











































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)

















































































































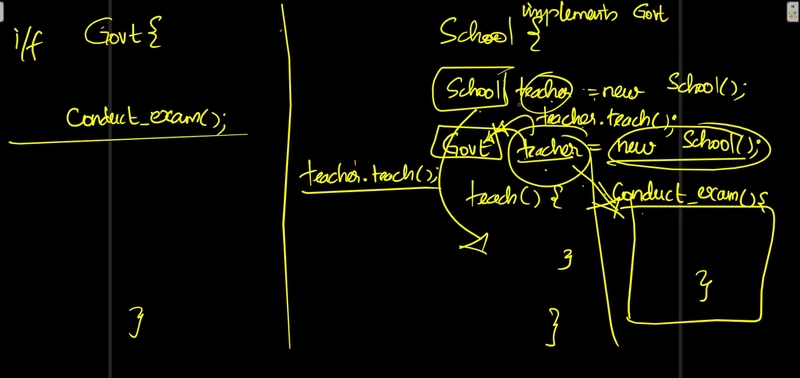



































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)



























































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)













![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)
































































































































ColorBench: New Test Reveals How AI Sees Color. Surprising Results!
This is a Plain English Papers summary of a research paper called ColorBench: New Test Reveals How AI Sees Color. Surprising Results!. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter. Introduction: Why Color Understanding Matters for AI Vision Systems Color plays a fundamental role in human perception, providing crucial information for object detection, scene interpretation, and contextual understanding. For vision-language models (VLMs) deployed in real-world applications like scientific discovery, medical care, and remote sensing, the ability to process color information is essential. For example, researchers leverage spectral color signatures to distinguish vegetation in satellite imagery and use sediment color patterns to detect marine ecosystems. Despite the importance of color perception, existing VLM benchmarks tend to focus on tasks that don't heavily rely on color understanding. This creates a significant gap in evaluating whether VLMs can perceive and reason about color with human-like proficiency and how their performance changes under color variations. Evaluation of VLMs on ColorBench showing accuracy of 8 representative VLMs on 11 tasks across three categories (Perception, Reasoning, and Robustness). ColorBench: A Comprehensive Benchmark for Color Understanding ColorBench addresses this gap with a comprehensive evaluation framework focused on three core capabilities: Color Perception: Testing how well VLMs can recognize colors and identify color properties Color Reasoning: Assessing how models use color information in more complex reasoning tasks Color Robustness: Measuring performance stability under color transformations The benchmark comprises 11 diverse tasks with over 1,400 instances drawn from real-world applications including painting analysis, test kit readings, shopping, and satellite/wildlife image analysis. Test samples from COLORBENCH. The benchmark evaluates VLMs across three core capabilities: Perception, Reasoning and Robustness. The benchmark comprises 11 tasks designed to assess fine-grained color understanding abilities and the effect of color on other reasoning skills, including counting, proportion calculation, and robustness estimation. ColorBench's tasks include: Task # Sample Case Description Sample Questions Color Recognition 76 Figure 8 Ask for the color of a specific object or determine if a particular color is present in the image. What is the color of object in this image? What color does not exist in this image? Color Extraction 96 Figure 9 Extract the color code value (e.g., RGB, HSV, or HEX) from a single color in the image. What is the HSV value of the given color in the image? What is the RGB value of the given color in the image? Object Recognition 77 Figure 10 Identify objects in the image that match a specified color noted in the text input. What object has a color of pink in this image? Color