











































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)


















































































































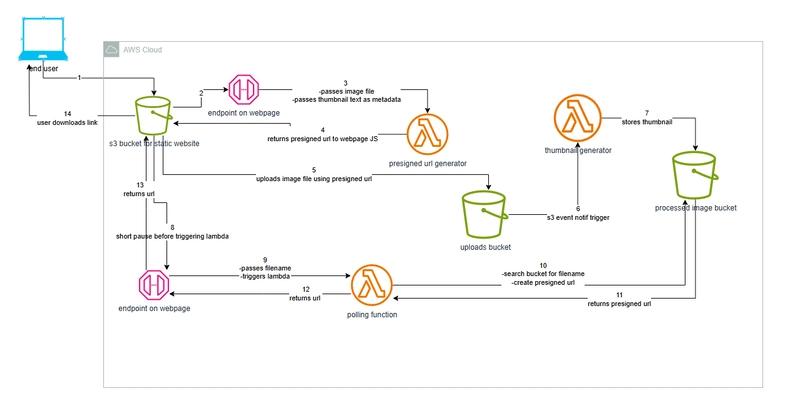


























































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)























































































_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)















































































































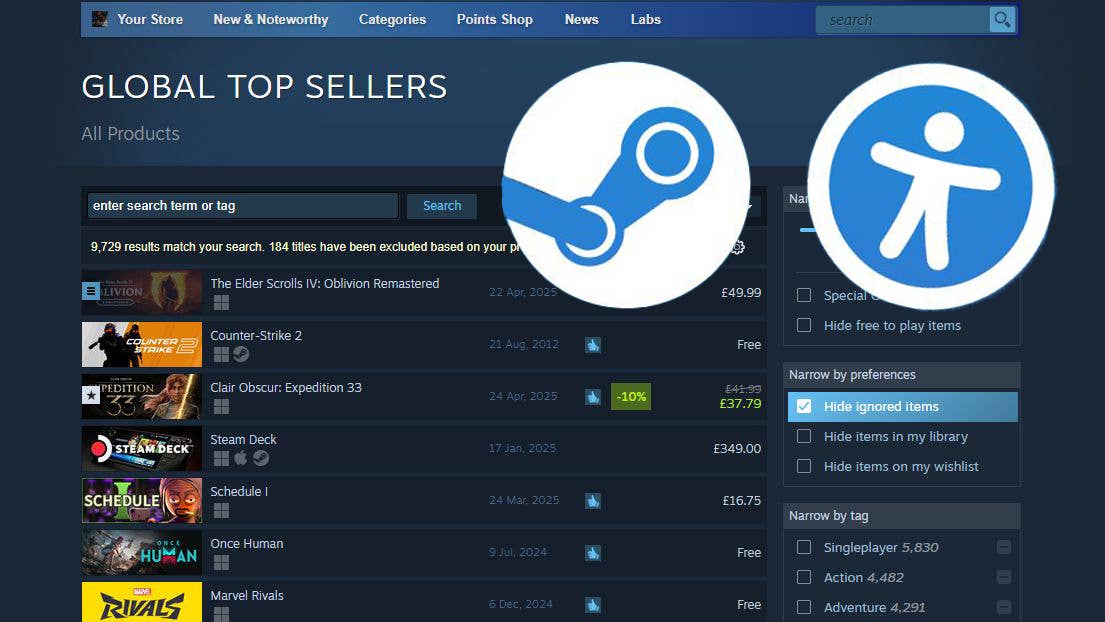
![Most iPhones Sold in the U.S. Will Be Made in India by 2026 [Report]](https://www.iclarified.com/images/news/97130/97130/97130-640.jpg)
![Apple to Shift Robotics Unit From AI Division to Hardware Engineering [Report]](https://www.iclarified.com/images/news/97128/97128/97128-640.jpg)

























































































































LLMs vs Web3: New Benchmark Reveals Which AI Gets Blockchain
This is a Plain English Papers summary of a research paper called LLMs vs Web3: New Benchmark Reveals Which AI Gets Blockchain. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. DMind: Evaluating How Well LLMs Understand Web3 Large Language Models (LLMs) have shown impressive abilities in many areas, but how well do they understand the complex world of Web3? While general benchmarks help assess broad capabilities, they don't capture the unique challenges of blockchain technology and decentralized applications. Researchers have developed DMind Benchmark, the first comprehensive framework for evaluating LLM performance across the Web3 domain. This benchmark goes beyond simple questions to include real-world tasks like smart contract auditing and financial calculations. Figure 1: Overall model scores showing o3-Mini and Claude-3.7-Sonnet tied for the highest score (74.7), with reasoning-enhanced models (blue bars) generally performing well. Why the Web3 Domain Needs Specialized LLM Benchmarks The emergence of Web3 represents a fundamental shift in how we interact with the internet, moving from centralized platforms to decentralized, trustless systems powered by blockchain technology. This ecosystem encompasses cryptocurrencies, smart contracts, decentralized finance (DeFi), non-fungible tokens (NFTs), and decentralized autonomous organizations (DAOs). While LLMs have demonstrated remarkable performance across many natural language processing tasks, their effectiveness in the Web3 domain remains underexplored. General benchmarks like MMLU, BIG-Bench, and HELM don't adequately capture the unique challenges posed by Web3: Technical complexity - requiring expertise in blockchain protocols, cryptography, and smart contract languages Interdisciplinary nature - combining computer science, economics, game theory, and law Rapid evolution - with constantly emerging concepts, standards, and applications Security-critical applications - where errors can lead to significant financial losses DMind Benchmark addresses these challenges by providing a comprehensive evaluation framework that spans nine