![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






















































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)



























































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)



























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)
































































































































LazyReview: NLP Dataset Exposes "Lazy Thinking" in Peer Reviews & LLM Detection
This is a Plain English Papers summary of a research paper called LazyReview: NLP Dataset Exposes "Lazy Thinking" in Peer Reviews & LLM Detection. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Addressing the Hidden Problem of "Lazy Thinking" in Scientific Peer Reviews Peer review serves as a cornerstone of quality control in scientific publishing. However, with the growing volume of submissions, reviewers often face overwhelming workloads that lead to the use of "quick heuristics" when evaluating papers. This practice, termed "lazy thinking," compromises review quality and hampers scientific progress. Lazy thinking in NLP peer reviews refers to dismissing research papers based on superficial heuristics rather than thorough analysis. These critiques typically lack substantial supporting evidence and often reflect prevailing trends within the NLP community rather than objective evaluation. Illustration of lazy thinking examples from ARR-22 reviews. The first segment shows a reviewer dismissing a paper without evidence, while the second shows language bias. The prevalence of this problem is significant—according to the ACL 2023 report, lazy thinking accounts for 24.3% of author-reported issues in peer reviews. To address this challenge, researchers from Technical University of Darmstadt and other institutions have introduced LazyReview, the first dataset specifically designed to detect lazy thinking in NLP peer reviews. LazyReview: The First Dataset for Detecting Lazy Thinking LazyReview consists of 500 expert-annotated and 1,276 silver-annotated review segments tagged with fine-grained lazy thinking categories. The dataset enables the development of automated tools to identify problematic heuristics in peer reviews. Heuristics Description Example review segments The results are not surprising Many findings seem obvious in rer- rospect, but this does not mean that the community is already aware of them and can use them as building blocks for future work. Transfer learning does not look to bring significant improvements. Looking at the variance, the results with and without transfer learning overlap. This is not surprising. The results are not novel Such broad claims need to be backed up with references. The approach the authors propose is still useful but not very novel. The paper has language errors As long as the writing is clear enough, better scientific content should be more valuable than better journalistic skills. The paper would be easy to fol- low with English proofreading even though the overall idea is under- standable. Descriptions for some of the lazy thinking classes sourced from ARR 2022 guidelines with examples from the dataset. Review Collection and Sampling The researchers used ARR 2022 reviews from the NLPeer Dataset, which includes 684 reviews from 476 papers with 11,245 sentences in total. They focused specifically on the "Summary of Weaknesses" sections, where lazy thinking patterns are most likely to appear. Extracting Review Segments with GPT-4 To prepare the dataset, the team employed GPT-4 to extract potential lazy thinking segments from reviews. This process yielded 1,776 review segments of varied lengths. The extraction accuracy was validated by human annotators (achieving Cohen's κ of 0.82), with high recall (1.00) but lower precision (0.74). To account for segments that weren't actually examples of lazy thinking, the researchers added a "None" class to their annotation schema. Developing a Rigorous Annotation Protocol The annotation process involved providing annotators with full reviews containing highlighted segments to classify according to the lazy thinking guidelines. Two PhD students experienced in NLP peer reviewing performed the initial annotations, with a senior PostDoc resolving disagreements. The annotators indicated their confidence levels (low, medium, high) for each classification decision and also had access to two additional classes: "None" for segments without lazy thinking, and "Not Enough Information" for cases lacking sufficient context for proper classification. This methodical approach to annotation is particularly important in the peer review domain, where detecting problematic content presents unique challenges due to its subjective nature. Iteratively Improving Annotation Guidelines The guidelines went through three rounds of refinement: Round 1: Using ARR 2022 guidelines (Cohen's κ of 0.31) Round 2: Extending with EMNLP 2020 guidelines (Cohen's κ of 0.38) Round 3: Adding positive examples (Cohen's κ of 0.52) The addition of positive examples proved especially effective in improving agreement. New annotators were recruited to validate the guidelines across each round, confirming the pattern of improvement with κ values of 0.32, 0.36, and 0.48 respectively. The annotation process required signifi

This is a Plain English Papers summary of a research paper called LazyReview: NLP Dataset Exposes "Lazy Thinking" in Peer Reviews & LLM Detection. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Addressing the Hidden Problem of "Lazy Thinking" in Scientific Peer Reviews
Peer review serves as a cornerstone of quality control in scientific publishing. However, with the growing volume of submissions, reviewers often face overwhelming workloads that lead to the use of "quick heuristics" when evaluating papers. This practice, termed "lazy thinking," compromises review quality and hampers scientific progress.
