










































































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)









































































































































































































































.jpg?#)





































































































































![Apple to Shift Robotics Unit From AI Division to Hardware Engineering [Report]](https://www.iclarified.com/images/news/97128/97128/97128-640.jpg)

![Apple Shares New Ad for iPhone 16: 'Trust Issues' [Video]](https://www.iclarified.com/images/news/97125/97125/97125-640.jpg)






























































































































Introducing ScrubPy: Intelligent Data Cleaning Tool (with new LLM features in progress)
Github Repo I’ve been building a CLI tool called ScrubPy to make data cleaning less of a pain. It’s a terminal-based utility that lets you profile your dataset, handle missing values and duplicates, fix column names, remove outliers, etc. You can preview all changes before applying, and it even exports clean EDA reports with visualizations. Some of the main features: Dataset profiling (nulls, duplicates, outliers, stats) One-click cleaning for common issues Standardize columns and convert types safely Smart EDA PDF export Undo support for every operation A Snapshot of the CLI Tool *A SnapShot of the DataProfiling tool in Action * Right now I’m working on a new phase (branch: phase-3) where I’m adding LLM support using Mistral via Ollama. The idea is to let users “talk to their dataset” — so you can ask it questions like: What’s wrong with my data? How should I clean this column? Can you suggest cleaning steps? A small version of this is working. It analyzes column roles, samples a few rows, and asks the LLM for cleaning suggestions. But obviously, I can’t pass the full dataset (token limits + performance), so I’m still figuring out the best way to give the LLM just enough context. Still unsure what the most useful features would be from a user perspective. Would love feedback or ideas: What kind of LLM-powered suggestions would actually help during data prep? Is there a better way to summarize dataset structure for an LLM? Should I focus more on natural language → code translation? Appreciate any thoughts. Happy to share the repo soon too once this phase is more stable.
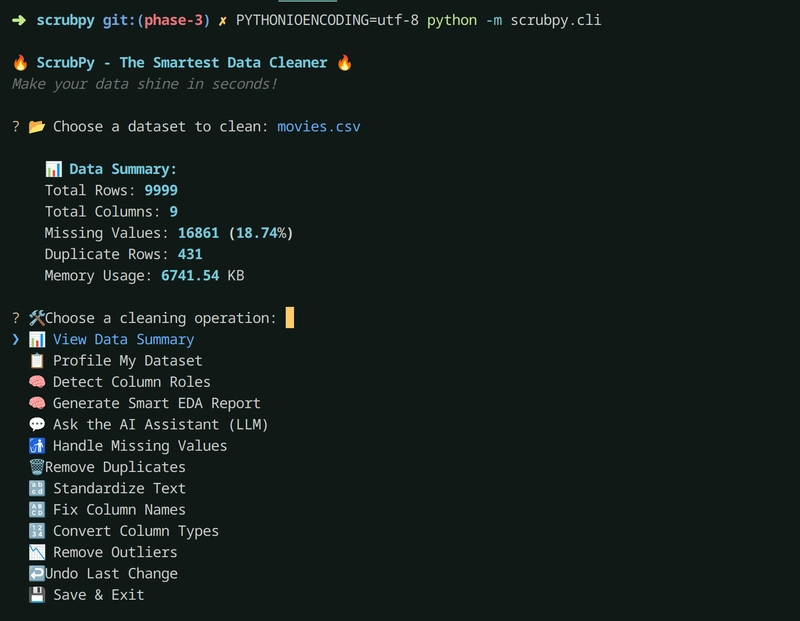
I’ve been building a CLI tool called ScrubPy to make data cleaning less of a pain. It’s a terminal-based utility that lets you profile your dataset, handle missing values and duplicates, fix column names, remove outliers, etc. You can preview all changes before applying, and it even exports clean EDA reports with visualizations.
Some of the main features:
Dataset profiling (nulls, duplicates, outliers, stats)
One-click cleaning for common issues
Standardize columns and convert types safely
Smart EDA PDF export
Undo support for every operation
A Snapshot of the CLI Tool
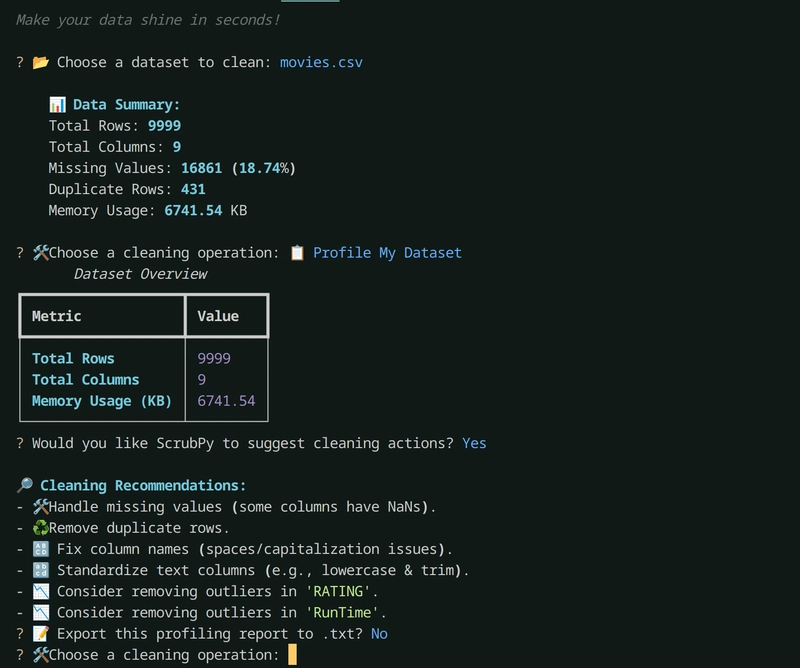
*A SnapShot of the DataProfiling tool in Action *
Right now I’m working on a new phase (branch: phase-3) where I’m adding LLM support using Mistral via Ollama. The idea is to let users “talk to their dataset” — so you can ask it questions like:
What’s wrong with my data?
How should I clean this column?
Can you suggest cleaning steps?
A small version of this is working. It analyzes column roles, samples a few rows, and asks the LLM for cleaning suggestions. But obviously, I can’t pass the full dataset (token limits + performance), so I’m still figuring out the best way to give the LLM just enough context.
Still unsure what the most useful features would be from a user perspective. Would love feedback or ideas:
What kind of LLM-powered suggestions would actually help during data prep?
Is there a better way to summarize dataset structure for an LLM?
Should I focus more on natural language → code translation?
Appreciate any thoughts. Happy to share the repo soon too once this phase is more stable.