critical categories of the Web3 ecosystem. Unlike existing benchmarks, it combines multiple-choice questions with domain-specific subjective tasks designed to replicate real-world scenarios. Understanding the Landscape: Benchmarks and Web3 The Evolution of LLM Benchmarks Early general-purpose benchmarks like GLUE and SuperGLUE focused primarily on natural language understanding tasks. More recent efforts expanded the scope: MMLU (Massive Multitask Language Understanding) evaluates models across 57 diverse subject areas BIG-Bench incorporates over 200 tasks beyond conventional NLP benchmarks HELM (Holistic Evaluation of Language Models) assesses multiple dimensions like accuracy, calibration, and fairness While these benchmarks provide valuable insights into general capabilities, they don't address the specialized demands of domains like Web3. Specialized Benchmarks for Niche Domains Recognizing the limitations of general-purpose benchmarks, researchers have created domain-specific evaluations: In medicine: MedQA, MultiMedQA, and MedMCQA In finance: FinBen and FinEval In legal reasoning: LegalBench In cybersecurity: CyberBench Until DMind, however, no comprehensive benchmark existed for the Web3 domain despite its growing importance and unique challenges. The Nine Pillars of Web3 Technology DMind Benchmark is structured around nine core dimensions that form the foundation of the Web3 ecosystem: Fundamental Blockchain Concepts - distributed ledger technologies, cryptographic primitives, and consensus mechanisms like Proof of Work and Proof of Stake Blockchain Infrastructures - Layer-1 blockchains (Ethereum, Solana), Layer-2 scaling solutions, oracle networks, and cross-chain communication protocols Smart Contract Analysis - identifying logical flaws, optimizing performance, and detecting vulnerabilities in self-executing code deployed on blockchain networks DeFi Mechanisms - automated market makers, liquidity pools, lending protocols, and decentralized exchanges that reimagine traditional financial services Decentralized Autonomous Organizations (DAOs) - collective governance through smart contracts, enabling community-driven decision-making Non-Fungible Tokens (NFTs) - unique digital assets representing ownership of specific content or property Token Economics - design of token ecosystems including distribution, inflation, and incentive mechanisms Meme Concept - viral community-driven narratives and cultural elements that influence token adoption Security Vulnerabilities - attack vectors unique to Web3 including flash loan exploits, rug pulls, and other blockchain-specific threats Figure 2: Radar charts displaying category-specific performance for different model families across nine Web3
This is a Plain English Papers summary of a research paper called LLMs vs Web3: New Benchmark Reveals Which AI Gets Blockchain. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
DMind: Evaluating How Well LLMs Understand Web3
Large Language Models (LLMs) have shown impressive abilities in many areas, but how well do they understand the complex world of Web3? While general benchmarks help assess broad capabilities, they don't capture the unique challenges of blockchain technology and decentralized applications.
