



























![[Webinar] AI Is Already Inside Your SaaS Stack — Learn How to Prevent the Next Silent Breach](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEiOWn65wd33dg2uO99NrtKbpYLfcepwOLidQDMls0HXKlA91k6HURluRA4WXgJRAZldEe1VReMQZyyYt1PgnoAn5JPpILsWlXIzmrBSs_TBoyPwO7hZrWouBg2-O3mdeoeSGY-l9_bsZB7vbpKjTSvG93zNytjxgTaMPqo9iq9Z5pGa05CJOs9uXpwHFT4/s1600/ai-cyber.jpg?#)















































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)







































































































































































































![Rogue Company Elite tier list of best characters [April 2025]](https://media.pocketgamer.com/artwork/na-33136-1657102075/rogue-company-ios-android-tier-cover.jpg?#)








































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





























































































![What’s new in Android’s April 2025 Google System Updates [U: 4/18]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2025/01/google-play-services-3.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)








![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)





























































































































TextArena: LLM Games Test Reasoning, Negotiation, & Deception Skills
This is a Plain English Papers summary of a research paper called TextArena: LLM Games Test Reasoning, Negotiation, & Deception Skills. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. The Next Frontier in LLM Evaluation: Competitive Text-Based Games As frontier language models like GPT-4o, Claude, and Gemini approach perfection on traditional benchmarks like MMLU and HumanEval, researchers face a mounting challenge: how to meaningfully evaluate increasingly capable AI systems. Even complex benchmarks like the ARC-AGI challenge are nearing saturation, suggesting traditional evaluation approaches may soon become obsolete. TextArena offers a compelling solution - an open-source framework featuring 57+ diverse text-based games for evaluating language models through competitive gameplay. Unlike static benchmarks, this approach focuses on relative performance measures that can scale with model capabilities while testing crucial social skills like negotiation, theory of mind, and deception. TextArena Soft-skill comparison. Frontier models and Humanity are compared across ten key skills. Each skill is normalised separately for presentation; see the leaderboard for full data. Design Philosophy: A Flexible, Extensible Framework TextArena prioritizes ease of adoption, use, and extension. The framework adopts interfaces similar to OpenAI Gym (Brockman et al., 2016), making it particularly well-suited for reinforcement learning applications. The design emphasizes stackable wrappers and streamlined game functionality, making it straightforward to add new environments. Here's a simple example of TextArena in action: # Initialize agents agents = { 0: ta.agents.OpenRouterAgent(model_name="GPT-4o-mini"), 1: ta.agents.OpenRouterAgent(model_name="anthropic/claude-3.5-haiku"), } # Initialize environment env = ta.make(env_id=["TicTacToe-v0", "SpellingBee-v0"]) env = ta.wrappers.LLMObservationWrapper(env=env) env.reset(num_players=len(agents)) done = False while not done: player_id, observation = env.get_observation() action = agents[player_id](observation) done, info = env.step(action=action) rewards = env.close() Detailed documentation, tutorials for training and evaluation, and additional information are available on textarena.ai. Diverse Game Environments TextArena