Lazy thinking in NLP peer reviews refers to dismissing research papers based on superficial heuristics rather than thorough analysis. These critiques typically lack substantial supporting evidence and often reflect prevailing trends within the NLP community rather than objective evaluation.
Illustration of lazy thinking examples from ARR-22 reviews. The first segment shows a reviewer dismissing a paper without evidence, while the second shows language bias.
The prevalence of this problem is significant—according to the ACL 2023 report, lazy thinking accounts for 24.3% of author-reported issues in peer reviews. To address this challenge, researchers from Technical University of Darmstadt and other institutions have introduced LazyReview, the first dataset specifically designed to detect lazy thinking in NLP peer reviews.
LazyReview: The First Dataset for Detecting Lazy Thinking
LazyReview consists of 500 expert-annotated and 1,276 silver-annotated review segments tagged with fine-grained lazy thinking categories. The dataset enables the development of automated tools to identify problematic heuristics in peer reviews.
| Heuristics | Description | Example review segments |
|---|---|---|
| The results are not surprising | Many findings seem obvious in rer- rospect, but this does not mean that the community is already aware of them and can use them as building blocks for future work. |
Transfer learning does not look to bring significant improvements. Looking at the variance, the results with and without transfer learning overlap. This is not surprising. |
| The results are not novel | Such broad claims need to be backed up with references. |
The approach the authors propose is still useful but not very novel. |
| The paper has language errors | As long as the writing is clear enough, better scientific content should be more valuable than better journalistic skills. |
The paper would be easy to fol- low with English proofreading even though the overall idea is under- standable. |
Descriptions for some of the lazy thinking classes sourced from ARR 2022 guidelines with examples from the dataset.
Review Collection and Sampling
The researchers used ARR 2022 reviews from the NLPeer Dataset, which includes 684 reviews from 476 papers with 11,245 sentences in total. They focused specifically on the "Summary of Weaknesses" sections, where lazy thinking patterns are most likely to appear.
Extracting Review Segments with GPT-4
To prepare the dataset, the team employed GPT-4 to extract potential lazy thinking segments from reviews. This process yielded 1,776 review segments of varied lengths. The extraction accuracy was validated by human annotators (achieving Cohen's κ of 0.82), with high recall (1.00) but lower precision (0.74). To account for segments that weren't actually examples of lazy thinking, the researchers added a "None" class to their annotation schema.
Developing a Rigorous Annotation Protocol
The annotation process involved providing annotators with full reviews containing highlighted segments to classify according to the lazy thinking guidelines. Two PhD students experienced in NLP peer reviewing performed the initial annotations, with a senior PostDoc resolving disagreements.
The annotators indicated their confidence levels (low, medium, high) for each classification decision and also had access to two additional classes: "None" for segments without lazy thinking, and "Not Enough Information" for cases lacking sufficient context for proper classification.
This methodical approach to annotation is particularly important in the peer review domain, where detecting problematic content presents unique challenges due to its subjective nature.
Iteratively Improving Annotation Guidelines
The guidelines went through three rounds of refinement:
- Round 1: Using ARR 2022 guidelines (Cohen's κ of 0.31)
- Round 2: Extending with EMNLP 2020 guidelines (Cohen's κ of 0.38)
- Round 3: Adding positive examples (Cohen's κ of 0.52)
The addition of positive examples proved especially effective in improving agreement. New annotators were recruited to validate the guidelines across each round, confirming the pattern of improvement with κ values of 0.32, 0.36, and 0.48 respectively.
The annotation process required significant expertise and time investment—approximately 20 hours total, with an average of 25 minutes per example.
