![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)

























































































































































![Is this too much for a modular monolith system? [closed]](https://i.sstatic.net/pYL1nsfg.png)


























































































































_Andreas_Prott_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
























































































![What features do you get with Gemini Advanced? [April 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/02/gemini-advanced-cover.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)












![Apple Shares Official Trailer for 'Long Way Home' Starring Ewan McGregor and Charley Boorman [Video]](https://www.iclarified.com/images/news/97069/97069/97069-640.jpg)
![Apple Watch Series 10 Back On Sale for $299! [Lowest Price Ever]](https://www.iclarified.com/images/news/96657/96657/96657-640.jpg)
![EU Postpones Apple App Store Fines Amid Tariff Negotiations [Report]](https://www.iclarified.com/images/news/97068/97068/97068-640.jpg)
![Apple Slips to Fifth in China's Smartphone Market with 9% Decline [Report]](https://www.iclarified.com/images/news/97065/97065/97065-640.jpg)





























































































































GEN-AI 4 : GAN
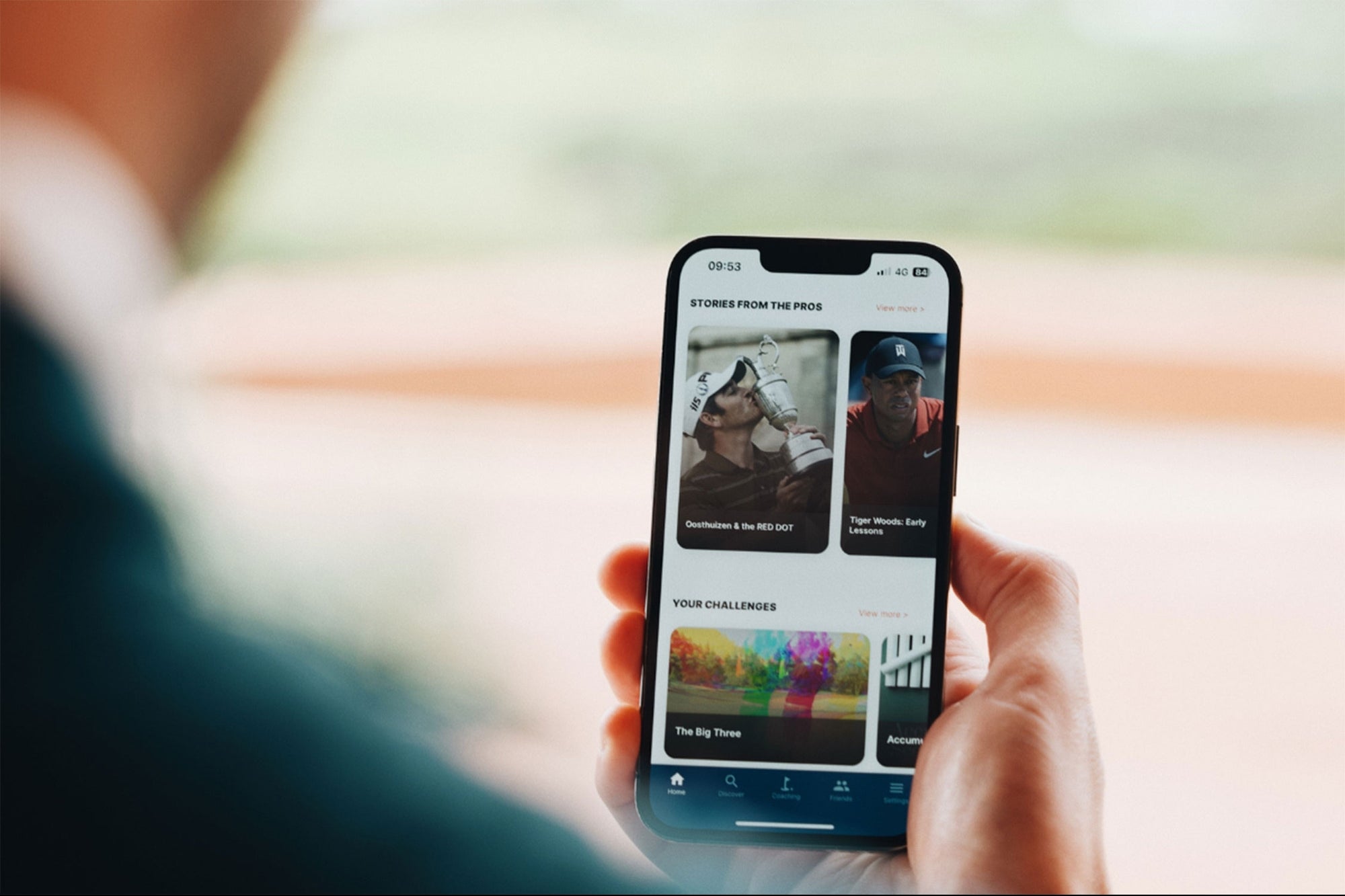
In the world of generative models, Variational Autoencoders (VAEs) were among the first to show us how machines can learn to create new data. But they came with limitations which sparked the need for a new direction in generative modeling. Enter Generative Adversarial Networks (GANs): a powerful, game-theoretic approach that changed the landscape by producing stunningly realistic outputs and pushing the boundaries of what machines can generate. Lets start by understanding the limitations of VAE. Disadvantages of VAE Blurry Outputs: In a VAE, two things are being balanced: how well the model can recreate the input data (reconstruction loss) and how closely the latent variables follow the assumed normal distribution (KL divergence). If this balance isn't right, it can cause problems. For example, if the model focuses too much on making the latent space look normal, it might not focus enough on accurately recreating the input data, leading to blurry or low-quality reconstructions. Finding the right balance is tricky, and if it's off, the output can look fuzzy or unclear. Latent Space Constraints: When we assume a simple normal distribution for the latent variables in a VAE, it means we expect the data to follow a very basic pattern (like a bell curve). However, real-world data is often more complex and doesn't always fit this simple pattern. Because of this, the VAE might not capture all the details or variations in the data, leading to less accurate results and poor generation of new data. Essentially, the model's assumption limits its ability to understand and recreate the data’s true complexity fully. Mode Averaging: When the data has many different patterns or "modes" (called multimodal data), VAEs can struggle to capture all of them. The model tends to average over these modes, meaning it might create a mix of features from different data patterns instead of focusing on the specific details of each mode. This can result in the model generating outputs that don’t accurately reflect the diversity of the data, often leading to a loss of important variations or details in the generated samples. Essentially, the model might not fully capture all the unique aspects of the data. How is GAN better than VAE? While Variational Autoencoders (VAEs) offer a powerful framework for generative modeling, they come with certain limitations. To address these challenges, Generative Adversarial Networks (GANs) provide an alternative approach. Unlike VAEs, which rely on a probabilistic framework, GANs use two neural networks—a generator and a discriminator—that compete against each other to improve the quality of generated data. The adversarial setup in GANs enables them to produce sharper, more realistic outputs, particularly in applications like image generation, where detail and realism are crucial. Here’s how GANs are better than VAEs: Sharper Outputs: GANs produce clearer and more detailed images because they focus on distinguishing real data from generated data, leading to more realistic results. No Blurry Reconstructions: Unlike VAEs, which can sometimes produce blurry outputs due to their reliance on a probabilistic framework, GANs avoid this issue by directly optimizing for realism. Better for High-Quality Generation: GANs excel in tasks where the goal is to generate high-quality data, like realistic images, videos, or audio, because the adversarial training encourages the generator to produce more lifelike results. Flexibility in Learning Complex Patterns: GANs can learn complex data distributions better, especially when data has many modes (variety of patterns), without averaging out the details like VAEs might. Working of GAN A Generative Adversarial Network (GAN) is a machine learning model that consists of two neural networks, a generator and a discriminator, that work against each other in a process called adversarial training. Here's how it works in detail: The Generator: The generator is like an artist trying to create new data (e.g., images) that looks as real as possible. It starts with random noise and uses this as input to produce a generated output. The goal of the generator is to produce data that can fool the discriminator into thinking it’s real. The Discriminator: The discriminator is like a critic trying to tell whether a piece of data is real (from the training data) or fake (produced by the generator). It takes an input—either real data or a generated one—and outputs a probability that the input is real or fake. It can be considered as a supervised image classification problem. Adversarial Training: The key idea behind GANs is the competition between the generator and the discriminator: The generator tries to improve by creating more convincing, realistic data to fool the discriminator. The discriminator tries to improve by getting better at distinguishing real data from the fake data created by the gener