offers an extensive collection of text-based games spanning single-player, two-player, and multi-player scenarios. These environments test a wide range of abilities including reasoning, theory of mind, risk assessment, vocabulary skills, pattern recognition, spatial reasoning, planning, memory, deception, negotiation, persuasion, and resource management. All games are either natively text-based or have been adapted to function in a text-based format, ensuring consistency across the framework. Images of some (rendered) TextArena environments. Dynamic Evaluation System TextArena employs a competitive-based evaluation system using TrueSkill™ (Herbrich et al., 2006), a Bayesian skill rating system originally developed for matchmaking in competitive games. This approach offers several advantages: Accurate ratings for both team-based and individual competitions Support for matches with varying numbers of players Faster convergence to reliable skill estimates than traditional Elo systems Appropriate uncertainty management for new participants Each model begins with a standardized TrueSkill™ rating (μ=25, σ=25/3), with ratings adjusted after every match. Human players are collectively represented as "Humanity" on the leaderboard, providing a natural benchmark. Beyond overall performance rankings, TextArena provides detailed soft-skill profiling. Each environment is tagged with up to five soft skills (Strategic Planning, Spatial Thinking, Pattern Recognition, Theory of Mind, Logical Reasoning, Memory Recall, Bluffing, Persuasion, Uncertainty Estimation, and Adaptability) with corresponding weights. As models accumulate ratings across multiple environments, their aptitude in each skill category is calculated as a weighted average. This granular evaluation reveals specific strengths and weaknesses across models, providing researchers with actionable insights beyond aggregate rankings. Preliminary model rankings for a subset of models and games. Game-play results are influenced by both the models' ability to play the games and their ability to understand the rules and format. For example, some reasoning models can sometimes reveal their cards or roles during game-play. Comparison with Existing Benchmarks TextArena significantly expands upon previous game-based LLM evaluation frameworks. The following table compares TextArena with recent benchmarks across key dimensions: Benchmark/Study Number of Environments Gym-Compatible API Online Evaluation Model vs Model Model vs Human Single-Player Two-Player Multi-Player Clembench (Chalama
This is a Plain English Papers summary of a research paper called TextArena: LLM Games Test Reasoning, Negotiation, & Deception Skills. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
The Next Frontier in LLM Evaluation: Competitive Text-Based Games
As frontier language models like GPT-4o, Claude, and Gemini approach perfection on traditional benchmarks like MMLU and HumanEval, researchers face a mounting challenge: how to meaningfully evaluate increasingly capable AI systems. Even complex benchmarks like the ARC-AGI challenge are nearing saturation, suggesting traditional evaluation approaches may soon become obsolete.
TextArena offers a compelling solution - an open-source framework featuring 57+ diverse text-based games for evaluating language models through competitive gameplay. Unlike static benchmarks, this approach focuses on relative performance measures that can scale with model capabilities while testing crucial social skills like negotiation, theory of mind, and deception.
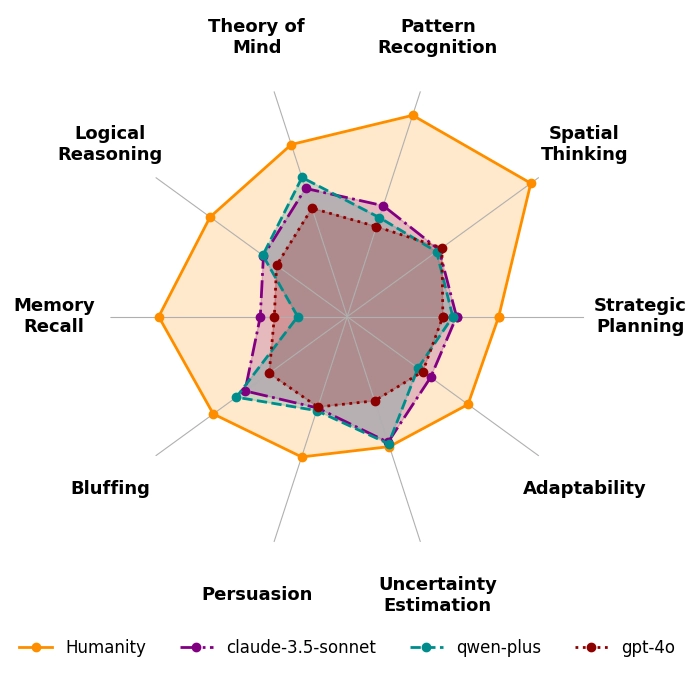
TextArena Soft-skill comparison. Frontier models and Humanity are compared across ten key skills. Each skill is normalised separately for presentation; see the leaderboard for full data.
