



































































































































































![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)











































































































































































































































































_Muhammad_R._Fakhrurrozi_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_NicoElNino_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





















































































![macOS 15.5 beta 4 now available for download [U]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/04/macOS-Sequoia-15.5-b4.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)















![AirPods Pro 2 With USB-C Back On Sale for Just $169! [Deal]](https://www.iclarified.com/images/news/96315/96315/96315-640.jpg)
![Apple Releases iOS 18.5 Beta 4 and iPadOS 18.5 Beta 4 [Download]](https://www.iclarified.com/images/news/97145/97145/97145-640.jpg)
![Apple Seeds watchOS 11.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97147/97147/97147-640.jpg)
![Apple Seeds visionOS 2.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97150/97150/97150-640.jpg)





































![Apple Seeds Fourth Beta of iOS 18.5 to Developers [Update: Public Beta Available]](https://images.macrumors.com/t/uSxxRefnKz3z3MK1y_CnFxSg8Ak=/2500x/article-new/2025/04/iOS-18.5-Feature-Real-Mock.jpg)
![Apple Seeds Fourth Beta of macOS Sequoia 15.5 [Update: Public Beta Available]](https://images.macrumors.com/t/ne62qbjm_V5f4GG9UND3WyOAxE8=/2500x/article-new/2024/08/macOS-Sequoia-Night-Feature.jpg)






















































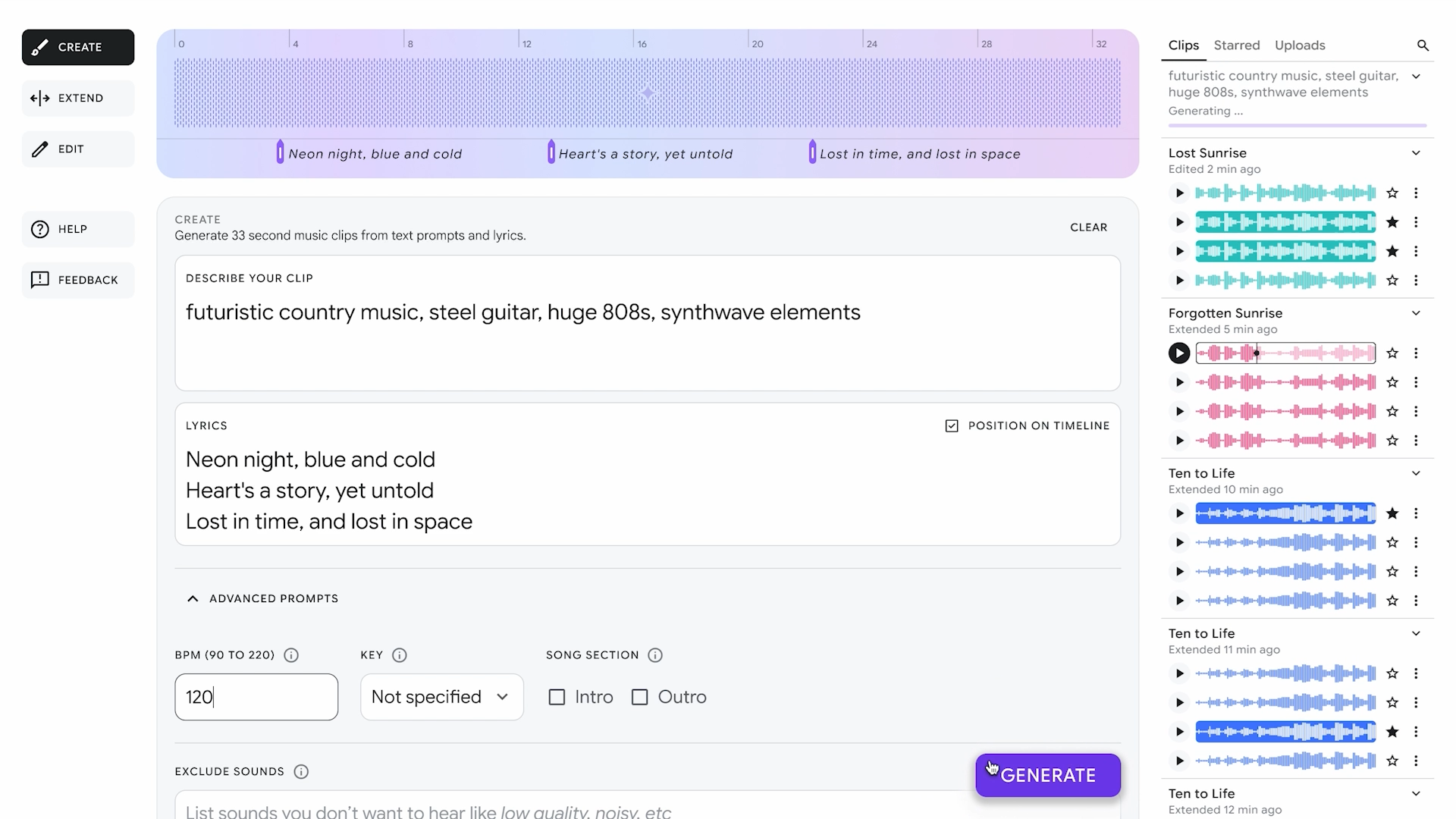
How run LLM in local using Docker.
Self-hosted LLMs are gaining a lot of momentum. They offer advantages such as improved performance, lower costs, and better data privacy. You don't need to rely on third-party APIs, which means no unexpected increases in latency, no sudden changes in model behavior, and more control over your LLM. However, running a model locally is a task in itself. There is currently no standard way or tool available to run models on local machines. Docker model runner: Docker Model Runner makes running AI models as simple as running a container locally — just a single command, with no need for additional configuration or hassle. If you are using Apple Silicon, you can take advantage of GPU acceleration for faster inference. The Docker local LLM inference engine is built on top of llama.cpp. This engine is exposed through an OpenAI-compatible API. Before running an LLM model using Docker, make sure you are using Docker Desktop version 4.40 or later. Running a model is similar to running a container. First, start by pulling a model. docker model pull ai/llama3.1 Full list of available models are here. Once the pull is complete, your model is ready to use. You don't need to manually run any containers — Docker will automatically use its inference API server endpoint to handle your requests. You can access your model from other containers using the http://model-runner.docker.internal/engines/v1 endpoint: curl http://model-runner.docker.internal/engines/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "ai/llama3.1", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "Please write 500 words about the fall of Rome." } ] }' If you want to access the model from host processes (i.e., the machine where Docker is running), you need to enable TCP host access: docker desktop enable model-runner --tcp 12434 Here, 12434 is the TCP port where your model will be accessible. You can then make requests from the host just like this: curl http://localhost:12434/engines/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "ai/llama3.1", "messages": [ { "role": "system", "content": "You are a helpful assistant." }, { "role": "user", "content": "Please write 500 words about the fall of Rome." } ] }' With everything up and running, you're ready to make local LLM calls! You can use this endpoint with any OpenAI-compatible clients or frameworks.