Proportion 80 Figure 11 Estimate the relative area occupied by a specified color in the image. What is the dominant color in this image? What is the closest to the proportion of the red color in the image? Color Comparison 101 Figure 12 Distinguish among multiple colors present in the image to assess overall tones and shades. Which photo is warmer in overall color? Which object has a darker color in the image? Color Counting 102 Figure 13 Identify the number of unique colors present in the image. How many different colors are in this image? Object Counting 103 Figure 14 Count the number of objects of a specified color present in the image. How many objects with green color are in this image? Color Illusion 93 Figure 15 Assess and compare colors in potential illusionary settings within the image. Do two objects have the same color? Color Mimicry 70 Figure 16 Detect objects that are camouflaged within their surroundings, where color is a key deceptive element. How many animals are in this image? Color Blindness 157 Figure 17 Recognize numbers or text that are embedded in color patterns, often used in tests for color vision. What is the number in the center of the image? Detailed descriptions of all 11 tasks with sample questions in ColorBench. Evaluation Framework: Testing VLMs' Color Capabilities The researchers evaluated 32 VLMs of varying sizes and architectures, from small models (

This is a Plain English Papers summary of a research paper called ColorBench: New Test Reveals How AI Sees Color. Surprising Results!. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Introduction: Why Color Understanding Matters for AI Vision Systems
Color plays a fundamental role in human perception, providing crucial information for object detection, scene interpretation, and contextual understanding. For vision-language models (VLMs) deployed in real-world applications like scientific discovery, medical care, and remote sensing, the ability to process color information is essential. For example, researchers leverage spectral color signatures to distinguish vegetation in satellite imagery and use sediment color patterns to detect marine ecosystems.
Despite the importance of color perception, existing VLM benchmarks tend to focus on tasks that don't heavily rely on color understanding. This creates a significant gap in evaluating whether VLMs can perceive and reason about color with human-like proficiency and how their performance changes under color variations.
Evaluation of VLMs on ColorBench showing accuracy of 8 representative VLMs on 11 tasks across three categories (Perception, Reasoning, and Robustness).
ColorBench: A Comprehensive Benchmark for Color Understanding
ColorBench addresses this gap with a comprehensive evaluation framework focused on three core capabilities:
- Color Perception: Testing how well VLMs can recognize colors and identify color properties
- Color Reasoning: Assessing how models use color information in more complex reasoning tasks
- Color Robustness: Measuring performance stability under color transformations
The benchmark comprises 11 diverse tasks with over 1,400 instances drawn from real-world applications including painting analysis, test kit readings, shopping, and satellite/wildlife image analysis.

Test samples from COLORBENCH. The benchmark evaluates VLMs across three core capabilities: Perception, Reasoning and Robustness. The benchmark comprises 11 tasks designed to assess fine-grained color understanding abilities and the effect of color on other reasoning skills, including counting, proportion calculation, and robustness estimation.
