



























![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)







































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)








































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





























































































![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)








![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)





























































































































Mavors: Multi-Granularity Video Beats MLLM Limits! See How.
This is a Plain English Papers summary of a research paper called Mavors: Multi-Granularity Video Beats MLLM Limits! See How.. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. The Challenge of Long Video Understanding in MLLMs Video understanding presents a fundamental challenge for multimodal large language models (MLLMs): how to balance computational efficiency with preserving crucial spatiotemporal information. Current approaches make significant compromises - sparse sampling loses temporal details, dense sampling with low resolution sacrifices spatial clarity, and token compression methods miss subtle interactions between objects. Comparison of different video processing approaches showing how Mavors balances resolution and frame count requirements. Note that red words indicate incorrect details while green words show correct details. The Mavors system introduces a novel framework that addresses these limitations through multi-granularity video representation. Mavors directly encodes raw video content through two key components: An Intra-chunk Vision Encoder (IVE) that preserves high-resolution spatial features via 3D convolutions and Vision Transformers An Inter-chunk Feature Aggregator (IFA) that establishes temporal coherence across chunks using transformer-based dependency modeling with chunk-level rotary position encodings This architecture enables Mavors to maintain both spatial fidelity and temporal continuity while keeping computational demands manageable. Additionally, the framework unifies image and video understanding by treating images as single-frame videos through sub-image decomposition. Current Approaches to Video Processing in MLLMs MLLM Architecture Evolution Contemporary MLLMs employ two main architectural strategies for visual processing: Cross-attention approach: Maintains frozen model parameters while establishing dynamic visual-language interactions through attention mechanisms Pretrained encoder approach: Processes visual content through pretrained encoders (CLIP, SigLIP) before concatenating image tokens with text embeddings for unified language model processing The second approach readily extends to video analysis through sequential frame processing, with many architectural innovations for temporal modeling emerging in recent research. The State of Video Understanding in MLLMs Existing MLLMs show varying capabilities in temporal comprehension across different video durations. While current systems handle minute-scale video analysis effectively, models targeting hour-long sequences face fundamental challenges. Researchers have pursued two primary optimization directions: Context window expansion for large language models - theoretically enabling long-sequence processing but suffering from impractical computational overhead Token compression via spatial-temporal feature distillation - achieving high compression rates but discarding subtle details, resulting in performance degradation on standard benchmarks Unlike these approaches, Mavors directly processes raw videos to maintain spatial and temporal details with acceptable computational costs. The Mavors Architecture: Multi-granularity Video Understanding Why Dense Sampling and High Resolution Matter Preliminary experiments compared two popular video MLLMs (Qwen2.5-VL-7B and Oryx-1.5-7B) on two representative benchmarks (Video-MME and DREAM-1K) to understand the impact of frame numbers and resolution. Impact of the number of frames (720P) on Video-MME and Dream1K performance. Impact of the resolution of frames (64 frames) on Video-MME and Dream1K performance. The results revealed that: Performance increases significantly when increasing the number of frames, demonstrating the necessity of dense sampling Higher resolution is critical for tasks like video captioning but less important