






























![[Free Webinar] Guide to Securing Your Entire Identity Lifecycle Against AI-Powered Threats](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjqbZf4bsDp6ei3fmQ8swm7GB5XoRrhZSFE7ZNhRLFO49KlmdgpIDCZWMSv7rydpEShIrNb9crnH5p6mFZbURzO5HC9I4RlzJazBBw5aHOTmI38sqiZIWPldRqut4bTgegipjOk5VgktVOwCKF_ncLeBX-pMTO_GMVMfbzZbf8eAj21V04y_NiOaSApGkM/s1600/webinar-play.jpg?#)







































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)









































































































































































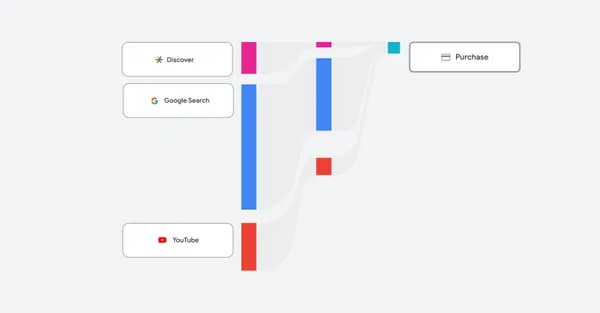

































































































_Jochen_Tack_Alamy.png?width=1280&auto=webp&quality=80&disable=upscale#)























































































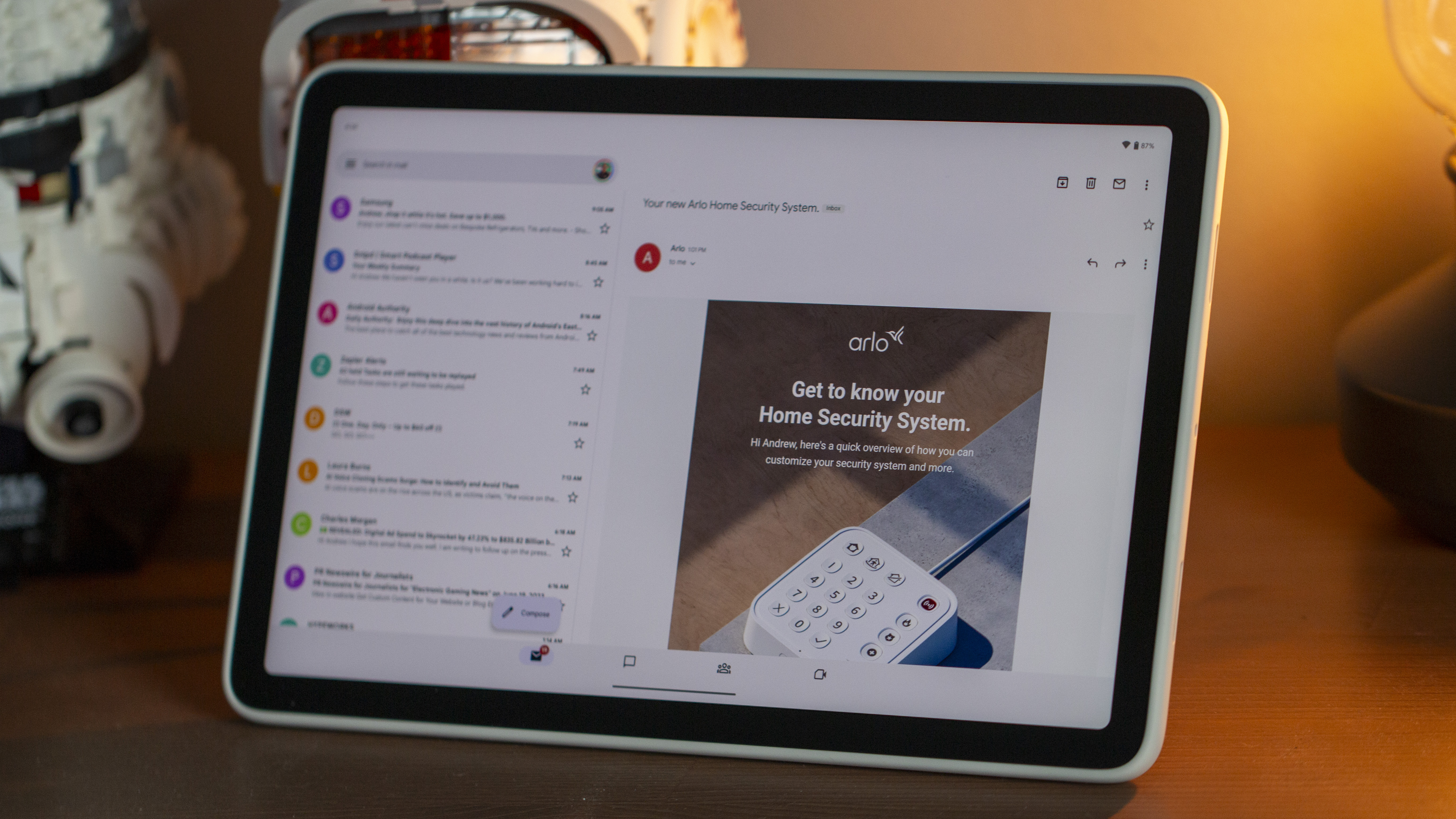






![Apple testing Stage Manager for iPhone, Photographic Styles for video, and more [Video]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/iOS-Decoded-iOS-18.5.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)