ColorBench's tasks include:
| Task | # | Sample Case | Description | Sample Questions |
|---|---|---|---|---|
| Color Recognition | 76 | Figure 8 | Ask for the color of a specific object or determine if a particular color is present in the image. | What is the color of object in this image? What color does not exist in this image? |
| Color Extraction | 96 | Figure 9 | Extract the color code value (e.g., RGB, HSV, or HEX) from a single color in the image. | What is the HSV value of the given color in the image? What is the RGB value of the given color in the image? |
| Object Recognition | 77 | Figure 10 | Identify objects in the image that match a specified color noted in the text input. | What object has a color of pink in this image? |
| Color Proportion | 80 | Figure 11 | Estimate the relative area occupied by a specified color in the image. | What is the dominant color in this image? What is the closest to the proportion of the red color in the image? |
| Color Comparison | 101 | Figure 12 | Distinguish among multiple colors present in the image to assess overall tones and shades. | Which photo is warmer in overall color? Which object has a darker color in the image? |
| Color Counting | 102 | Figure 13 | Identify the number of unique colors present in the image. | How many different colors are in this image? |
| Object Counting | 103 | Figure 14 | Count the number of objects of a specified color present in the image. | How many objects with green color are in this image? |
| Color Illusion | 93 | Figure 15 | Assess and compare colors in potential illusionary settings within the image. | Do two objects have the same color? |
| Color Mimicry | 70 | Figure 16 | Detect objects that are camouflaged within their surroundings, where color is a key deceptive element. | How many animals are in this image? |
| Color Blindness | 157 | Figure 17 | Recognize numbers or text that are embedded in color patterns, often used in tests for color vision. | What is the number in the center of the image? |
Detailed descriptions of all 11 tasks with sample questions in ColorBench.
Evaluation Framework: Testing VLMs' Color Capabilities
The researchers evaluated 32 VLMs of varying sizes and architectures, from small models (<7B parameters) to large proprietary models like GPT-4o and Gemini-2. For color robustness testing, they implemented multiple color transformation strategies:
| Strategy | Editing Region | Purpose |
|---|---|---|
| Entire Image | Whole image | Assesses the model's robustness to global color shifts |
| Target Segment | Segment containing the object referenced in the question |
Evaluates the model's sensitivity to task-relevant color changes |
| Largest Segment | The largest segment that is irrelevant to the question |
Tests whether changes in dominant but unrelated regions affect model predictions |
Color editing strategies used to test robustness in ColorBench.