for multiple-choice question answering These findings confirmed that real-world video understanding tasks rely on fine-grained spatiotemporal contexts, necessitating dense sampling of high-resolution frames while maintaining computational efficiency. Mavors: A Multi-granularity Approach to Video Encoding Mavors enhances video understanding capability by introducing an efficient video encoding strategy based on dense sampling with high resolution. The architecture of Mavors showing how it processes video content and images. The system employs a video encoder that directly processes pixel information from video chunks, converting them into latent representations. Mavors follows an auto-regressive architecture to generate textual responses based on given textual instructions. The processing pipeline consists of: Preprocessing raw videos or images Using an intra-chunk vision encoder and inter-chunk feature aggregator to comprehend videos while preserving spatial and temporal details Passing temporal
This is a Plain English Papers summary of a research paper called Mavors: Multi-Granularity Video Beats MLLM Limits! See How.. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
The Challenge of Long Video Understanding in MLLMs
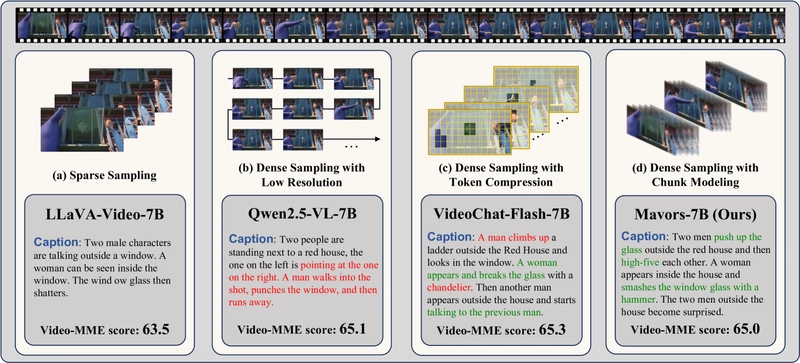
Video understanding presents a fundamental challenge for multimodal large language models (MLLMs): how to balance computational efficiency with preserving crucial spatiotemporal information. Current approaches make significant compromises - sparse sampling loses temporal details, dense sampling with low resolution sacrifices spatial clarity, and token compression methods miss subtle interactions between objects.
Comparison of different video processing approaches showing how Mavors balances resolution and frame count requirements. Note that red words indicate incorrect details while green words show correct details.
The Mavors system introduces a novel framework that addresses these limitations through multi-granularity video representation. Mavors directly encodes raw video content through two key components:
- An Intra-chunk Vision Encoder (IVE) that preserves high-resolution spatial features via 3D convolutions and Vision Transformers
- An Inter-chunk Feature Aggregator (IFA) that establishes temporal coherence across chunks using transformer-based dependency modeling with chunk-level rotary position encodings
This architecture enables Mavors to maintain both spatial fidelity and temporal continuity while keeping computational demands manageable. Additionally, the framework unifies image and video understanding by treating images as single-frame videos through sub-image decomposition.
Current Approaches to Video Processing in MLLMs
MLLM Architecture Evolution
Contemporary MLLMs employ two main architectural strategies for visual processing:
- Cross-attention approach: Maintains frozen model parameters while establishing dynamic visual-language interactions through attention mechanisms
- Pretrained encoder approach: Processes visual content through pretrained encoders (CLIP, SigLIP) before concatenating image tokens with text embeddings for unified language model processing
The second approach readily extends to video analysis through sequential frame processing, with many architectural innovations for temporal modeling emerging in recent research.
The State of Video Understanding in MLLMs
Existing MLLMs show varying capabilities in temporal comprehension across different video durations. While current systems handle minute-scale video analysis effectively, models targeting hour-long sequences face fundamental challenges.
Researchers have pursued two primary optimization directions:
- Context window expansion for large language models - theoretically enabling long-sequence processing but suffering from impractical computational overhead
- Token compression via spatial-temporal feature distillation - achieving high compression rates but discarding subtle details, resulting in performance degradation on standard benchmarks
Unlike these approaches, Mavors directly processes raw videos to maintain spatial and temporal details with acceptable computational costs.
The Mavors Architecture: Multi-granularity Video Understanding
Why Dense Sampling and High Resolution Matter
Preliminary experiments compared two popular video MLLMs (Qwen2.5-VL-7B and Oryx-1.5-7B) on two representative benchmarks (Video-MME and DREAM-1K) to understand the impact of frame numbers and resolution.
