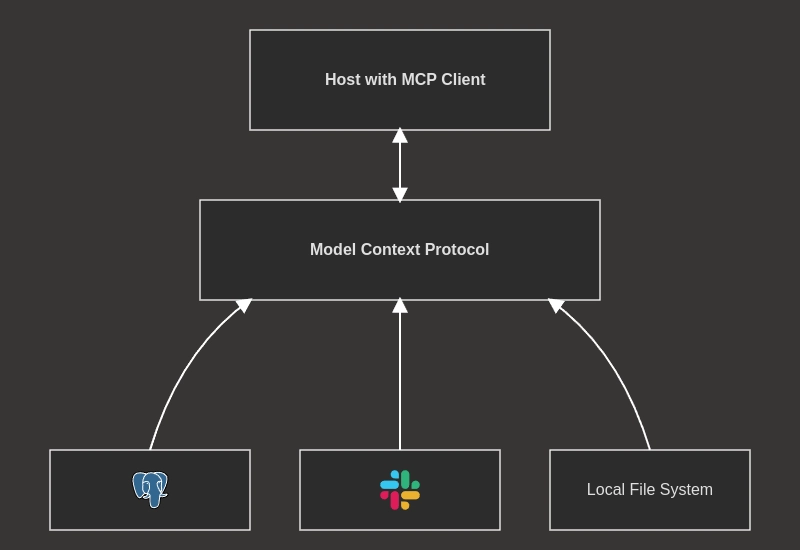
![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)

































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)






































































































(1).jpg?#)




















![Apple to Split iPhone Launches Across Fall and Spring in Major Shakeup [Report]](https://www.iclarified.com/images/news/97211/97211/97211-640.jpg)
![Apple to Move Camera to Top Left, Hide Face ID Under Display in iPhone 18 Pro Redesign [Report]](https://www.iclarified.com/images/news/97212/97212/97212-640.jpg)











_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)








































































































![Apple Developing Battery Case for iPhone 17 Air Amid Battery Life Concerns [Report]](https://www.iclarified.com/images/news/97208/97208/97208-640.jpg)
![AirPods 4 On Sale for $99 [Lowest Price Ever]](https://www.iclarified.com/images/news/97206/97206/97206-640.jpg)































































































Introduction to Data Engineering Concepts |10| Data Quality and Validation
Free Resources Free Apache Iceberg Course Free Copy of “Apache Iceberg: The Definitive Guide” Free Copy of “Apache Polaris: The Definitive Guide” 2025 Apache Iceberg Architecture Guide How to Join the Iceberg Community Iceberg Lakehouse Engineering Video Playlist Ultimate Apache Iceberg Resource Guide In any data system, quality is not optional—it’s foundational. No matter how scalable your architecture is, or how fast your queries run, if the underlying data is inaccurate, incomplete, or inconsistent, the results will be misleading. And bad data leads to bad decisions. This post focuses on data quality and validation. We'll look at what makes data "good," why quality issues emerge, and how engineers can build checks and balances into pipelines to ensure the reliability of their datasets. Defining Data Quality At its core, data quality is about trust. Can the data be used confidently for reporting, analytics, or decision-making? While quality is a broad concept, it typically includes several dimensions: Accuracy: Does the data reflect reality? For example, does a customer record show the correct name and email? Completeness: Are all required fields populated? Missing data can render entire records useless. Consistency: Is the data uniform across systems? If two systems say different things about the same event, which one is right? Timeliness: Is the data fresh enough for its intended purpose? A report showing yesterday’s numbers might be fine—or it might be too late. Uniqueness: Are there duplicate records that shouldn’t exist? These attributes form the foundation of what we think of as “high-quality” data. But quality isn't static—it needs to be monitored continuously. Where Data Quality Breaks Down Quality issues usually arise at system boundaries. When data moves from one source to another—say, from a transactional database to a warehouse or from an API to a data lake—transformations, encoding issues, and format mismatches can cause subtle errors. Sometimes data is flawed at the source. A user enters a malformed email address, or a sensor transmits faulty readings due to hardware glitches. Other times, issues emerge downstream, such as when a pipeline fails silently or when schema changes aren’t communicated across teams. Even well-designed systems can encounter quality problems if the underlying business logic evolves. For example, a rule that defines how revenue is calculated may change, invalidating previous calculations if pipelines aren’t updated accordingly. The Role of Validation To combat these issues, validation is key. Validation is the act of checking data against expected rules and assumptions—often before it gets loaded into a final destination. This can happen at multiple stages of a pipeline. During ingestion, validation might confirm that all required fields are present and formatted correctly. During transformation, it might enforce business rules, such as ensuring that order totals are positive or that timestamps are within reasonable ranges. Validation can be passive—logging anomalies for review—or active, stopping a pipeline if thresholds are exceeded. Both approaches have their place. In some cases, it's better to allow partial data to flow through and alert the team. In others, it’s critical to block the update to prevent contamination of production datasets. Tools for Data Quality Several tools and frameworks have emerged to help engineers define, monitor, and enforce data quality checks. Great Expectations is one of the most well-known. It allows you to define “expectations” about your data—essentially, assertions about what should be true. These expectations can be validated at runtime, and the results can be logged, visualized, or used to trigger alerts. Another option is Amazon Deequ, a library built on top of Apache Spark that performs similar validations at scale. It’s particularly useful in large distributed environments where running manual checks would be too costly. Some orchestration platforms, like Airflow and Dagster, support custom sensors or hooks that let you embed validation logic directly into the DAG. This tight integration makes it easier to halt jobs or notify teams when something goes wrong. Beyond tools, quality also depends on process. Data contracts, code reviews, and automated testing all contribute to building a culture where quality is prioritized from the start, not added as an afterthought. Designing for Trust A key principle in data engineering is that quality doesn't just happen—it must be designed. That means proactively defining what “correct” looks like, instrumenting checks, and making sure failures are surfaced early. Dashboards and data catalogs can help surface issues. But even more important is visibility: stakeholders need to know when data is delayed, incomplete, or incorrect. Setting up alerts based on data quality metrics helps teams