Dataset Composition and Analysis
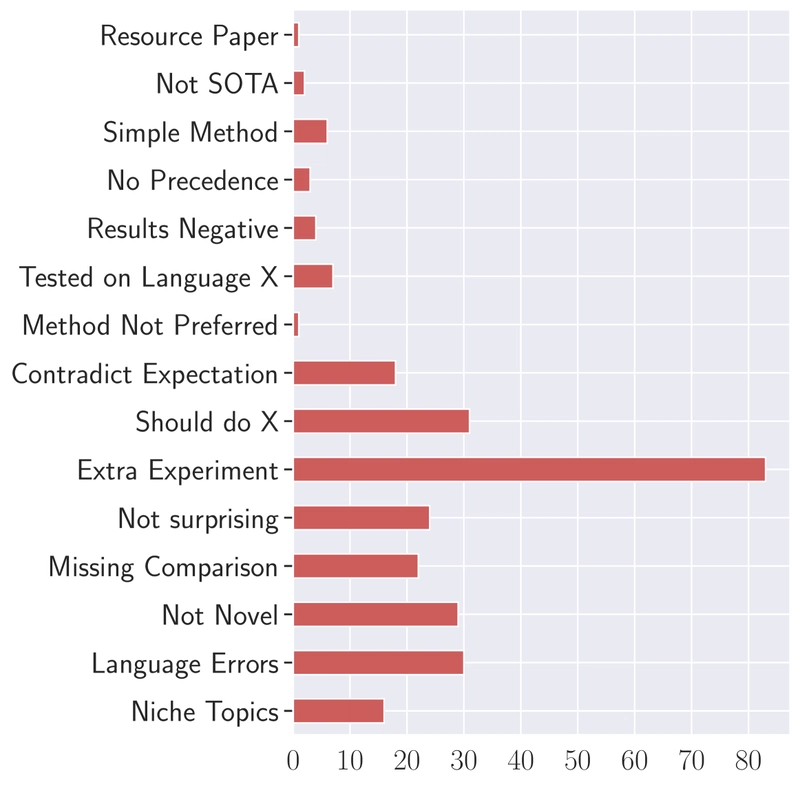
Distribution of lazy thinking classes in the LazyReview dataset, showing "Extra Experiments" as the most frequent type.
The dataset includes 16 specific lazy thinking classes plus "None" and "Not Enough Information." The most prevalent class is "Extra Experiments," where reviewers ask authors to conduct additional experiments without proper justification. This reflects the current emphasis on empirical evaluations in machine learning research.
Other common classes include "Not Enough Novelty" and "Language Errors." Notably, most review segments containing lazy thinking are just one sentence long, highlighting how brief arguments are often used to dismiss papers without adequate evidence or explanation.
Testing LLMs' Ability to Detect Lazy Thinking
The researchers conducted extensive experiments to evaluate how well Large Language Models (LLMs) could detect lazy thinking in peer reviews. They formulated two classification tasks:
- Coarse-grained classification: Determining if a review segment contains lazy thinking or not
- Fine-grained classification: Identifying the specific type of lazy thinking in a segment
Several open-source instruction-tuned LLMs were tested, including LLaMa-2 (7B and 13B), Mistral (7B), Qwen-Chat (7B), Yi-1.5 (6B), Gemma (7B), and SciTülu (7B). The models were evaluated using both strict string-matching and a more relaxed GPT-based semantic evaluation.
Impact of Improved Guidelines on Zero-Shot Performance
The research team tested whether improved annotation guidelines would enhance LLMs' zero-shot ability to detect lazy thinking.
| Models | Fine-gr. | Coarse-gr. | ||||||
|---|---|---|---|---|---|---|---|---|
| R1 | R2 | R1 | R2 | |||||
| S.A | G.A | S.A | G.A | S.A | G.A | S.A | G.A | |
| Random | 7.11 | - | 8.38 | - | 40.7 | - | 40.7 | - |
| MAIORITY | 11.1 | - | 7.34 | - | 51.4 | - | 51.4 | - |
| Gemma + T | 22.2 | 52.2 | 26.7 | 58.2 | 44.3 | 51.1 | 40.1 | 54.4 |
| Gemma + RT | 12.2 | 46.7 | 11.6 | 51.2 | 48.1 | 47.4 | 50.4 | 49.1 |
| LLaMa + T | 12.2 | 15.6 | 22.2 | 30.6 | 57.7 | 70.0 | 60.0 | 75.0 |
| LLaMa + RT | 12.2 | 25.6 | 13.2 | 53.5 | 53.3 | 55.1 | 60.0 | 67.5 |
| LLaMa ${ }_{n}$ + T | 26.7 | 44.4 | 26.7 | 45.3 | 60.2 | 73.1 | 62.2 | 75.4 |
| LLaMa ${ }_{n}$ + RT | 15.6 | 41.1 | 17.6 | 40.4 | 66.6 | 69.4 | 70.2 | 70.2 |
| Mistral + T | 27.8 | 47.8 | 28.8 | 51.3 | 57.8 | 64.8 | 58.8 | 66.3 |
| Mistral + RT | 12.2 | 28.9 | 16.6 | 35.9 | 55.4 | 53.8 | 57.4 | 56.0 |
| Qwen + T | 21.1 | 46.7 | 22.7 | 50.0 | 68.9 | 74.1 | 70.4 | 76.1 |
| Qwen + RT | 12.2 | 43.3 | 13.3 | 42.6 | 53.3 | 53.3 | 56.5 | 56.5 |
| Yi-1.5 + T | 35.3 | 56.7 | 37.6 | 60.0 | 44.4 | 71.1 | 68.7 | 73.4 |
| Yi-1.5 + RT | 34.4 | 51.1 | 32.8 | 52.2 | 63.3 | 65.1 | 68.3 | 70.4 |
| SciTúlu + T | 14.4 | 18.1 | 25.3 | 29.4 | 37.8 | 37.8 | 58.3 | 58.3 |
| SciTúlu + RT | 15.6 | 17.3 | 18.3 | 23.7 | 55.6 | 55.6 | 58.7 | 58.7 |
LLM performance across annotation rounds in terms of string-matching (S.A) and GPT-based (G.A) accuracy for fine-grained (Fine-gr.) and coarse-grained (Coarse-gr.) tasks. 'T' uses only the target sentence, 'RT' combines review and target. R1 and R2 represent 'Round 1' and 'Round 2'.