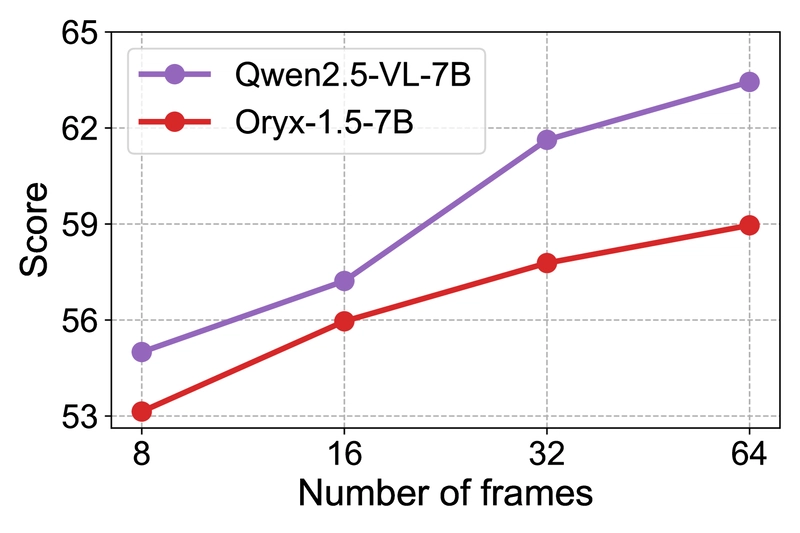
Impact of the number of frames (720P) on Video-MME and Dream1K performance.
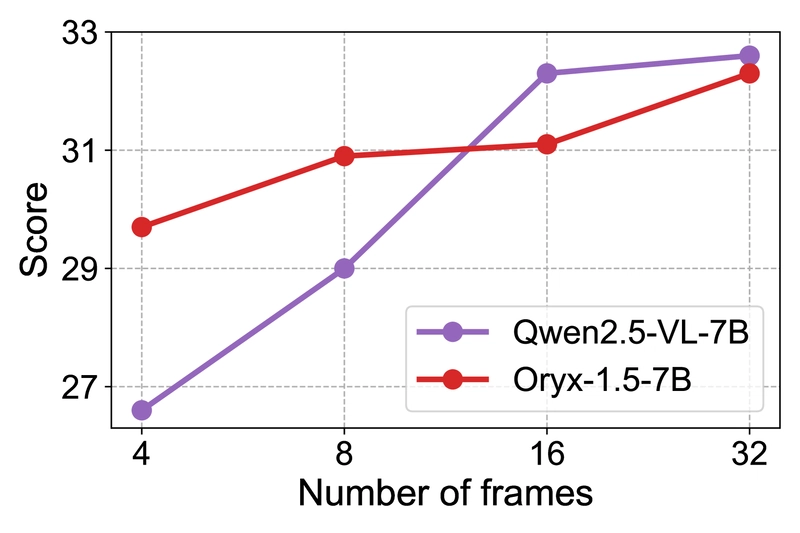
Impact of the resolution of frames (64 frames) on Video-MME and Dream1K performance.
The results revealed that:
- Performance increases significantly when increasing the number of frames, demonstrating the necessity of dense sampling
- Higher resolution is critical for tasks like video captioning but less important for multiple-choice question answering
These findings confirmed that real-world video understanding tasks rely on fine-grained spatiotemporal contexts, necessitating dense sampling of high-resolution frames while maintaining computational efficiency.
Mavors: A Multi-granularity Approach to Video Encoding
Mavors enhances video understanding capability by introducing an efficient video encoding strategy based on dense sampling with high resolution.

The architecture of Mavors showing how it processes video content and images.
The system employs a video encoder that directly processes pixel information from video chunks, converting them into latent representations. Mavors follows an auto-regressive architecture to generate textual responses based on given textual instructions.