![New Hands-On iPhone 17 Dummy Video Shows Off Ultra-Thin Air Model, Updated Pro Designs [Video]](https://www.iclarified.com/images/news/97171/97171/97171-640.jpg)
![Apple Shares Trailer for First Immersive Feature Film 'Bono: Stories of Surrender' [Video]](https://www.iclarified.com/images/news/97168/97168/97168-640.jpg)
![Apple Restructures Global Affairs and Apple Music Teams [Report]](https://www.iclarified.com/images/news/97162/97162/97162-640.jpg)





























































































When it comes to application speed and scalability, database performance is often the bottleneck. Whether you’re handling millions of rows or preparing for scale, optimizing your database can bring dramatic improvements in response time, resource usage, and overall system reliability. In this blog post, we’ll explore 12 powerful techniques to improve database performance — from simple indexing tweaks to architectural strategies like sharding and replication. 1️⃣ Indexing: Speed Up Your Queries What it is: Indexes are data structures that help databases find rows faster, much like an index in a book. Why it helps: Without indexes, the database scans every row (full table scan), which becomes painfully slow as data grows. Tips: Use composite indexes for queries with multiple conditions. Monitor with EXPLAIN or EXPLAIN ANALYZE to understand query plans. Drop unused indexes to reduce overhead on write operations. 2️⃣ Materialized Views: Precompute for Speed What it is: Materialized views store the result of a query physically on disk. Why it helps: Instead of recomputing expensive joins or aggregations every time, your app can fetch precomputed results. Use cases: Dashboard analytics Complex reports Frequently run aggregations 3️⃣ Vertical Scaling: Beef Up the Machine What it is: Increase resources (CPU, RAM, SSD) on your existing database server. Why it helps: More memory can reduce disk I/O by caching more data in RAM, and faster CPUs speed up computation. Caveat: This has upper limits — it’s a short-to-mid term fix, not a long-term solution. 4️⃣ Denormalization: Fewer Joins, Faster Reads What it is: The process of combining related tables into one to avoid expensive joins. Why it helps: Reduces join complexity and improves read performance. Example: Instead of joining orders and customers, include customer name directly in orders. Downside: Increases redundancy and potential update anomalies — use carefully. 5️⃣ Database Caching: Keep Hot Data Close What it is: Store frequently accessed data in memory (Redis, Memcached) instead of hitting the DB every time. Why it helps: Reduces latency and database load, enabling higher throughput. Strategies: Read-through cache for fetching Write-through cache for saving TTL (Time to Live) to prevent stale data 6️⃣ Replication: Distribute the Load What it is: Copy your primary database to one or more replicas. Why it helps: Offloads read traffic, improves availability, and provides failover support. Types: Master-slave (read replicas) Multi-master (writes on multiple nodes) 7️⃣ Sharding: Break It Down to Scale Out What it is: Splitting a large database into smaller, independent shards based on a key (like user ID). Why it helps: Distributes data and load horizontally across servers. Challenges: Complex to implement Cross-shard queries require orchestration 8️⃣ Partitioning: Divide and Conquer What it is: Splitting a large table into smaller logical parts (partitions) stored in the same database. Why it helps: Speeds up queries that only need to search a specific partition. Types: Range Partitioning (e.g., date) List Partitioning (e.g., region) Hash Partitioning (randomized) 9️⃣ Query Optimization: Make Every Query Count What it is: Reviewing and rewriting SQL queries to execute more efficiently. How to optimize: Use LIMIT, OFFSET, and SELECT only required columns Avoid SELECT * Leverage query profiling tools (EXPLAIN, ANALYZE, slow query logs)
