


















































%20Abstract%20Background%20112024%20SOURCE%20Amazon.jpg)
























































































































![[The AI Show Episode 142]: ChatGPT’s New Image Generator, Studio Ghibli Craze and Backlash, Gemini 2.5, OpenAI Academy, 4o Updates, Vibe Marketing & xAI Acquires X](https://www.marketingaiinstitute.com/hubfs/ep%20142%20cover.png)
























































































































































































































































-Nintendo-Switch-2-–-Overview-trailer-00-00-10.png?width=1920&height=1920&fit=bounds&quality=80&format=jpg&auto=webp#)






















_Anna_Berkut_Alamy.jpg?#)










































































































![YouTube Announces New Creation Tools for Shorts [Video]](https://www.iclarified.com/images/news/96923/96923/96923-640.jpg)































































![[Weekly funding roundup March 29-April 4] Steady-state VC inflow pre-empts Trump tariff impact](https://images.yourstory.com/cs/2/220356402d6d11e9aa979329348d4c3e/WeeklyFundingRoundupNewLogo1-1739546168054.jpg)
























































Microsoft Is the Best (But Slow), IBM Beats Most of OpenAI: What I Found Testing 50+ LLMs
Large Language Models (LLMs) are everywhere now – GPT-4, Claude 3, Gemini, LLaMA, Mistral, and more. Everyone talks about which is "the best," but surprisingly, real side-by-side performance comparisons are rare. So, I built one myself. I tested over 50 LLMs – both cloud-based and local – on my own hardware, using real-world developer tasks. And the results? Shocking. Microsoft's Phi-4 was the most accurate model overall (yes, a local model!). IBM’s Granite models outperformed many of OpenAI’s most hyped offerings. Speed vs. accuracy is a serious tradeoff – and the best choice depends on your workflow. Here's a breakdown of how I tested, what I found, and how you can pick the right model.
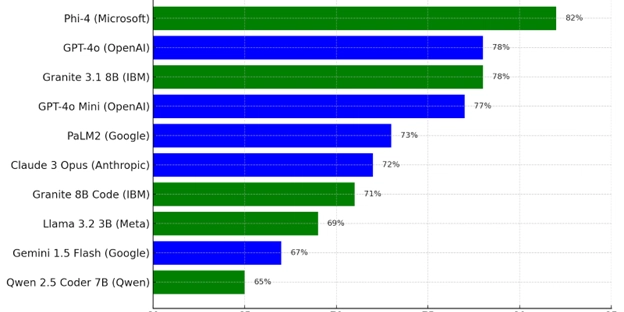
Large Language Models (LLMs) are everywhere now – GPT-4, Claude 3, Gemini, LLaMA, Mistral, and more. Everyone talks about which is "the best," but surprisingly, real side-by-side performance comparisons are rare. So, I built one myself.
I tested over 50 LLMs – both cloud-based and local – on my own hardware, using real-world developer tasks. And the results? Shocking.
- Microsoft's Phi-4 was the most accurate model overall (yes, a local model!).
- IBM’s Granite models outperformed many of OpenAI’s most hyped offerings.
- Speed vs. accuracy is a serious tradeoff – and the best choice depends on your workflow.
Here's a breakdown of how I tested, what I found, and how you can pick the right model.