The processing pipeline consists of:
- Preprocessing raw videos or images
- Using an intra-chunk vision encoder and inter-chunk feature aggregator to comprehend videos while preserving spatial and temporal details
- Passing temporally integrated features through an MLP projector for modality alignment before input to the LLM
Intra-chunk Vision Encoder: Capturing Spatial Details
Mavors partitions video frames into chunks, where each chunk contains consecutive frames describing dynamic scenes and temporal events. The Intra-chunk Vision Encoder represents the visual features of the video content.
This encoder begins with 3D convolutions applied to individual video chunks to extract visual features. A Vision Transformer then captures high-level spatial-temporal features within each chunk. To manage computational complexity, a 2x2 pooling layer reduces the token count before further processing.
The encoder is initialized with SigLIP weights, with 2D convolutional kernels replicated along the temporal dimension to form 3D kernels. This initialization ensures the model's initial behavior matches its capability for single image-text understanding.
Inter-chunk Feature Aggregator: Preserving Temporal Coherence
While the intra-chunk vision encoder captures high-level visual features within video chunks, the Inter-chunk Feature Aggregator integrates temporal information across multiple video chunks of the complete video.
This component consists of Transformer layers with Causal Attention. To identify the sequential order of visual features, Mavors proposes chunk-level Rotary Encoding (C-RoPE) for the Transformer layers, ensuring temporal information is correctly retained.
This approach allows Mavors to establish more robust temporal dependencies across chunks compared to existing methods that rely on sparse sampling or aggressive token compression.
Flexible Input Processing
Mavors processes videos with arbitrary resolutions and aspect ratios using a dynamic resolution strategy that maintains the original aspect ratio, avoiding distortion artifacts from fixed-shape resizing.
For long videos, the system employs accelerated playback through frame dropping, reducing the total frame count to be compatible with processing limits. The position IDs used by C-RoPE correspond to timestamps from the original timeline, informing the model that processed frames are not temporally contiguous.
For images, Mavors first partitions the raw image into several sub-images and then processes the thumbnail of the original image alongside all sub-images. This approach enables detailed image understanding while maintaining compatibility with the video processing pipeline.
Progressive Training: Building Video Understanding Capabilities
Mavors employs a multi-stage training approach to improve collaboration between the video encoder and LLM and enhance performance on multimodal tasks.
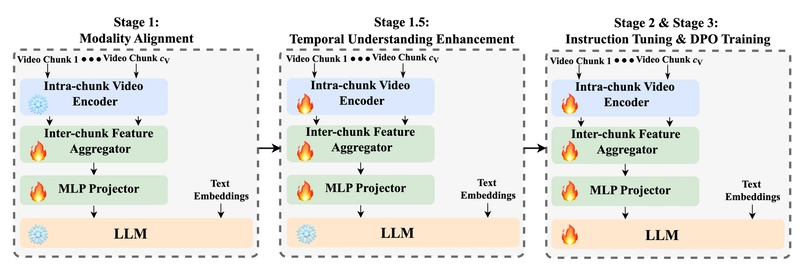
Training paradigm showing the different stages in the Mavors training process.
The training proceeds through several stages:
Modality Alignment: Aligns the semantic space of the vision encoder with the LLM's semantic space by training the inter-chunk feature aggregator and MLP projector while keeping the LLM and intra-chunk vision encoder frozen
Temporal Understanding Enhancement: Focuses on enhancing the video encoder's capacity for genuine video comprehension by updating all components excluding the LLM
Multitask Instruction Tuning: Adapts the model for various multi-modal tasks, adding grounding tasks and temporal grounding tasks to enhance perception of spatiotemporal details
DPO Training: Addresses issues with response style and length using Direct Preference Optimization
The training strategy employs next-token-prediction in all stages except DPO, which uses the standard DPO loss.
Empirical Evaluation: Performance Across Diverse Benchmarks
How Mavors Was Tested
The Mavors model utilizes Qwen2.5-7B as its language model module, with the intra-chunk vision encoder initialized using SigLIP weights. The frame count per video chunk is set to 16, and the inter-chunk feature aggregator consists of 3 layers.