The data for ColorBench comes from diverse sources, ensuring comprehensive coverage:
| Category | Data Source |
|---|---|
| C'Recognition | Website, ICAA17K [15] |
| C'Recognition | Website, ICAA17K [15] |
| C'Extraction | Synthetic Data |
| C'Proportion | Website, Synthetic Data |
| C'Comparison | Website |
| C'Counting | Website, Synthetic Data |
| C'Ounting | Website, ADA20K [49, 50], COCO2017 [29] |
| C'Mimicry | Website, IllusionVQA[39], RCID[32] |
| C'Blindness | Synthetic Data |
| C'Robust | CV-Bench[41] |
Data sources used for creating ColorBench tasks.
Experimental Results: How Well Can VLMs Understand Colors?
The comprehensive evaluation revealed several key findings about VLMs' color understanding capabilities. The performance across all 32 models shows interesting patterns:
| Color Perception | Color Reasoning | P & R | Color Robustness | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C'Recog | C'Extract | O'Recog | C'Prop | C'Comp | C'Count | O'Count | C'llu | C'Mimic | C'Blind | Overall | C'Robust | |
| VLMv: $<7B$ | ||||||||||||
| LLaVA-OV-0.5B | 26.3 | 44.8 | 46.8 | 30.0 | 23.8 | 22.6 | 21.4 | 38.7 | 58.6 | 26.8 | 32.6 | 38.7 |
| InternVL2-1B | 35.5 | 34.4 | 59.7 | 23.8 | 41.6 | 19.6 | 22.3 | 34.4 | 38.6 | 33.1 | 33.6 | 39.4 |
| InternVL2.5-1B | 55.3 | 36.5 | 61.0 | 42.5 | 45.5 | 22.6 | 25.2 | 43.0 | 41.4 | 28.0 | 38.3 | 52.3 |
| InternVL2-2B | 60.5 | 36.5 | 66.2 | 40.0 | 38.6 | 19.6 | 29.1 | 26.9 | 52.9 | 21.0 | 36.4 | 54.2 |
| InternVL2.5-2B | 69.7 | 28.1 | 71.4 | 33.8 | 48.5 | 25.5 | 30.1 | 32.3 | 55.7 | 19.8 | 38.5 | 59.8 |
| Qwen2.5-VL-3B | 72.4 | 38.5 | 74.0 | 43.8 | 48.5 | 22.6 | 25.2 | 43.0 | 45.7 | 24.2 | 41.1 | 63.7 |
| Cambrian-3B | 67.1 | 31.3 | 66.2 | 47.5 | 50.5 | 25.5 | 29.1 | 44.1 | 61.4 | 22.3 | 41.5 | 59.0 |
| VLMv: $7B-8B$ | ||||||||||||
| LLaVA-Next-v-7B | 29.0 | 38.5 | 57.1 | 21.3 | 34.7 | 23.5 | 25.2 | 38.7 | 41.4 | 17.8 | 31.2 | 52.1 |
| LLaVA-Next-m-7B | 21.1 | 18.8 | 63.6 | 27.5 | 42.6 | 16.7 | 34.0 | 41.9 | 47.1 | 29.9 | 33.4 | 55.2 |
| Eagle-X5-7B | 52.6 | 47.9 | 67.5 | 41.3 | 42.6 | 20.6 | 35.0 | 44.1 | 48.6 | 22.9 | 40.0 | 48.5 |
| LLaVA-OV-7B | 71.1 | 53.1 | 81.8 | 52.5 | 53.5 | 19.6 | 26.2 | 48.4 | 48.6 | 23.6 | 44.7 | 74.0 |
| Qwen2.5-VL-7B | 76.3 | 49.0 | 84.4 | 47.5 | 52.5 | 19.6 | 34.0 | 44.1 | 55.7 | 28.7 | 46.2 | 74.4 |
| Cambrian-8B | 72.4 | 28.1 | 72.7 | 48.8 | 54.5 | 31.4 | 33.0 | 41.9 | 57.1 | 17.2 | 42.3 | 64.9 |
| InternVL2-8B | 72.4 | 50.0 | 77.9 | 42.5 | 48.5 | 20.6 | 35.9 | 38.7 | 50.0 | 23.6 | 43.1 | 65.5 |
| Eagle-X4-8B | 71.1 | 47.9 | 68.8 | 45.0 | 50.5 | 26.5 | 37.9 | 40.9 | 48.6 | 27.4 | 44.1 | 63.7 |
| InternVL2.5-8B | 77.6 | 47.9 | 83.1 | 50.0 | 62.4 | 25.5 | 33.0 | 34.4 | 52.9 | 19.8 | 45.2 | 69.8 |
| VLMv: $10B-30B$ | ||||||||||||
| LLaVA-Next-13B | 56.6 | 31.3 | 71.4 | 27.5 | 41.6 | 27.5 | 28.2 | 29.0 | 45.7 | 25.5 | 36.4 | 53.3 |
| Cambrian-13B | 67.1 | 34.4 | 74.0 | 46.3 | 47.5 | 32.4 | 35.0 | 38.7 | 55.7 | 24.8 | 42.8 | 64.7 |
