e foi apresentado originalmente na forma "Consistência, DIsponibilidade (Availability) ou Tolerância à Partições, escolha dois." - Significando que você pode ter CA (Consistência e Disponibilidade), CP (Consistência e Tolerância à Partições) ou AP (Disponibilidade e Tolerância à Partições), mas nunca os três. Esse conceito normalmente é representado por meio de um diagrama de Venn
Debates futuros concluíram que essa formulação não é das melhores, principalmente porquê é difícil distinguir entre CA e CP. Se seu sistema não é resistente à partições de rede, como você pode chamar ele de altamente disponível? Mas, se ele é resistente, ele não pode ser classificado como disponível?
Ambiguidades
Hoje em dia, muitos autores preferem formular o CAP da seguinte forma: Se não existe partição de rede, um sistema pode ser Consistente e Disponível. Se existe partição de rede, você tem que escolher entre disponibilidade (AP) ou consistência (CP).
Alguns autores definem um sistema CP como um sistema onde a maior parte dos nós de um lado de uma partição irão continuar operando normalmente, e um sistema CA como um sistema que pode falhar catastróficamente quando ocorrer uma partição de rede. Essas definições não são necessariamente "concordadas", é contraintuitivo chamar um sistema de "disponível", de maneira categórica, se ele pode falhar de maneira catastrófica sob uma partição de rede, enquanto um sistema que continua funcionando é chamado de "indisponível".
Outro ponto apresentado pelo autor é que chamar um sistema de maneira categórica de "Disponível" ou "Indisponível" não necessariamente tem muito sentido, visto que disponibilidade é algo a ser observado, uma métrica, e nenhum sistema será 100% disponível ou indisponível.
Desta forma, alguns textos 2 defendem que você não deve deixar a resistência à partições de rede de lado, portanto o CA torna-se inviável em termos realistas.
Tradeoff entre latência e consistência
O Ponto do teorema CAP são os tradeoffs que você deve levar em consideração ao escrever e utilizar software. Martin Kleppmann abrange isso de outra forma, em minha opinião, mais simples de entender que o modelo original e com tradeoffs mais claros!
O teorema CAP é simplista demais e mal compreendido demais para ser útil na caracterização de sistemas. Portanto, peço que retiremos todas as referências ao teorema CAP, paremos de falar sobre ele e o deixemos de lado. Em vez disso, deveríamos usar uma terminologia mais precisa para raciocinar sobre nossas compensações. - Martin Kleppman, em seu blog, no post # Por favor, pare de chamar os bancos de dados de CP ou AP
Se há um delay (latência) de rede, você deve esperar pelo menos pelo tempo do delay d para realizar alguma operação (escrita ou leitura) em um software, esse conceito faz sentido porquê seria impossível escrever e ler antes da rede em si, a menos que você tenha memória compartilhada (atualizada só na leitura, ou só na escrita) ou a menos que tenha uma baixa consistência (casual consistency).
Um novo Modelo: Sensível à Latência
Um ponto importante é considerar que o CAP (Como teorema) não leva em conta fatores importantes ao escrever e avaliar software para o mundo real. Se você responde uma chamada em 10 horas por conta de um problema no seu banco de dados, pode classificá-lo como disponível? Quais são os SLA's que devemos levar em consideração para discutir essas terminologias?
Aqui, o foco principal do modelo proposto por Kleppmann é a latência. Aplicada ao mundo real.
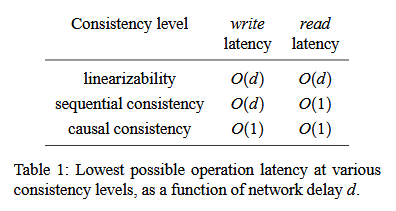
To find a replacement for CAP with a latency-centric viewpoint we need to examine how operation latency is affected by network latency at different levels of consistency.
Na hora de classificarmos modelos, usaremos uma notação similar ao Big(O), só que ao invés de ser o tamanho do Input, descrevemos a latência de uma operação como uma função de uma latência de rede.