Training occurred on 416 A800-80GB GPUs using DeepSpeed with ZeRO stage 2 optimization. The pre-training proceeded in three stages:
- Stage 1: ~127 million samples, global batch size of 6,656, taking 71 hours
- Stage 1.5: 52 million samples, global batch size of 3,328, taking 177 hours
- Stage 2: 19 million samples, global batch size of 1,664, requiring 28 hours
For inference, Mavors uses the vLLM framework, with an overlapping pipeline to balance CPU-bound preprocessing, compute-intensive visual encoding, and language model inference.
| Qwen2.5VL-7B | Mavors-7B | |
|---|---|---|
| Images | Prefilling (ms) | 397 |
| Decoding (token/s) | 23 | |
| Videos | Prefilling (ms) | 1,225 |
| Decoding (token/s) | 22 |
Inference efficiency between Qwen2.5VL-7B and Mavors-7B. Model performs better when Prefilling (ms) is lower and Decoding (token/s) is larger.
Performance Results: Video and Image Understanding
Mavors was compared against several baseline models on various video and image benchmarks.
| Model | Size | MMWorld | PerceptionTest | Video-MME | MLVU | MVBench | EventHallusion | TempCompass | VinoGround | DREAM-1K |
|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4o-20240806 | - | 62.5 | - | 71.9 | 64.6 | 64.6 | 92.0 | 73.8 | 38.9 | 39.2 |
| Qwenai-1.5 Pro | 75.0 | 60.5 | 80.3 | 67.1 | 22.0 | 36.2 | ||||
| LLaVA-OneVision | 7B | 59.2 | 56.9 | 58.9 | 64.8 | 56.7 | 64.3 | 61.4 | 26.2 | 31.9 |
| InternVL 2.5 | 8B | 62.2 | 65.0 | 64.3 | 67.0 | 72.0 | 64.1 | 71.4 | 24.0 | 29.7 |
| NVILA | 8B | 55.2 | 55.5 | 64.2 | 70.1 | 68.1 | 69.9 | 66.5 | 20.2 | 26.9 |
| LLaVA-Video | 7B | 60.1 | 67.5 | 63.6 | 67.2 | 58.6 | 70.7 | 65.7 | 26.9 | 33.3 |
| Oryx-1.5 | 7B | 58.8 | 70.3 | 59.0 | 63.8 | 67.5 | 61.3 | 60.2 | 22.3 | 32.5 |
| Qwen2.5-VL | 7B | 61.3 | 66.2 | 65.1 | 70.2 | 69.6 | 66.5 | 71.4 | 34.6 | 32.6 |
| VideoLLaMA3 | 7B | 56.4 | 72.8 | 66.2 | 73.0 | 69.7 | 63.4 | 68.1 | 31.3 | 30.5 |
| VideoChat-Flash | 7B | 57.9 | 74.7 | 65.3 | 74.7 | 74.0 | 66.4 | 70.0 | 33.3 | 29.5 |
| Slow-fast MLLM | 7B | 58.2 | 69.7 | 60.2 | 60.4 | 68.9 | 67.4 | 69.9 | 27.1 | 33.2 |
| Qwen2.5-VL | 72B | 73.1 | 73.2 | 73.3 | 76.6 | 70.4 | 76.5 | 79.1 | 58.6 | 35.1 |
| InternVL 2.5 | 78B | 77.2 | 73.5 | 72.1 | 76.6 | 76.4 | 67.7 | 75.5 | 38.7 | 39.3 |
| Mavors (Ours) | 7B | 68.1 | 70.3 | 65.0 | 69.8 | 68.0 | 73.5 | 77.4 | 36.9 | 39.4 |
Performance on video benchmarks across various models and tasks.