| Eagle-X4-13B | 73.7 | 43.8 | 76.6 | 43.8 | 47.5 | 23.5 | 38.8 | 34.4 | 57.1 | 26.1 | 43.7 | 66.3 |
| InternVL2-26B | 72.4 | 52.1 | 87.0 | 52.5 | 56.4 | 20.6 | 35.0 | 34.4 | 55.7 | 27.4 | 46.3 | 74.0 |
| InternVL2.5-26B | 72.4 | 45.8 | 89.6 | 45.0 | 63.4 | 22.6 | 35.0 | 32.3 | 62.9 | 29.3 | 46.8 | 83.0 |
| VLMv: $30B-70B$ | ||||||||||||
| Eagle-X5-34B | 79.0 | 27.1 | 80.5 | 48.8 | 48.5 | 23.5 | 35.9 | 37.6 | 60.0 | 25.5 | 43.4 | 67.1 |
| Cambrian-34b | 75.0 | 57.3 | 77.9 | 50.0 | 46.5 | 22.6 | 32.0 | 37.6 | 64.3 | 24.2 | 45.3 | 67.7 |
| LLaVA-Next-34b | 69.7 | 46.9 | 76.6 | 43.8 | 56.4 | 28.4 | 41.8 | 36.6 | 61.4 | 29.9 | 46.6 | 65.9 |
| InternVL2.5-38B | 71.1 | 60.4 | 89.6 | 53.8 | 63.4 | 29.4 | 40.8 | 34.4 | 61.4 | 26.8 | 50.0 | 84.6 |
| InternVL2-40B | 72.4 | 52.1 | 83.1 | 51.3 | 61.4 | 19.6 | 35.9 | 34.4 | 58.6 | 21.0 | 45.6 | 78.7 |
| VLMv: $>70B$ | ||||||||||||
| LLaVA-Next-72B | 72.4 | 54.2 | 79.2 | 41.3 | 49.5 | 24.5 | 35.9 | 33.3 | 48.6 | 34.4 | 45.2 | 66.5 |
| LLaVA-OV-72B | 73.7 | 63.5 | 83.1 | 52.5 | 69.3 | 27.5 | 50.5 | 36.6 | 55.7 | 31.9 | 51.9 | 79.5 |
| InternVL2-76B | 72.4 | 42.7 | 85.7 | 45.0 | 62.4 | 27.5 | 35.0 | 31.2 | 50.0 | 23.6 | 44.6 | 65.7 |
| InternVL2.5-78B | 75.0 | 58.3 | 81.8 | 43.8 | 68.3 | 27.5 | 36.9 | 34.4 | 61.4 | 28.7 | 48.8 | 84.2 |
| VLMv: Proprietary | ||||||||||||
| GPT-4o | 73.7 | 29.2 | 84.4 | 51.3 | 64.4 | 28.4 | 30.1 | 54.8 | 70.0 | 56.7 | 52.8 | 46.2 |
| Gemini-2-flush | 80.3 | 31.3 | 83.1 | 46.3 | 74.3 | 33.3 | 36.9 | 43.0 | 74.3 | 53.0 | 53.9 | 70.7 |
| GPT-4o (CoT) | 76.3 | 36.5 | 85.7 | 51.3 | 73.3 | 27.5 | 35.9 | 46.2 | 74.3 | 65.6 | 56.2 | 69.9 |
| Gemini-2-flush (CoT) | 79.0 | 42.7 | 83.1 | 55.0 | 76.2 | 45.1 | 41.8 | 43.0 | 74.3 | 54.1 | 57.8 | 73.6 |
Detailed performance metrics for all 32 models across all tasks.
The best performers in each model size category show a general trend of improvement with scale:
| Color P & R Overall | Color Robustness | |||
|---|---|---|---|---|
| Model Size | Model | Best | Model | Best |
| $<7 \mathrm{~B}$ | Cambrian-3B | 41.5 | Qwen2.5-VL-3B | 63.7 |
| $7 \mathrm{~B}-8 \mathrm{~B}$ | Qwen2.5-VL-7B | 46.2 | Qwen2.5-VL-7B | 74.4 |
| $10 \mathrm{~B}-30 \mathrm{~B}$ | InternVL2.5-26B | 46.8 | nternVL2.5-26B | 83.0 |
| $30 \mathrm{~B}-50 \mathrm{~B}$ | InternVL2.5-38B | 50.0 | InternVL2.5-38B | 84.6 |
| $>70 \mathrm{~B}$ | Llava-ov-72B | 51.9 | InternVL2.5-78B | 84.2 |
| Proprietary | Gemini-2 | 53.9 | Gemini-2 | 70.7 |
| Proprietary | Gemini-2 (CoT) | 57.8 | Gemini-2 (CoT) | 73.6 |
Best-performing models in each size category for overall perception & reasoning and for robustness.
Analysis and Findings: Key Discoveries About VLMs' Color Understanding
The research revealed several key findings about VLMs' color understanding capabilities:
Scaling law holds, but with small improvements: Larger models generally perform better, but the performance gains are smaller than expected, suggesting color understanding has been relatively neglected in VLM development.