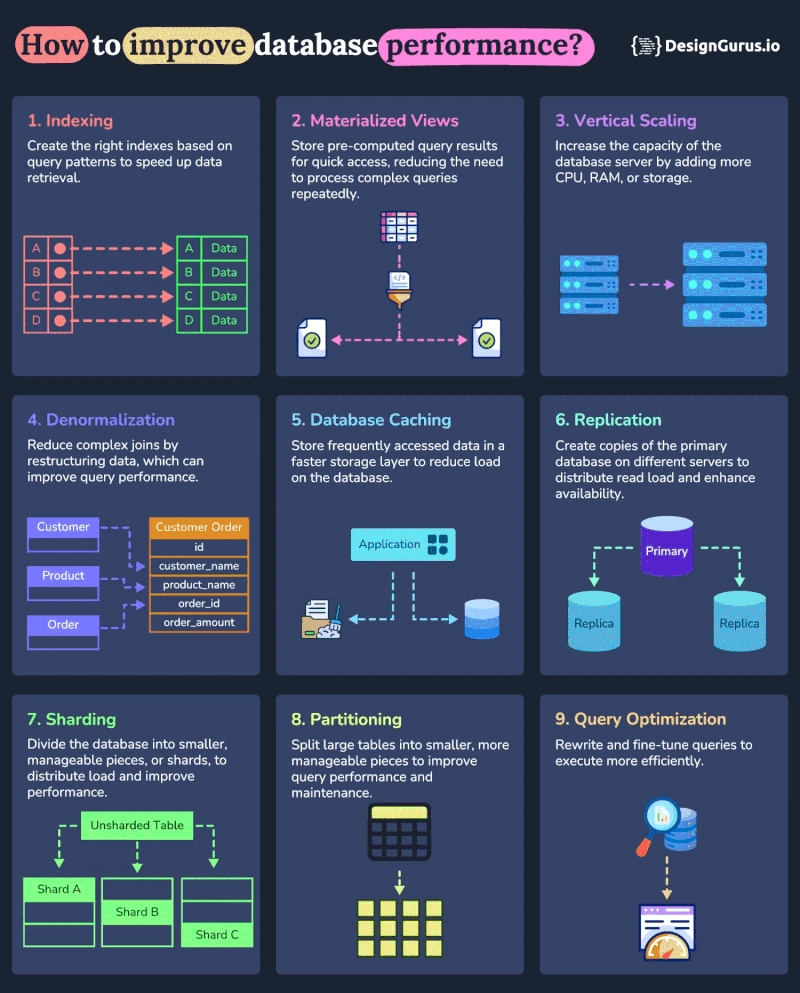
When it comes to application speed and scalability, database performance is often the bottleneck. Whether you’re handling millions of rows or preparing for scale, optimizing your database can bring dramatic improvements in response time, resource usage, and overall system reliability.
In this blog post, we’ll explore 12 powerful techniques to improve database performance — from simple indexing tweaks to architectural strategies like sharding and replication.
1️⃣ Indexing: Speed Up Your Queries
What it is: Indexes are data structures that help databases find rows faster, much like an index in a book.
Why it helps: Without indexes, the database scans every row (full table scan), which becomes painfully slow as data grows.
Tips:
- Use composite indexes for queries with multiple conditions.
- Monitor with
EXPLAINorEXPLAIN ANALYZEto understand query plans. - Drop unused indexes to reduce overhead on write operations.
2️⃣ Materialized Views: Precompute for Speed
What it is: Materialized views store the result of a query physically on disk.
Why it helps: Instead of recomputing expensive joins or aggregations every time, your app can fetch precomputed results.
Use cases:
- Dashboard analytics
- Complex reports
- Frequently run aggregations
3️⃣ Vertical Scaling: Beef Up the Machine
What it is: Increase resources (CPU, RAM, SSD) on your existing database server.
Why it helps: More memory can reduce disk I/O by caching more data in RAM, and faster CPUs speed up computation.
Caveat: This has upper limits — it’s a short-to-mid term fix, not a long-term solution.
4️⃣ Denormalization: Fewer Joins, Faster Reads
What it is: The process of combining related tables into one to avoid expensive joins.
Why it helps: Reduces join complexity and improves read performance.
Example: Instead of joining orders and customers, include customer name directly in orders.
Downside: Increases redundancy and potential update anomalies — use carefully.
5️⃣ Database Caching: Keep Hot Data Close
What it is: Store frequently accessed data in memory (Redis, Memcached) instead of hitting the DB every time.
Why it helps: Reduces latency and database load, enabling higher throughput.
Strategies:
- Read-through cache for fetching
- Write-through cache for saving
- TTL (Time to Live) to prevent stale data
6️⃣ Replication: Distribute the Load
What it is: Copy your primary database to one or more replicas.
Why it helps: Offloads read traffic, improves availability, and provides failover support.
Types:
- Master-slave (read replicas)
- Multi-master (writes on multiple nodes)
7️⃣ Sharding: Break It Down to Scale Out
What it is: Splitting a large database into smaller, independent shards based on a key (like user ID).
Why it helps: Distributes data and load horizontally across servers.
Challenges:
- Complex to implement
- Cross-shard queries require orchestration
8️⃣ Partitioning: Divide and Conquer
What it is: Splitting a large table into smaller logical parts (partitions) stored in the same database.
Why it helps: Speeds up queries that only need to search a specific partition.
Types:
- Range Partitioning (e.g., date)
- List Partitioning (e.g., region)
- Hash Partitioning (randomized)
9️⃣ Query Optimization: Make Every Query Count
What it is: Reviewing and rewriting SQL queries to execute more efficiently.
How to optimize:
- Use
LIMIT,OFFSET, andSELECTonly required columns - Avoid
SELECT * - Leverage query profiling tools (
EXPLAIN,ANALYZE, slow query logs)