Researchers have developed DMind Benchmark, the first comprehensive framework for evaluating LLM performance across the Web3 domain. This benchmark goes beyond simple questions to include real-world tasks like smart contract auditing and financial calculations.
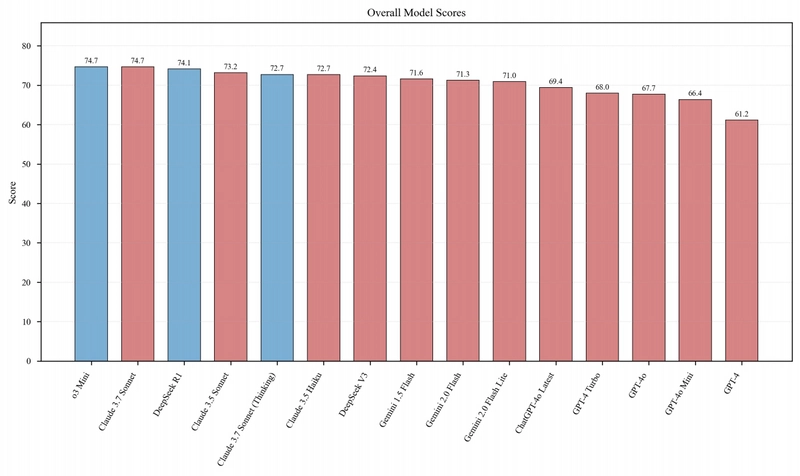
Figure 1: Overall model scores showing o3-Mini and Claude-3.7-Sonnet tied for the highest score (74.7), with reasoning-enhanced models (blue bars) generally performing well.
Why the Web3 Domain Needs Specialized LLM Benchmarks
The emergence of Web3 represents a fundamental shift in how we interact with the internet, moving from centralized platforms to decentralized, trustless systems powered by blockchain technology. This ecosystem encompasses cryptocurrencies, smart contracts, decentralized finance (DeFi), non-fungible tokens (NFTs), and decentralized autonomous organizations (DAOs).
While LLMs have demonstrated remarkable performance across many natural language processing tasks, their effectiveness in the Web3 domain remains underexplored. General benchmarks like MMLU, BIG-Bench, and HELM don't adequately capture the unique challenges posed by Web3:
- Technical complexity - requiring expertise in blockchain protocols, cryptography, and smart contract languages
- Interdisciplinary nature - combining computer science, economics, game theory, and law
- Rapid evolution - with constantly emerging concepts, standards, and applications
- Security-critical applications - where errors can lead to significant financial losses
DMind Benchmark addresses these challenges by providing a comprehensive evaluation framework that spans nine critical categories of the Web3 ecosystem. Unlike existing benchmarks, it combines multiple-choice questions with domain-specific subjective tasks designed to replicate real-world scenarios.
Understanding the Landscape: Benchmarks and Web3
The Evolution of LLM Benchmarks
Early general-purpose benchmarks like GLUE and SuperGLUE focused primarily on natural language understanding tasks. More recent efforts expanded the scope:
- MMLU (Massive Multitask Language Understanding) evaluates models across 57 diverse subject areas
- BIG-Bench incorporates over 200 tasks beyond conventional NLP benchmarks
- HELM (Holistic Evaluation of Language Models) assesses multiple dimensions like accuracy, calibration, and fairness
While these benchmarks provide valuable insights into general capabilities, they don't address the specialized demands of domains like Web3.
