![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)














































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)






















































































_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)











































































































![Most iPhones Sold in the U.S. Will Be Made in India by 2026 [Report]](https://www.iclarified.com/images/news/97130/97130/97130-640.jpg)
![Apple to Shift Robotics Unit From AI Division to Hardware Engineering [Report]](https://www.iclarified.com/images/news/97128/97128/97128-640.jpg)





























































































































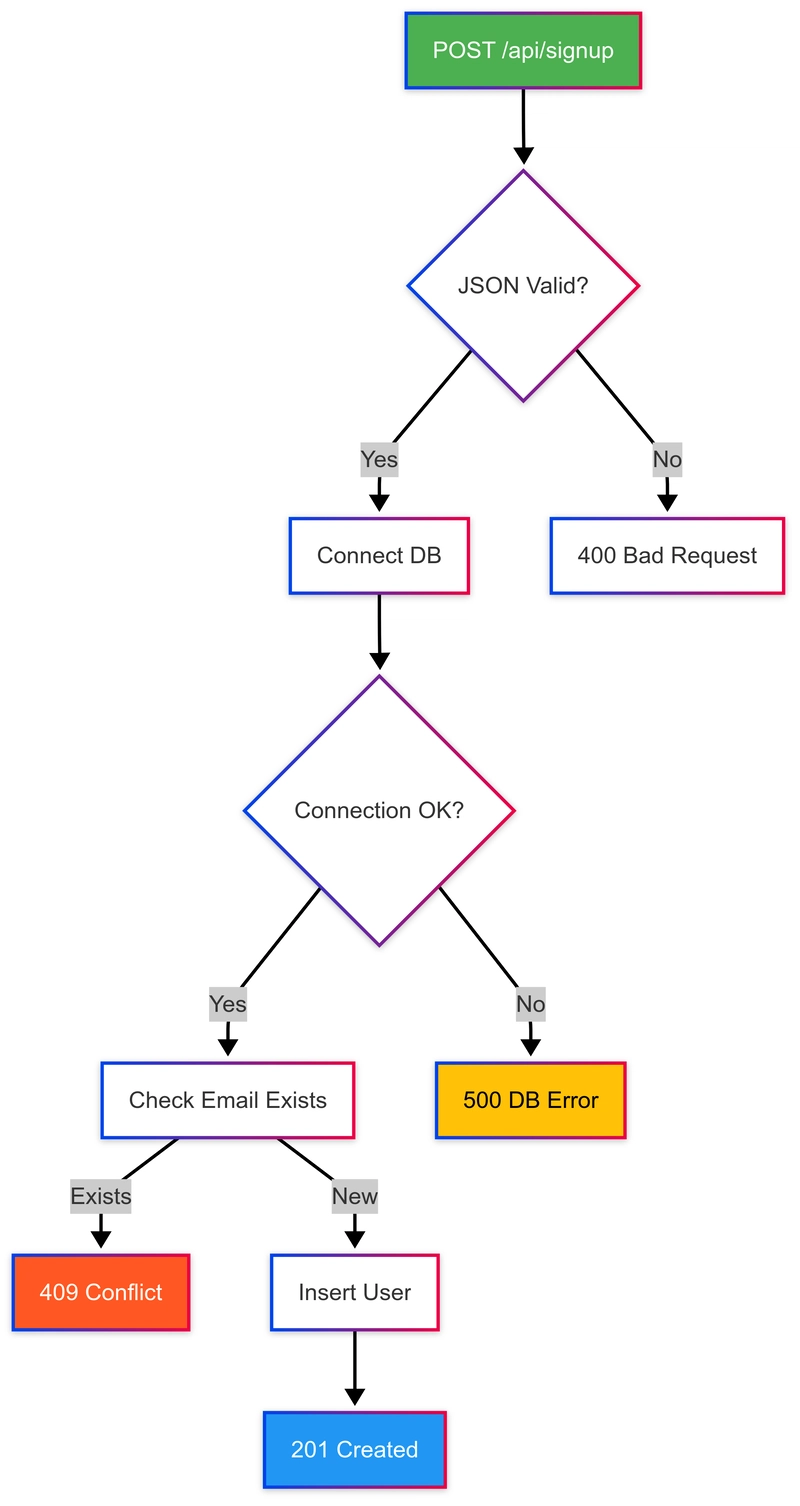
Ingest (almost) any non-PDF document in a vector database, effortlessly
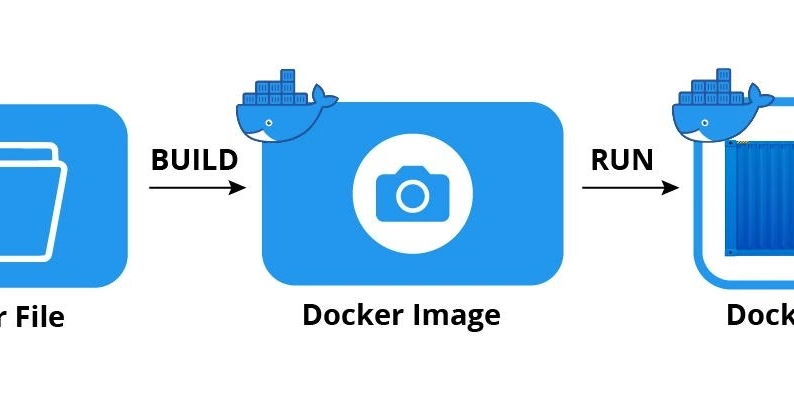
One of my areas of focus, recently, has been the development of a universal and zero-effort way of converting text-based documents (and even images) into PDF files, so that they could fit into my RAG pipelines, that are optimized for that format. In the end, after almost 30 "This is the last git commit", I came up with PdfItDown, a python package capable of transforming the most commonly used file formats into PDF, and it can do so with single or multiple files (and even entire folders!). After that, tho, I wasn't satisfied: converting files to PDF is ok, but they're unplugged from the main ingest-into-DB pipeline, which might be still a lot of effort to design and optimize. Then it came the idea: why don't I create a standardized, simple and yet powerful, fully-automated procedure to go from a non-PDF file to vector data loaded into a database? The tools were already there: PdfItDown can handle file transformation LlamaIndex has the readers to turn PDFs into text files Chonkie offers a versatile and mighty chunking toolbox Sentence Transformers are a widely use embeddings library that could provide text encoders Qdrant is an easy-to-set-up, highly performing and scalable vector database, that offers numerous functionalities (among which hybrid search and metadata filtering). What's even better? All these tools are open source!
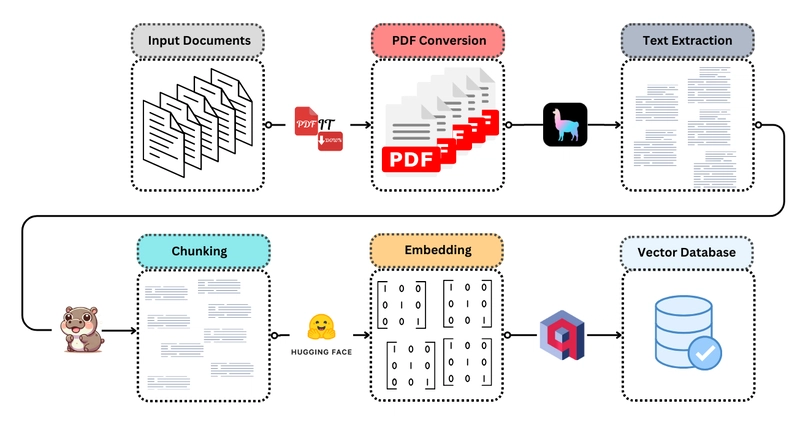
One of my areas of focus, recently, has been the development of a universal and zero-effort way of converting text-based documents (and even images) into PDF files, so that they could fit into my RAG pipelines, that are optimized for that format. In the end, after almost 30 "This is the last git commit", I came up with PdfItDown, a python package capable of transforming the most commonly used file formats into PDF, and it can do so with single or multiple files (and even entire folders!).
After that, tho, I wasn't satisfied: converting files to PDF is ok, but they're unplugged from the main ingest-into-DB pipeline, which might be still a lot of effort to design and optimize. Then it came the idea: why don't I create a standardized, simple and yet powerful, fully-automated procedure to go from a non-PDF file to vector data loaded into a database?
The tools were already there:
- PdfItDown can handle file transformation
- LlamaIndex has the readers to turn PDFs into text files
- Chonkie offers a versatile and mighty chunking toolbox
- Sentence Transformers are a widely use embeddings library that could provide text encoders
- Qdrant is an easy-to-set-up, highly performing and scalable vector database, that offers numerous functionalities (among which hybrid search and metadata filtering).
What's even better? All these tools are open source!