







































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)







































































































































































































![Blue Archive tier list [April 2025]](https://media.pocketgamer.com/artwork/na-33404-1636469504/blue-archive-screenshot-2.jpg?#)


































.png?#)





































.webp?#)




















































































![[Update: Optional] Google rolling out auto-restart security feature to Android](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-2.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)
















![Apple to Split Enterprise and Western Europe Roles as VP Exits [Report]](https://www.iclarified.com/images/news/97032/97032/97032-640.jpg)
![Nanoleaf Announces New Pegboard Desk Dock With Dual-Sided Lighting [Video]](https://www.iclarified.com/images/news/97030/97030/97030-640.jpg)




































![Security Database Used by Apple Goes Independent After Funding Cut [Updated]](https://images.macrumors.com/t/FWFeAmxnHKf7vkk_MCBh9TcNMVg=/1600x/article-new/2023/05/bug-security-vulnerability-issue-fix-larry.jpg)



















































































My Learnings About Etcd
This is my first ever technical blog, so do correct if I am wrong, not so technically strong right now, just sharing my learnings. Etcd is a distributed key-value store, somewhat like Redis, but it operates quite differently under the hood (more on this later). It's implemented in Golang and is fully open-source. While etcd can be paired with many systems, its most prominent use case is in Kubernetes, where it's a critical component of the control plane. How is Etcd used in Kubernetes? If you're familiar with Kubernetes architecture, you know it consists of control plane components and worker nodes. The control plane is responsible for managing the overall cluster state - including scheduling, maintaining desired state, responding to cluster events, and more. But where does Kubernetes store all of its metadata? Things like: Pod definitions Deployment states Configuration data Secrets and ConfigMaps Cluster state That's where etcd comes into the picture. All cluster data is stored in etcd in a key-value format. Whenever the kube-api-server needs to fetch or persist cluster state, it communicates directly with etcd. Etcd can either be: Embedded as part of the control plane (commonly deployed alongside kube-apiserver) Or hosted as a separate, external cluster, often in high-availability production environments. Is Etcd Distributed? Yes, etcd is a distributed system designed for fault-tolerance and high availability. You can run multiple instances (etcd nodes or members) in a cluster. To maintain consistency across nodes, etcd uses the RAFT consensus algorithm. A Quick Look at the RAFT Algorithm The RAFT consensus algorithm ensures that the etcd cluster agrees on the current state, even in the presence of failures. Here's how it works: Among all nodes, one is elected as the leader. The leader handles all client requests (writes) and replicates changes to follower nodes. If the leader goes down, a new leader is automatically elected from the followers. This ensures strong consistency, meaning all clients see the same data regardless of which node they connect to. ScyllaDB, a distributed NoSQL database also uses the RAFT algorithm for leader elections. Refer link. Storage Engine and Data Model - How Etcd Stores Data Just like many traditional databases use a storage engine to handle how data is written to disk, etcd does the same. For example: MySQL uses InnoDB SQLite has its own built-in storage engine MongoDB uses WiredTiger Each storage engine follows a different data structure design - like B+ Trees (great for read-heavy operations) or LSM Trees (optimized for write-heavy workloads). So what does etcd use? Etcd uses a storage engine called BoltDB (specifically, a fork called bbolt). BoltDB is a B+ Tree-based key-value store that persists data to disk and provides excellent support for consistent and predictable reads, which aligns perfectly with etcd's goal of being a strongly-consistent store for configuration data. You can read more details here. How Etcd Stores Data (and How It's Different from Redis) Etcd stores data using a B+ Tree–based storage engine called bbolt (a fork of BoltDB), which writes data persistently to disk. Unlike Redis, which primarily keeps data in memory for lightning-fast access (and optionally persists it), etcd is designed for strong consistency and durability, even across restarts or crashes. It uses a multi-version concurrency control (MVCC) model, where every update creates a new revision instead of modifying data in-place. This allows etcd to support features like watching changes, accessing historical versions, and time-travel queries - all while keeping disk usage optimized using compaction. This makes etcd an ideal choice for systems like Kubernetes where data integrity and change tracking are more critical than raw speed. You can read more about the differences here. So, if it stores all the history, won't the disk/memory gets full? Etcd periodically performs compaction, which cleans up old revisions and reduces disk usage while keeping recent history intact. That's all I've learned about Etcd so far. It might not be perfect or super in-depth, but I feel like I now have a decent understanding of how things work under the hood. I'm still exploring and learning about it - and this is just the beginning.