Specialized Benchmarks for Niche Domains
Recognizing the limitations of general-purpose benchmarks, researchers have created domain-specific evaluations:
- In medicine: MedQA, MultiMedQA, and MedMCQA
- In finance: FinBen and FinEval
- In legal reasoning: LegalBench
- In cybersecurity: CyberBench
Until DMind, however, no comprehensive benchmark existed for the Web3 domain despite its growing importance and unique challenges.
The Nine Pillars of Web3 Technology
DMind Benchmark is structured around nine core dimensions that form the foundation of the Web3 ecosystem:
Fundamental Blockchain Concepts - distributed ledger technologies, cryptographic primitives, and consensus mechanisms like Proof of Work and Proof of Stake
Blockchain Infrastructures - Layer-1 blockchains (Ethereum, Solana), Layer-2 scaling solutions, oracle networks, and cross-chain communication protocols
Smart Contract Analysis - identifying logical flaws, optimizing performance, and detecting vulnerabilities in self-executing code deployed on blockchain networks
DeFi Mechanisms - automated market makers, liquidity pools, lending protocols, and decentralized exchanges that reimagine traditional financial services
Decentralized Autonomous Organizations (DAOs) - collective governance through smart contracts, enabling community-driven decision-making
Non-Fungible Tokens (NFTs) - unique digital assets representing ownership of specific content or property
Token Economics - design of token ecosystems including distribution, inflation, and incentive mechanisms
Meme Concept - viral community-driven narratives and cultural elements that influence token adoption
Security Vulnerabilities - attack vectors unique to Web3 including flash loan exploits, rug pulls, and other blockchain-specific threats
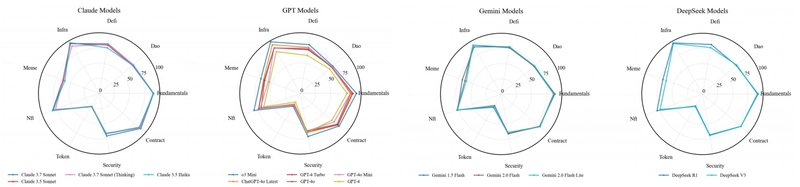
Figure 2: Radar charts displaying category-specific performance for different model families across nine Web3 dimensions: (1) Claude models, (2) GPT models, (3) Gemini models, and (4) DeepSeek models.
Current Applications of LLMs in Web3
Recent studies have explored LLMs for smart contract analysis, vulnerability detection, code generation, blockchain data analytics, cryptocurrency price forecasting, and DeFi protocol interactions. However, these investigations focus on specific use cases rather than providing systematic evaluation across the broader Web3 ecosystem.
DMind Benchmark fills this gap by spanning all nine critical categories with both multiple-choice questions and specialized subjective tasks that replicate real-world demands.
The DMind Benchmark: A Comprehensive Evaluation Framework
Building an Authoritative Web3 Benchmark
The DMind Benchmark wasn't created arbitrarily. It builds upon a rigorous examination of real-world Web3 demands and institutional preferences through a multifaceted approach:
Industry Segmentation and Institutional Adoption - mapping the domain according to prominent Web3 projects' strategic developments and funding priorities
User-Centric Considerations - reflecting typical questions and scenarios encountered by end-users in real-world blockchain applications
Data-Driven Topic Refinement - using Twitter word-frequency analysis and Google search keywords to identify trending concepts and pain points
Expert Curation and Validation - domain specialists with over five years of experience reviewed, refined, and provided reference solutions for all benchmark items
The resulting dataset comprises 1,917 questions across nine categories, each vetted through multiple stages of expert review. This structured approach ensures the benchmark's authority and comprehensiveness, providing a robust platform for assessing LLMs within the Web3 ecosystem.