Design Philosophy: A Flexible, Extensible Framework
TextArena prioritizes ease of adoption, use, and extension. The framework adopts interfaces similar to OpenAI Gym (Brockman et al., 2016), making it particularly well-suited for reinforcement learning applications. The design emphasizes stackable wrappers and streamlined game functionality, making it straightforward to add new environments.
Here's a simple example of TextArena in action:
# Initialize agents
agents = {
0: ta.agents.OpenRouterAgent(model_name="GPT-4o-mini"),
1: ta.agents.OpenRouterAgent(model_name="anthropic/claude-3.5-haiku"),
}
# Initialize environment
env = ta.make(env_id=["TicTacToe-v0", "SpellingBee-v0"])
env = ta.wrappers.LLMObservationWrapper(env=env)
env.reset(num_players=len(agents))
done = False
while not done:
player_id, observation = env.get_observation()
action = agents[player_id](observation)
done, info = env.step(action=action)
rewards = env.close()
Detailed documentation, tutorials for training and evaluation, and additional information are available on textarena.ai.
Diverse Game Environments
TextArena offers an extensive collection of text-based games spanning single-player, two-player, and multi-player scenarios. These environments test a wide range of abilities including reasoning, theory of mind, risk assessment, vocabulary skills, pattern recognition, spatial reasoning, planning, memory, deception, negotiation, persuasion, and resource management.
All games are either natively text-based or have been adapted to function in a text-based format, ensuring consistency across the framework.

Images of some (rendered) TextArena environments.
Dynamic Evaluation System
TextArena employs a competitive-based evaluation system using TrueSkill™ (Herbrich et al., 2006), a Bayesian skill rating system originally developed for matchmaking in competitive games. This approach offers several advantages:
- Accurate ratings for both team-based and individual competitions
- Support for matches with varying numbers of players
- Faster convergence to reliable skill estimates than traditional Elo systems
- Appropriate uncertainty management for new participants
Each model begins with a standardized TrueSkill™ rating (μ=25, σ=25/3), with ratings adjusted after every match. Human players are collectively represented as "Humanity" on the leaderboard, providing a natural benchmark.
Beyond overall performance rankings, TextArena provides detailed soft-skill profiling. Each environment is tagged with up to five soft skills (Strategic Planning, Spatial Thinking, Pattern Recognition, Theory of Mind, Logical Reasoning, Memory Recall, Bluffing, Persuasion, Uncertainty Estimation, and Adaptability) with corresponding weights. As models accumulate ratings across multiple environments, their aptitude in each skill category is calculated as a weighted average.
This granular evaluation reveals specific strengths and weaknesses across models, providing researchers with actionable insights beyond aggregate rankings.
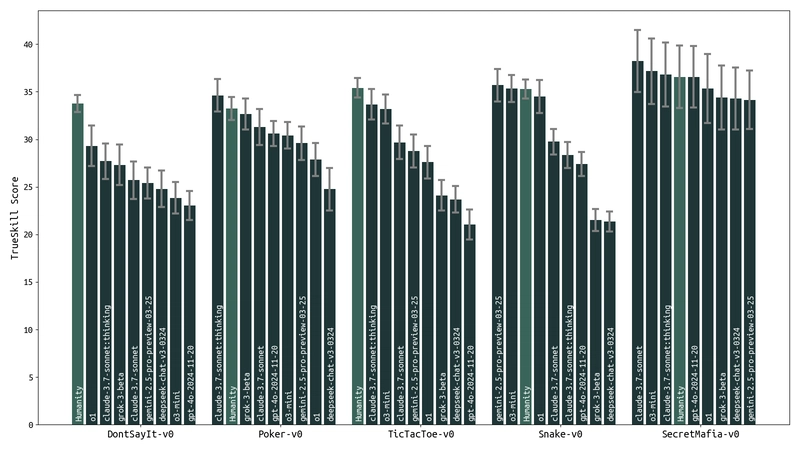
Preliminary model rankings for a subset of models and games. Game-play results are influenced by both the models' ability to play the games and their ability to understand the rules and format. For example, some reasoning models can sometimes reveal their cards or roles during game-play.