A notação big O para latência operacional ignora fatores constantes, como o número de round-trips que um algorítmo realiza, mas captura a essência do que precisamos saber para construir sistemas que podem tolerar falhas de rede: O que acontece quando a latência da rede piora drásticamente
Um exemplo apresentado no artigo, mostra, diferentes níveis de consistência e como cada um deles é afetado por uma latência (d)
Note que isso não significa que você precisa, para todo banco de dados que for buscar, procurar qual estratégia de consistência e replicação entre bancos é utilizada (embora é isso que eu ache), mas deve, ao menos, saber como ele é afetado pela latência, escolhendo a chave correta para cada parafuso. Apesar disso, recomendo a leitura do paper - Replicated Data Consistency Explained Through Baseball
Outro ponto importante aqui com o modelo sensível à latência é pararmos de classificarmos sistemas como CP ou AP de maneira simplista 4:
- Dentro de um software, você pode ter diferentes operações com características diferentes de consistência.*
- Dentro de um software, definir consistência pode ser complicado
- O Apache Zookeper, utiliza, para lidar com replicação, o algorítmo de Consenso, que opta por consistência em prol da disponibilidade.
- Apesar disso, o Zookeeper faz com que cada cliente se conecte em um nó, e cada leitura bata nesse nó, portanto, mesmo que hajam escritas mais atualizadas em outro nó, você não as verá
- Podem existir sistemas que não se enquadram nas características definidas no CAP, e fazem total sentido para seu caso de uso. Portanto, o modelo sensível à latência é mais um - entenda as possibilidades do seu sistema e pense por você mesmo. O ponto é que chamar um sistema de não consistente por não ser linearizável não é o caminho
Extra:
A partir de agora, entramos mais no lado científico da coisa.
Incongruências do CAP
O Teorema foi formalizado por Gilbert e Lynch [25, 26].
O primeiro teorema do cap é:
It is impossible in the asynchronous network model to implement a read/write data object that guarantees the following properties:
• Availability
• Atomic consistency
in all fair executions (including those in which messages are lost
O problema é que a formalização de Disponibilidade por parte dos autores é:
"For a distributed system to be continuously available, every request received by a non-failing node in the system must result in a response"
Portanto, se todos os nós de um sistema distribuídos estão com problema, ele está automaticamente Disponível pela definição do CAP. Essas e outras incongruências convergiram para a criação de um novo modelo, fácil de se entender e mais correto, mas que abrangesse as mesmas ideias do CAP.
- Existem bem mais listadas no artigo original.
Terminologia Proposta
Availability
Is an empirical metric, not a property of an algorithm. It is defined as the percentage of successful requests (returning a non-error response within a predefined latency bound) over some period of system operation.
Delay-sensitive
describes algorithms or operations that need to wait for network communication to complete, i.e. which have latency proportional to network delay. The opposite is delay-independent. Systems must specify the nature of the sensitivity (e.g. an operation may be sensitive to intra-datacenter delay but independent of inter-datacenter delay). A fully delay-independent system supports disconnected (offline) operation.
Network faults
encompass packet loss (both transient and long-lasting) and unusually large packet delay. Network partitions are just one particular type of network fault; in most cases, systems should plan for all kinds of network fault, and not only partitions. As long as lost packets or failed requests are retried, they can be modeled as large network delay.
Fault tolerance
is used in preference to high availability or partition tolerance. The maximum fault that can be tolerated must be specified (e.g. “the algorithm can tolerate up to a minority of replicas crashing or disconnecting”), and the description must also state what happens if more faults occur than the system can tolerate (e.g. all requests return an error, or a consistency property is violated).
Consistency
refers to a spectrum of different consistency models (including linearizability and causal consistency), not one particular consistency model. When a particular consistency model such as linearizability is intended, it is referred to by its usual name. The term strong consistency is vague, and may refer to linearizability, sequential consistency or one-copy serializability.
Bibliografia
[0] - https://fidelissauro.dev/teorema-cap/
[1] - Kleppman, Martin. A Critique of the CAP Theorem. https://arxiv.org/pdf/1509.05393
[2] - https://codahale.com/you-cant-sacrifice-partition-tolerance/
[3] - Terry, Doug. Replicated Data Consistency Explained Through Baseball https://www.microsoft.com/en-us/research/wp-content/uploads/2011/10/ConsistencyAndBaseballReport.pdf
[4] - https://martin.kleppmann.com/2015/05/11/please-stop-calling-databases-cp-or-ap.html