On video benchmarks, Mavors successfully balances the trade-offs inherent in different approaches. It delivers performance on long video QA nearly on par with dense sampling and token compression techniques while preserving robust capabilities for knowledge-based and temporal reasoning tasks. The substantial gains in captioning highlight its effectiveness in achieving accurate and comprehensive understanding of entire video events.
| Model | Size | MMMU | MathVista | AI2D | CapsBench |
|---|---|---|---|---|---|
| GPT-4o-20240806 | - | 69.9 | 62.9 | 84.7 | 67.3 |
| Gemin1-1.5-Pix | - | 60.6 | 58.3 | 79.1 | 71.2 |
| CogVLM2 | 8B | 42.6 | 38.7 | 73.4 | 50.9 |
| GLM-4V | 9B | 46.9 | 52.2 | 71.2 | 61.0 |
| LLaVA-OneVision | 7B | 47.9 | 62.6 | 82.4 | 57.4 |
| InternVL 2.5 | 8B | 56.2 | 64.5 | 84.6 | 66.5 |
| Qwen2.5-VL | 7B | 58.0 | 68.1 | 84.3 | 64.9 |
| DeepBook-VL2 | 27B | 54.0 | 63.9 | 83.8 | 61.3 |
| Qwen2.5-VL | 72B | 68.2 | 74.2 | 88.5 | 70.1 |
| InternVL 2.5 | 78B | 70.0 | 70.6 | 89.1 | 68.5 |
| Mavors (Ours) | 7B | 53.2 | 69.2 | 84.3 | 75.2 |
Performance on image benchmarks comparing Mavors with other models.
For image benchmarks, Mavors achieves performance on par with similarly-sized image understanding models in Image QA. Its captioning performance is particularly strong, surpassing even 72B models. This effectiveness stems from Mavors's architecture, where images and videos offer complementary visual perception within the intra-chunk vision encoder but are processed without mutual interference by the inter-chunk feature aggregator.
Ablation Studies: Validating Design Choices
Several ablation studies were conducted to validate the model design choices.
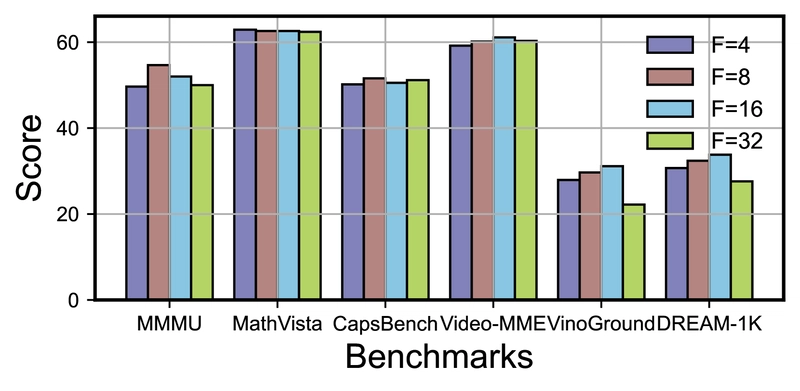
Performance with different numbers of frames in a video chunk across various benchmarks.
The number of frames per video chunk (F) was tested with values of 4, 8, 16, and 32. For image-based tasks, a marginal improvement in performance was observed with increasing F, likely due to increased exposure to individual frames during video processing. For video understanding tasks, performance degraded significantly for F=4 (insufficient temporal information) and F=32 (excessive information compression). The F=16 setting was chosen to ensure exposure to richer visual information.
The effect of the Inter-chunk Feature Aggregator (IFA) was tested by varying the number of transformer layers (LInter). For image evaluation tasks, removing the transformer layers showed a slight advantage, potentially due to the lower parameter count facilitating faster convergence on static perception tasks. For video evaluation, a deeper inter-chunk feature aggregator (LInter=3) enhanced understanding, leading to better scores, although with diminishing returns for more layers.
The effectiveness of Chunk-level Rotary Encoding (C-RoPE) was assessed against standard RoPE. For image understanding, both variants performed comparably since the IFA architecture processes sub-images independently. For video understanding, C-RoPE outperformed standard RoPE by an average of 0.6 points, indicating that standard RoPE struggles to differentiate intra-chunk from inter-chunk tokens and may hinder temporal sequence modeling.