Comparison with Existing Benchmarks
TextArena significantly expands upon previous game-based LLM evaluation frameworks. The following table compares TextArena with recent benchmarks across key dimensions:
| Benchmark/Study | Number of Environments | Gym-Compatible API | Online Evaluation | Model vs Model | Model vs Human | ||
|---|---|---|---|---|---|---|---|
| Single-Player | Two-Player | Multi-Player | |||||
| Clembench (Chalamalasetti et al., 2023) | 0 | 5 | 0 | ✗ | ✗ | ✓ | ✗ |
| LMRL-Gym (Abdulhai et al., 2023) | 5 | 3 | 0 | ✓ | ✗ | ✓ | ✗ |
| GameBench (Costarelli et al., 2024) | 0 | 3 | 6 | ✓ | ✗ | ✓ | ✓ |
| Game-theoretic LLM (Hua et al., 2024) | 0 | 11 | 0 | ✗ | ✗ | ✓ | ✗ |
| LAMEN (Davidson et al., 2024) | 0 | 6 | 0 | ✗ | ✗ | ✓ | ✗ |
| GTBench (Duan et al., 2024) | 0 | 10 | 0 | ✗ | ✗ | ✓ | ✗ |
| GameArena (Hu et al., 2024) | 0 | 3 | 0 | ✗ | ✗ | ✗ | ✓ |
| SPIN-Bench (Yao et al., 2025) | 1 | 3 | 2 | ✓ | ✗ | ✓ | ✗ |
| TextArena (Ours) | 16 | 47 | 11 | ✓ | ✓ | ✓ | ✓ |
Comparison of recent benchmarks for evaluating large language models (LLMs) in game-based interaction scenarios. The table summarizes the number of supported environments and technical capabilities across frameworks.
As shown in the table, TextArena provides the most comprehensive coverage across all dimensions. With 16 single-player, 47 two-player, and 11 multi-player environments, it offers substantially greater variety than existing benchmarks. TextArena is also the only framework that fully supports all four technical capabilities: Gym-compatible API, online evaluation, model-to-model evaluation, and model-to-human evaluation.
Future Directions
The TextArena team outlines several promising directions for future development:
- RL Training: Using game environments as training data for reasoning models, potentially establishing a new training paradigm.
- Public Engagement: Inviting researchers and enthusiasts to contribute games, test models, and play against LLMs. The platform hosts 64 state-of-the-art models available online for free play.
- Data Release: Plans to release datasets including gameplay trajectories between humans and leading models like OpenAI o1, Claude-3.7-Sonnet, and Gemini-2.5-Pro.
- VideoGameArena: Building on the current work to benchmark models in competitive frame-based environments with real-time input.
Single-Player Games
TextArena's 16 single-player games test individual agent capabilities across different cognitive domains. The following table shows a subset of these games and their associated skills:
| Game Name | Players | Strat. | Spatial | Pattern | ToM | Logic | Mem. | Bluff | Pers. | Uncert. | Adapt. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| CarPuzzle* | 1 | ○ | ● | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ |
| Crosswords | 1 | ○ | ○ | ● | ○ | ● | ● | ○ | ○ | ○ | ○ |
| FifteenPuzzle | 1 | ○ | ● | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ |
| GuessTheNumber | 1 | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ● | ○ |
| GuessWho | 1 | ○ | ○ | ○ | ● | ● | ● | ○ | ○ | ● | ● |
| Hangman | 1 | ○ | ○ | ○ | ○ | ● | ● | ○ | ○ | ○ | ● |
| LogicPuzzle | 1 | ● | ○ | ● | ○ | ● | ● | ○ | ○ | ○ | ● |
| Mastermind | 1 | ● | ○ | ● | ○ | ● | ○ | ○ | ○ | ○ | ○ |
| MathProof* | 1 | ○ | ○ | ● | ○ | ● | ● | ○ | ○ | ○ | ○ |
| Minesweeper | 1 | ○ | ○ | ● | ○ | ● | ○ | ○ | ○ | ● | ○ |
| Sudoku | 1 | ○ | ○ | ● | ○ | ● | ● | ○ | ○ | ○ | ○ |
| TowerOfHanoi | 1 | ● | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ |
| TwentyQuestions | 1 | ○ | ○ | ○ | ● | ● | ○ | ○ | ○ | ● | ○ |
| WordLadder | 1 | ○ | ○ | ● | ○ | ● | ● | ○ | ○ | ○ | ○ |
| WordSearch | 1 | ○ | ○ | ● | ○ | ● | ● | ○ | ○ | ○ | ○ |
| Wordle | 1 | ○ | ○ | ● | ○ | ● | ● | ○ | ○ | ○ | ○ |
This table categorizes single-player games by the primary cognitive or strategic skills emphasized in each game. Filled circles (●) are skills that are relevant to each game, while empty circles (○) indicate skills not emphasized. Games marked with * have not been fully implemented yet.
