

.jpg)

























![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)














































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)









































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)








































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



























































































![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)










![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)



























































































































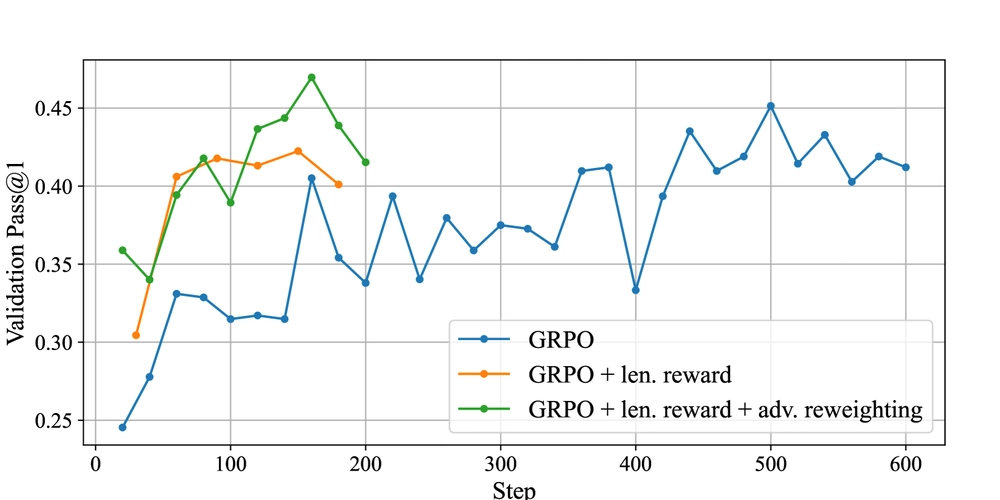
AI Math Breakthrough: GRPO-LEAD Improves Reasoning & Cuts Solution Lengths by 30%
This is a Plain English Papers summary of a research paper called AI Math Breakthrough: GRPO-LEAD Improves Reasoning & Cuts Solution Lengths by 30%. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Overview New AI training method called GRPO-LEAD makes math reasoning clearer and more efficient Uses difficulty levels to improve how language models learn math Combines reinforcement learning with adaptive difficulty scaling Achieves better results than previous methods on math problem benchmarks Produces more concise and accurate mathematical explanations Plain English Explanation GRPO-LEAD teaches AI to solve math problems the way a good tutor would. Instead of throwing random problems at the AI, it carefully adjusts the difficulty based on how well the AI is... Click here to read the full summary of this paper
This is a Plain English Papers summary of a research paper called AI Math Breakthrough: GRPO-LEAD Improves Reasoning & Cuts Solution Lengths by 30%. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- New AI training method called GRPO-LEAD makes math reasoning clearer and more efficient
- Uses difficulty levels to improve how language models learn math
- Combines reinforcement learning with adaptive difficulty scaling
- Achieves better results than previous methods on math problem benchmarks
- Produces more concise and accurate mathematical explanations
Plain English Explanation
GRPO-LEAD teaches AI to solve math problems the way a good tutor would. Instead of throwing random problems at the AI, it carefully adjusts the difficulty based on how well the AI is...