Free Resources
- Free Apache Iceberg Course
- Free Copy of “Apache Iceberg: The Definitive Guide”
- Free Copy of “Apache Polaris: The Definitive Guide”
- 2025 Apache Iceberg Architecture Guide
- How to Join the Iceberg Community
- Iceberg Lakehouse Engineering Video Playlist
- Ultimate Apache Iceberg Resource Guide
In any data system, quality is not optional—it’s foundational. No matter how scalable your architecture is, or how fast your queries run, if the underlying data is inaccurate, incomplete, or inconsistent, the results will be misleading. And bad data leads to bad decisions.
This post focuses on data quality and validation. We'll look at what makes data "good," why quality issues emerge, and how engineers can build checks and balances into pipelines to ensure the reliability of their datasets.
Defining Data Quality
At its core, data quality is about trust. Can the data be used confidently for reporting, analytics, or decision-making? While quality is a broad concept, it typically includes several dimensions:
- Accuracy: Does the data reflect reality? For example, does a customer record show the correct name and email?
- Completeness: Are all required fields populated? Missing data can render entire records useless.
- Consistency: Is the data uniform across systems? If two systems say different things about the same event, which one is right?
- Timeliness: Is the data fresh enough for its intended purpose? A report showing yesterday’s numbers might be fine—or it might be too late.
- Uniqueness: Are there duplicate records that shouldn’t exist?
These attributes form the foundation of what we think of as “high-quality” data. But quality isn't static—it needs to be monitored continuously.
Where Data Quality Breaks Down
Quality issues usually arise at system boundaries. When data moves from one source to another—say, from a transactional database to a warehouse or from an API to a data lake—transformations, encoding issues, and format mismatches can cause subtle errors.
Sometimes data is flawed at the source. A user enters a malformed email address, or a sensor transmits faulty readings due to hardware glitches. Other times, issues emerge downstream, such as when a pipeline fails silently or when schema changes aren’t communicated across teams.
Even well-designed systems can encounter quality problems if the underlying business logic evolves. For example, a rule that defines how revenue is calculated may change, invalidating previous calculations if pipelines aren’t updated accordingly.
The Role of Validation
To combat these issues, validation is key. Validation is the act of checking data against expected rules and assumptions—often before it gets loaded into a final destination.
This can happen at multiple stages of a pipeline. During ingestion, validation might confirm that all required fields are present and formatted correctly. During transformation, it might enforce business rules, such as ensuring that order totals are positive or that timestamps are within reasonable ranges.
Validation can be passive—logging anomalies for review—or active, stopping a pipeline if thresholds are exceeded. Both approaches have their place. In some cases, it's better to allow partial data to flow through and alert the team. In others, it’s critical to block the update to prevent contamination of production datasets.
Tools for Data Quality
Several tools and frameworks have emerged to help engineers define, monitor, and enforce data quality checks.
Great Expectations is one of the most well-known. It allows you to define “expectations” about your data—essentially, assertions about what should be true. These expectations can be validated at runtime, and the results can be logged, visualized, or used to trigger alerts.
Another option is Amazon Deequ, a library built on top of Apache Spark that performs similar validations at scale. It’s particularly useful in large distributed environments where running manual checks would be too costly.
Some orchestration platforms, like Airflow and Dagster, support custom sensors or hooks that let you embed validation logic directly into the DAG. This tight integration makes it easier to halt jobs or notify teams when something goes wrong.
Beyond tools, quality also depends on process. Data contracts, code reviews, and automated testing all contribute to building a culture where quality is prioritized from the start, not added as an afterthought.
Designing for Trust
A key principle in data engineering is that quality doesn't just happen—it must be designed. That means proactively defining what “correct” looks like, instrumenting checks, and making sure failures are surfaced early.
Dashboards and data catalogs can help surface issues. But even more important is visibility: stakeholders need to know when data is delayed, incomplete, or incorrect. Setting up alerts based on data quality metrics helps teams respond quickly before problems reach downstream consumers.
The cost of low-quality data isn't just technical—it's strategic. If users lose faith in the data, they stop relying on it. And once trust is gone, it’s incredibly hard to rebuild.
In the next post, we’ll examine how metadata, lineage, and governance play a role in maintaining data integrity across complex systems. Knowing where your data came from and how it was transformed is just as important as validating its contents.