Self-hosted LLMs are gaining a lot of momentum. They offer advantages such as improved performance, lower costs, and better data privacy. You don't need to rely on third-party APIs, which means no unexpected increases in latency, no sudden changes in model behavior, and more control over your LLM.
However, running a model locally is a task in itself. There is currently no standard way or tool available to run models on local machines.
Docker model runner:
Docker Model Runner makes running AI models as simple as running a container locally — just a single command, with no need for additional configuration or hassle.
If you are using Apple Silicon, you can take advantage of GPU acceleration for faster inference.
The Docker local LLM inference engine is built on top of llama.cpp. This engine is exposed through an OpenAI-compatible API. Before running an LLM model using Docker, make sure you are using Docker Desktop version 4.40 or later.
Running a model is similar to running a container. First, start by pulling a model.
docker model pull ai/llama3.1
Full list of available models are here.
Once the pull is complete, your model is ready to use. You don't need to manually run any containers — Docker will automatically use its inference API server endpoint to handle your requests.
You can access your model from other containers using the http://model-runner.docker.internal/engines/v1 endpoint:
curl http://model-runner.docker.internal/engines/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/llama3.1",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Please write 500 words about the fall of Rome."
}
]
}'
If you want to access the model from host processes (i.e., the machine where Docker is running), you need to enable TCP host access:
docker desktop enable model-runner --tcp 12434
Here, 12434 is the TCP port where your model will be accessible.
You can then make requests from the host just like this:
curl http://localhost:12434/engines/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/llama3.1",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Please write 500 words about the fall of Rome."
}
]
}'
With everything up and running, you're ready to make local LLM calls!
You can use this endpoint with any OpenAI-compatible clients or frameworks.