Beyond Multiple Choice: Real-World Web3 Tasks
DMind Benchmark goes beyond conventional multiple-choice questions by incorporating domain-specific subjective tasks that simulate real-world scenarios:
Blockchain Fundamentals (Matching Task) - Models must match blockchain terms with their correct definitions
Blockchain Infrastructures (Concept Analysis) - Questions probe understanding of various infrastructural elements with justifications required
Smart Contracts (Code Repair/Audit Task) - Models must detect vulnerabilities in Solidity code snippets and propose corrected versions
DeFi Mechanisms (Calculation/Simulation Task) - Given protocol formulas and parameters, models must compute metrics like collateralization ratios
Decentralized Autonomous Organizations (Process Ordering Task) - Models must rearrange randomized DAO governance procedures into the correct sequence
Non-Fungible Tokens (Scenario Matching Task) - Models match user requirements to the most appropriate NFT applications
Token Economics (Model Evaluation Fill-in-the-Blank) - Models must fill in missing values in token distribution models using contextual clues
Meme Concept (Short-Answer + Key Points Check) - Models articulate key elements of Web3 meme scenarios and their impact
Security Vulnerabilities (Vulnerability Detection Task) - Models identify and explain security flaws in blockchain applications
Each task type comes with a specific scoring methodology that combines automated evaluation with expert assessment to ensure consistency and reproducibility.
Putting LLMs to the Test: Experimental Results
Overall Performance: Which Models Excel in Web3?
The researchers evaluated fifteen prominent models from four major families: ChatGPT (OpenAI), DeepSeek, Claude (Anthropic), and Gemini (Google). The results reveal interesting patterns:
- o3-Mini and Claude-3.7-Sonnet tied for the highest overall score (74.7)
- Reasoning-enhanced models (indicated by blue bars in Figure 1) generally outperform standard models
- DeepSeek R1 shows exceptional performance across various dimensions
- o3-Mini achieves one of the highest overall scores despite its compact architecture
The radar charts in Figure 2 reveal distinctive performance profiles across the four model families:
Claude models excel in Blockchain Fundamentals, Smart Contracts, and Security while showing weakness in Token Economics and Meme Concepts
GPT models exhibit considerable inter-model variance, with ChatGPT-4o Latest demonstrating the strongest overall performance within its family
Gemini models display highly coherent performance patterns, performing well in Fundamentals, Smart Contracts, and Security but struggling with Token Economics and Meme Concepts
DeepSeek models show remarkably consistent performance between variants, with strength in Fundamentals, Smart Contracts, and Security
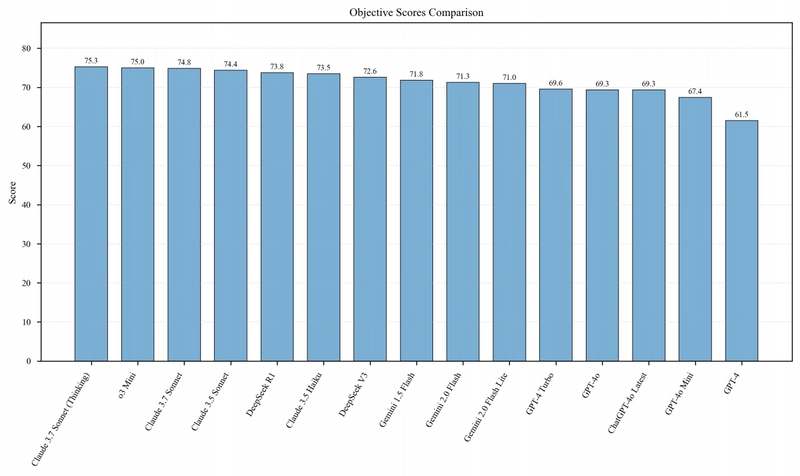
Figure 3: Comparative visualization of objective evaluation scores for each model, with reasoning-enhanced models generally showing advantages in structured Web3 questions.
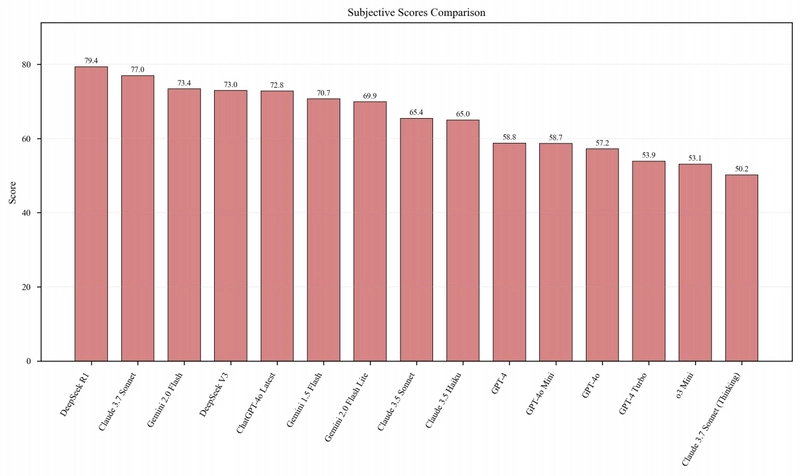
Figure 4: Comparative visualization of subjective evaluation scores for each model, highlighting significant performance variability across models for complex real-world Web3 tasks.