Results showed that all models improved from Round 1 to Round 2 with the enhanced guidelines. Interestingly, using only the target segment (T) generally outperformed using both the target segment and review (RT), possibly due to spurious correlations from longer inputs. Coarse-grained classification scores were consistently higher than fine-grained, showing that LLMs can detect the presence of lazy thinking more reliably than identifying its specific type.
Enhancing Detection with In-Context Learning
Building on previous findings, the researchers tested whether providing positive examples through in-context learning could improve LLMs' ability to detect lazy thinking. They compared static and dynamic methods for selecting examples, finding that randomly selected static examples performed best.
Results showed significant performance improvements across all models when using in-context examples. For coarse-grained classification, SciTülu achieved the highest string-based accuracy (88.8%), while Qwen led in fine-grained classification (31.1%).
This approach aligns with work on improving LLM-based review processes, demonstrating that strategic example selection can enhance model performance for specialized tasks in academic review.
Boosting Performance with Instruction Tuning
To further improve detection capabilities, the researchers applied instruction-based fine-tuning to the models. They tested various data mixes, including combinations with Tülu V2 and SciRIFF datasets.
Instruction tuning significantly enhanced model performance across the board, with improvements of 10-20 percentage points compared to zero-shot and few-shot approaches. Different models benefited from different data mixes: LLaMa models and SciTülu performed best with the SciRIFF Mix, while Gemma and Qwen excelled with the Tülu Mix.
The best-performing model (Qwen) was then used to generate silver annotations for the remaining 1,276 review segments in the dataset, achieving substantial agreement with human annotators (Cohen's κ of 0.56).
These findings are promising for enhancing LLM-based peer review systems, suggesting that specialized training can create more reliable automated tools for review quality assessment.
Improving Review Quality with Lazy Thinking Guidelines
In a controlled experiment, the researchers tested whether lazy thinking annotations could help improve review quality. Two groups of PhD students experienced in NLP peer reviewing were tasked with rewriting the same 50 reviews—one group used only the ARR guidelines, while the other also had access to lazy thinking annotations.
| Type | Constr. | Justi. | Adh. |
|---|---|---|---|
| Orig. vs lazy | 85/5/10 | 85/10/5 | 90/5/5 |
| Orig w. gdl vs lazy | 70/5/25 | 70/5/25 | 75/5/20 |
Pair-wise comparison of rewrites based on Win (W), Tie (T), and Loss (L) rates across metrics. The first row compares lazy thinking rewrites with original reviews, while the second compares lazy rewrites with guideline-based rewrites.
Reviews written with lazy thinking annotations significantly outperformed both original reviews and guideline-only rewrites across all quality measures. Lazy thinking-guided reviews showed win rates of 90% for adherence to guidelines and 85% for constructiveness and justification compared to original reviews.
When compared to guideline-based rewrites, the lazy thinking-guided reviews still maintained 75% win rates for adherence and 70% for constructiveness and justification. This demonstrates that explicit lazy thinking signals help reviewers provide more actionable, evidence-backed feedback.
These results support other studies showing that structured feedback can enhance review quality, with targeted guidelines producing more comprehensive and useful peer reviews.
Context and Implications
LazyReview addresses a significant gap in NLP research, as prior work focused primarily on rule-following behavior and review quality but not on the specific issue of heuristics in peer reviews. While Rogers and Augenstein (2020) qualitatively analyzed heuristics in NLP conferences, LazyReview is the first dedicated dataset for identifying such practices and developing automated detection methods.
The dataset and enhanced guidelines have several important applications:
- Training junior reviewers to avoid lazy thinking patterns
- Developing automated tools to flag potential issues in reviews
- Improving overall review quality through more thoughtful, constructive feedback
By addressing lazy thinking in peer reviews, LazyReview aims to enhance the effectiveness of the peer review process in NLP and potentially other scientific fields.
Limitations and Future Work
The researchers acknowledge several limitations of their work:
- The definition and categories of lazy thinking are specific to NLP conference reviews and may not generalize to other domains
- The dataset focuses only on the weakness section of reviews, though lazy thinking may appear elsewhere
- The reviews predate the widespread adoption of large language models (pre-2023), and the impact of AI-generated reviews remains unexplored
Future research could explore how lazy thinking patterns manifest in other parts of reviews, extend the approach to different academic disciplines, and investigate the effects of AI-generated content on peer review quality.
Despite these limitations, LazyReview represents a significant step toward improving peer review quality through automated detection of problematic evaluation patterns. By combining expert annotation with advanced language models, this work provides both practical tools and theoretical insights for enhancing scientific communication.