This is my first ever technical blog, so do correct if I am wrong, not so technically strong right now, just sharing my learnings.
Etcd is a distributed key-value store, somewhat like Redis, but it operates quite differently under the hood (more on this later).
It's implemented in Golang and is fully open-source.
While etcd can be paired with many systems, its most prominent use case is in Kubernetes, where it's a critical component of the control plane.
How is Etcd used in Kubernetes?
If you're familiar with Kubernetes architecture, you know it consists of control plane components and worker nodes. The control plane is responsible for managing the overall cluster state - including scheduling, maintaining desired state, responding to cluster events, and more.
But where does Kubernetes store all of its metadata? Things like:
- Pod definitions
- Deployment states
- Configuration data
- Secrets and ConfigMaps
- Cluster state
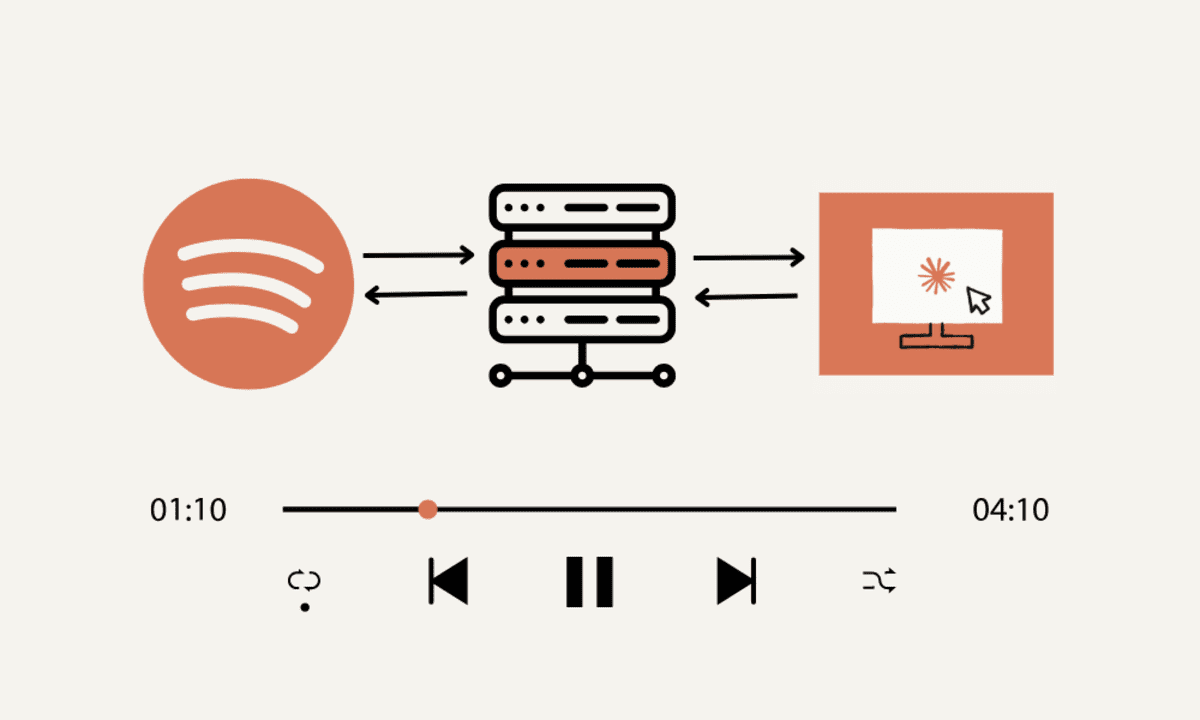
That's where etcd comes into the picture.
All cluster data is stored in etcd in a key-value format. Whenever the kube-api-server needs to fetch or persist cluster state, it communicates directly with etcd.
Etcd can either be:
- Embedded as part of the control plane (commonly deployed alongside kube-apiserver)
- Or hosted as a separate, external cluster, often in high-availability production environments.
Is Etcd Distributed?
Yes, etcd is a distributed system designed for fault-tolerance and high availability. You can run multiple instances (etcd nodes or members) in a cluster.
To maintain consistency across nodes, etcd uses the RAFT consensus algorithm.
A Quick Look at the RAFT Algorithm
The RAFT consensus algorithm ensures that the etcd cluster agrees on the current state, even in the presence of failures.
Here's how it works:
- Among all nodes, one is elected as the leader.
- The leader handles all client requests (writes) and replicates changes to follower nodes.
- If the leader goes down, a new leader is automatically elected from the followers.
This ensures strong consistency, meaning all clients see the same data regardless of which node they connect to.
ScyllaDB, a distributed NoSQL database also uses the RAFT algorithm for leader elections. Refer link.
Storage Engine and Data Model - How Etcd Stores Data
Just like many traditional databases use a storage engine to handle how data is written to disk, etcd does the same.
For example:
- MySQL uses InnoDB
- SQLite has its own built-in storage engine
- MongoDB uses WiredTiger
Each storage engine follows a different data structure design - like B+ Trees (great for read-heavy operations) or LSM Trees (optimized for write-heavy workloads).
So what does etcd use?
Etcd uses a storage engine called BoltDB (specifically, a fork called bbolt).
BoltDB is a B+ Tree-based key-value store that persists data to disk and provides excellent support for consistent and predictable reads, which aligns perfectly with etcd's goal of being a strongly-consistent store for configuration data.
You can read more details here.
How Etcd Stores Data (and How It's Different from Redis)
Etcd stores data using a B+ Tree–based storage engine called bbolt (a fork of BoltDB), which writes data persistently to disk. Unlike Redis, which primarily keeps data in memory for lightning-fast access (and optionally persists it), etcd is designed for strong consistency and durability, even across restarts or crashes.
It uses a multi-version concurrency control (MVCC) model, where every update creates a new revision instead of modifying data in-place.
This allows etcd to support features like watching changes, accessing historical versions, and time-travel queries - all while keeping disk usage optimized using compaction.
This makes etcd an ideal choice for systems like Kubernetes where data integrity and change tracking are more critical than raw speed.
You can read more about the differences here.
So, if it stores all the history, won't the disk/memory gets full?
Etcd periodically performs compaction, which cleans up old revisions and reduces disk usage while keeping recent history intact.
That's all I've learned about Etcd so far. It might not be perfect or super in-depth, but I feel like I now have a decent understanding of how things work under the hood. I'm still exploring and learning about it - and this is just the beginning.