These games range from classic puzzles like Sudoku and Crosswords to more dynamic challenges like GuessWho and TwentyQuestions. Most single-player games emphasize logical reasoning, pattern recognition, and memory recall, providing a foundation for evaluating core cognitive abilities before moving to more complex social interactions.
Two-Player Games
The largest category in TextArena is two-player games, with 47 distinct environments testing strategic interaction between agents. Here's a sample from the extensive list:
| Game Name | Players | Strat. | Spatial | Pattern | ToM | Logic | Mem. | Bluff | Pers. | Uncert. | Adapt. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| AirLandAndSea^(†,*) | 2 | ● | ○ | ○ | ● | ● | ○ | ○ | ○ | ● | ● |
| BattleOfSexes^(†,*) | 2 | ● | ○ | ○ | ● | ○ | ○ | ○ | ● | ○ | ○ |
| Battleship | 2 | ○ | ● | ● | ○ | ● | ○ | ○ | ○ | ● | ○ |
| Chess | 2 | ● | ● | ● | ○ | ● | ● | ○ | ○ | ○ | ○ |
| Debate | 2 | ○ | ○ | ○ | ● | ● | ○ | ○ | ● | ○ | ● |
| IteratedPrisonersDilemma | 2 | ● | ○ | ○ | ● | ○ | ○ | ○ | ○ | ● | ● |
| KuhnPoker^(‡) | 2 | ● | ○ | ○ | ● | ○ | ○ | ● | ○ | ● | ○ |
| SimpleNegotiation | 2 | ● | ○ | ○ | ● | ○ | ○ | ● | ○ | ○ | ● |
| Stratego | 2 | ● | ○ | ● | ● | ○ | ○ | ○ | ○ | ● | ● |
| TicTacToe | 2 | ● | ○ | ○ | ○ | ● | ○ | ○ | ○ | ○ | ○ |
| TruthAndDeception | 2 | ○ | ○ | ○ | ● | ● | ○ | ● | ● | ● | ○ |
This table shows a subset of two-player games and their associated skills. Games marked with † are drawn from Costarelli et al. (2024), ‡ from Hua et al. (2024), and * indicates games not fully implemented yet.
Two-player games in TextArena span a wide spectrum, from classic board games like Chess and TicTacToe to more socially complex games like Debate, TruthAndDeception, and various negotiation scenarios. These environments particularly emphasize strategic planning, theory of mind, and uncertainty estimation - skills crucial for effective human-AI interaction.
Multi-Player Games
TextArena's 11 multi-player games test complex social dynamics and group interactions:
| Game Name | Players | Strat. | Spatial | Pattern | ToM | Logic | Mem. | Bluff | Pers. | Uncert. | Adapt. |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Blind Auction | 3-15 | ○ | ○ | ○ | ● | ○ | ○ | ○ | ● | ● | ○ |
| Character Conclave | 3-15 | ● | ○ | ○ | ● | ○ | ○ | ○ | ● | ○ | ● |
| Codenames^(†) | 4 | ● | ○ | ● | ● | ● | ○ | ○ | ● | ○ | ○ |
| Liar's Dice | 2-15 | ○ | ○ | ○ | ● | ○ | ● | ● | ○ | ● | ○ |
| Negotiation | 3-15 | ● | ○ | ○ | ● | ○ | ○ | ○ | ● | ○ | ○ |
| Pit^(††) | 3+ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ● | ○ |
| Poker | 2-15 | ● | ○ | ○ | ● | ○ | ○ | ● | ● | ● | ○ |
| Snake | 2-15 | ● | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| Surround | 2-15 | ● | ● | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| Two Rooms and a Boom^(†) | 6+ | ● | ○ | ○ | ● | ○ | ○ | ○ | ● | ○ | ○ |
| Diplomacy | 3-7 | ● | ○ | ○ | ● | ○ | ○ | ○ | ● | ○ | ● |
This table categorizes multi-player games by the primary cognitive or strategic skills emphasized in each. Games marked with † and †† indicate different sources in the original research.
Multi-player games like Diplomacy, Poker, and Two Rooms and a Boom test advanced social capabilities like persuasion, strategic planning, and theory of mind in more complex settings with multiple competing and potentially collaborating agents. These environments closely mirror real-world social dynamics, providing valuable insights into how LLMs might function in multi-party human interactions.
TextArena represents an innovative step forward in LLM evaluation, shifting from static benchmarks to dynamic, competitive gameplay. By testing models across diverse environments and tracking performance through a relative rating system, TextArena offers a more nuanced understanding of model capabilities while creating a sustainable evaluation framework that can evolve alongside advancing AI systems.