Language models matter more than vision encoders: The analysis shows stronger correlation between language model size and color understanding performance than vision encoder size:
| Color Perception | Color Reasoning | P & R | Color Robustness | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C'Recog | C'Extract | O'Recog | C'Prop | C'Comp | C'Count | O'Count | C'Illu | C'Mimic | C'Blind | Overall | C'Robust | ||
| $\mathbf{L + V}$ | 0.5657 (*) | 0.5255 (*) | 0.7107 (*) | 0.5125 (*) | 0.6358 (*) | 0.4316 (*) | 0.7566 (*) | $-0.3460$ | 0.4832 (*) | 0.2460 | 0.7619 (*) | 0.7226 (*) | |
| $\mathbf{L}$ | 0.5724 (*) | 0.4937 (*) | 0.6769 (*) | 0.4696 (*) | 0.6118 (*) | 0.4408 (*) | 0.7611 (*) | $-0.3697(*)$ | 0.4559 (*) | 0.2824 | 0.7436 (*) | 0.7026 (*) | |
| $\mathbf{V}$ | 0.3955 (*) | 0.2856 | 0.5465 (*) | 0.6242 (*) | 0.5295 (*) | 0.2089 | 0.3608 | $-0.0127$ | 0.6024 (*) | $-0.0679$ | 0.5271 (*) | 0.5320 (*) |
Correlation analysis between model components (L: language model, V: vision encoder) and performance.
- Chain-of-Thought (CoT) reasoning improves performance: Despite being vision-centric tasks, color understanding benefits from explicit reasoning, especially for robustness:
| Color Perception | Color Reasoning | P & R | Color Robustness | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| C'Recog | C'Extruct | O'Recog | C'Prop | C'Comp | C'Count | O'Count | C'Illu | C'Mimic | C'Blind | Overall | |
| GPT-4o $\Delta$ | $+2.6$ | $+7.3$ | $+1.3$ | 0.0 | $+8.9$ | $-0.9$ | $+5.8$ | $-8.6$ | $+4.3$ | $+8.9$ | $+3.4$ |
| Gemini-2 $\Delta$ | $-1.3$ | $+11.4$ | 0.0 | $+8.7$ | $+1.9$ | $+11.8$ | $+4.9$ | 0.0 | 0.0 | $+1.1$ | $+3.9$ |
| Average $\Delta$ | $+0.65$ | $+9.35$ | $+0.65$ | $+4.35$ | $+5.4$ | $+5.45$ | $+5.35$ | $-4.3$ | $+2.15$ | $+5.0$ | $+3.65$ |
Performance improvements with Chain-of-Thought reasoning.
Color cues can both help and mislead: VLMs demonstrated they can leverage color information, but color can also lead to incorrect conclusions in certain tasks, particularly with color illusions.
Lack of specialization for color tasks: The relatively small performance gaps between models suggest that color understanding has been largely overlooked during VLM development.
Related Work: Contextualizing ColorBench in VLM Research
ColorBench builds upon previous work in VLM evaluation, color perception research, and robustness testing. Traditional VLM benchmarks like VQA and COCO typically include color-related questions but don't systematically test color understanding as a primary focus. Previous research on color perception in computer vision has focused on color constancy, color transfer, and color spaces, but these studies haven't been comprehensively applied to evaluating modern VLMs.
Robustness studies in vision models have examined various perturbations, but few have specifically focused on color transformations in the context of VLMs. ColorBench fills this gap by providing a systematic framework for evaluating color perception, reasoning, and robustness.
Conclusion: Advancing Color Understanding in AI Vision Systems
ColorBench reveals important insights about the state of color understanding in current VLMs. While larger models generally perform better, the modest performance improvements suggest that color understanding has been neglected in VLM development. The stronger correlation with language model size rather than vision encoder size indicates that improved textual reasoning about visual content may be more important than visual feature extraction alone.
The finding that Chain-of-Thought reasoning improves performance, especially in robustness tests, suggests that explicit reasoning processes help models better leverage color information. Meanwhile, the observation that color cues can both help and mislead VLMs highlights the need for more nuanced training approaches.
ColorBench provides a foundation for future research into human-level color understanding in AI systems. By systematically evaluating color perception, reasoning, and robustness, it offers insights for developing more color-aware VLMs that can better serve applications in fields like healthcare, remote sensing, and visual arts where color information is crucial.