Further Analysis: Token Compression and Training Dynamics
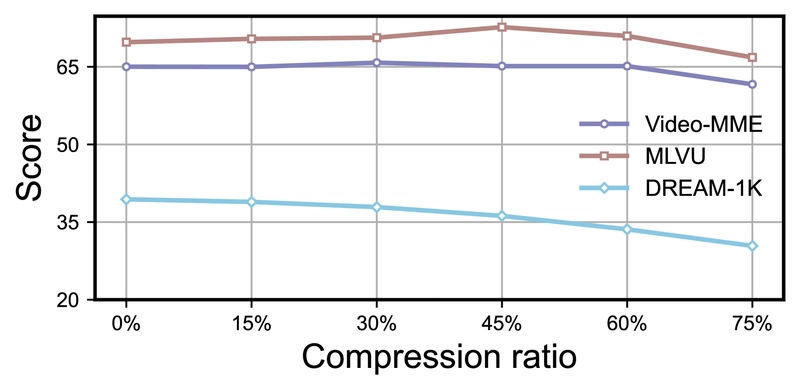
Performance with different token compression ratios showing varying impact across tasks.
Token compression techniques were applied within Mavors to decrease the number of tokens on each video chunk. Results indicated that Mavors' performance on video QA remained largely unaffected with token reductions up to 60%, while significant performance degradation was observed for video captioning. This suggests that token compression can be a feasible strategy for reducing inference costs in long-video QA applications.
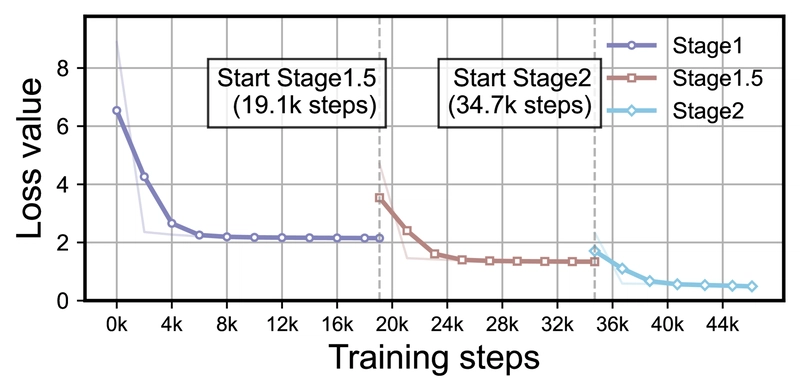
The dynamic of training losses across different stages for Mavors.
Analysis of training dynamics showed consistent improvement across the three training stages (Stage 1, Stage 1.5, and Stage 2) on both image and video tasks, with the DPO stage providing further enhancements.
| Stage | MMMU | CapsBench | Video-MME | DREAM-1K |
|---|---|---|---|---|
| Stage 1 | 36.3 | 54.8 | 48.4 | 23.6 |
| Stage 1.5 | 47.3 | 62.5 | 53.9 | 26.3 |
| Stage 2 | 53.0 | 73.4 | 65.0 | 38.9 |
| DPO | 53.2 | 75.2 | 65.0 | 39.2 |
Results of different training stages showing consistent improvement across benchmarks.

Comparison of generated video captions from Qwen2.5-VL-7B and Mavors-7B, showing Mavors' superior detail capture.
Visualization of captions generated for a complex video from DREAM-1K revealed that despite processing densely sampled frames, Qwen2.5VL-7B failed to capture many details (e.g., omitting the mention of a cow driving). In contrast, Mavors-7B predicted fine-grained and correct details, demonstrating the effectiveness of its multi-granularity approach.
Advancing Video Understanding in MLLMs
Mavors represents a significant step forward in long-context video understanding for MLLMs. By introducing multi-granularity video representation through its Intra-chunk Vision Encoder and Inter-chunk Feature Aggregator, the framework preserves both spatial details and temporal dynamics while maintaining computational efficiency.
The system's unified approach to image and video understanding, treating images as single-frame videos through sub-image decomposition, allows it to excel across diverse multimodal tasks without sacrificing performance in either modality.
Extensive experiments across multiple benchmarks demonstrate Mavors' effectiveness in maintaining both spatial fidelity and temporal coherence, outperforming existing methods in tasks requiring fine-grained spatiotemporal reasoning. This advancement opens new possibilities for applications requiring comprehensive understanding of long video content, from content moderation to video summarization and analysis.