A notable observation across all model families is their struggle with emerging areas like Token Economics and Meme Concepts. This reflects a knowledge gap in current LLMs regarding rapidly evolving Web3 cultural and economic mechanisms.
Strengths and Weaknesses: Performance Across Web3 Dimensions
Different models exhibit distinct strengths and weaknesses across the nine Web3 dimensions. Through cluster analysis, the researchers categorized models based on their dimensional proficiencies:
Foundational Knowledge Masters - Most models perform well in Blockchain Fundamentals, with Claude and DeepSeek series demonstrating particular excellence
Technical Specialists - DeepSeek series and Claude 3.7 Sonnet excel in Smart Contract and Security dimensions, highlighting their strengths in code analysis
Application Interpreters - Gemini series shows balanced performance across application-layer concepts like DeFi and DAOs
Emerging Domain Adapters - ChatGPT-4o Latest demonstrates relatively better capabilities in Token Economics and Meme Concepts compared to other models
These diverse performance profiles offer practical insights for users selecting models based on specific Web3 scenarios. For instance, DeepSeek R1 might be preferred for smart contract auditing tasks, while Gemini models could be more suitable for analyzing DeFi protocols.
The Reasoning Advantage: Enhanced Models vs. Standard Models
The analysis specifically highlights the performance differences between reasoning-enhanced models and their standard counterparts. Models explicitly designed with enhanced reasoning capabilities (such as DeepSeek R1, Claude 3.7 Sonnet Thinking, and GPT-4 Turbo) generally outperform conventional variants, especially in tasks requiring deeper analysis.
This performance differential is particularly evident in complex subjective tasks such as smart contract vulnerability assessment and token economics analysis. The stronger performance of reasoning-oriented architectures underscores the importance of not just domain knowledge but also sophisticated reasoning abilities when tackling Web3 challenges.
Measurement Methodology: Ensuring Reliable Assessment
DMind Benchmark distinguishes itself through a combined assessment approach incorporating both objective questions (e.g., multiple-choice) and subjective tasks (e.g., code repair, numeric reasoning). While objective questions provide clear metrics of knowledge acquisition, subjective tasks evaluate problem-solving capabilities in realistic scenarios.
To ensure reproducibility and consistency in subjective evaluation, the researchers developed a semi-automated scoring pipeline:
- For code repair tasks, automated testing suites verify repair outcomes
- For numeric reasoning tasks, acceptable error margins are established
- For concept matching tasks, a combination of keyword matching and semantic similarity computation is employed
This methodology builds upon previous work in assessing LLM code generation capabilities, tailored specifically for Web3 domain requirements.
Compared to existing benchmarks, DMind emphasizes evaluating model performance in practical application contexts rather than merely testing knowledge retention. This design philosophy enables the benchmark to more accurately reflect model utility in real-world Web3 applications.
Looking Forward: Implications and Future Directions
The DMind Benchmark evaluation reveals that current LLMs, while showing promise in Web3 domains, still face significant challenges in specialized areas requiring deep domain expertise. Even state-of-the-art models struggle with identifying subtle security vulnerabilities and analyzing complex DeFi mechanisms.
The substantial performance variations across models and domains underscore the importance of continued research in domain-specific LLM training and evaluation. Future work should focus on:
- Fine-tuning LLMs to better address specialized Web3 challenges
- Developing more robust reasoning capabilities for security-critical applications
- Improving model understanding of rapidly evolving areas like token economics and meme concepts
- Creating specialized architectures that integrate knowledge across the interdisciplinary nature of Web3
To foster progress in this area, the researchers have publicly released their benchmark dataset, evaluation pipeline, and annotated results at DMind.ai. This resource offers valuable support for advancing specialized domain adaptation and developing more robust Web3-enabled LLMs.
As Web3 continues to evolve and gain widespread adoption, the need for AI systems that can effectively understand, reason, and operate within this complex landscape will only grow more critical. The DMind Benchmark provides a foundation for measuring progress toward this goal.