In the world of generative models, Variational Autoencoders (VAEs) were among the first to show us how machines can learn to create new data. But they came with limitations which sparked the need for a new direction in generative modeling.
Enter Generative Adversarial Networks (GANs): a powerful, game-theoretic approach that changed the landscape by producing stunningly realistic outputs and pushing the boundaries of what machines can generate.
Lets start by understanding the limitations of VAE.
Disadvantages of VAE
Blurry Outputs: In a VAE, two things are being balanced: how well the model can recreate the input data (reconstruction loss) and how closely the latent variables follow the assumed normal distribution (KL divergence). If this balance isn't right, it can cause problems. For example, if the model focuses too much on making the latent space look normal, it might not focus enough on accurately recreating the input data, leading to blurry or low-quality reconstructions. Finding the right balance is tricky, and if it's off, the output can look fuzzy or unclear.
Latent Space Constraints: When we assume a simple normal distribution for the latent variables in a VAE, it means we expect the data to follow a very basic pattern (like a bell curve). However, real-world data is often more complex and doesn't always fit this simple pattern. Because of this, the VAE might not capture all the details or variations in the data, leading to less accurate results and poor generation of new data. Essentially, the model's assumption limits its ability to understand and recreate the data’s true complexity fully.
Mode Averaging: When the data has many different patterns or "modes" (called multimodal data), VAEs can struggle to capture all of them. The model tends to average over these modes, meaning it might create a mix of features from different data patterns instead of focusing on the specific details of each mode. This can result in the model generating outputs that don’t accurately reflect the diversity of the data, often leading to a loss of important variations or details in the generated samples. Essentially, the model might not fully capture all the unique aspects of the data.
How is GAN better than VAE?
While Variational Autoencoders (VAEs) offer a powerful framework for generative modeling, they come with certain limitations. To address these challenges, Generative Adversarial Networks (GANs) provide an alternative approach. Unlike VAEs, which rely on a probabilistic framework, GANs use two neural networks—a generator and a discriminator—that compete against each other to improve the quality of generated data. The adversarial setup in GANs enables them to produce sharper, more realistic outputs, particularly in applications like image generation, where detail and realism are crucial.

Here’s how GANs are better than VAEs:
Sharper Outputs: GANs produce clearer and more detailed images because they focus on distinguishing real data from generated data, leading to more realistic results.
No Blurry Reconstructions: Unlike VAEs, which can sometimes produce blurry outputs due to their reliance on a probabilistic framework, GANs avoid this issue by directly optimizing for realism.
Better for High-Quality Generation: GANs excel in tasks where the goal is to generate high-quality data, like realistic images, videos, or audio, because the adversarial training encourages the generator to produce more lifelike results.
Flexibility in Learning Complex Patterns: GANs can learn complex data distributions better, especially when data has many modes (variety of patterns), without averaging out the details like VAEs might.
Working of GAN
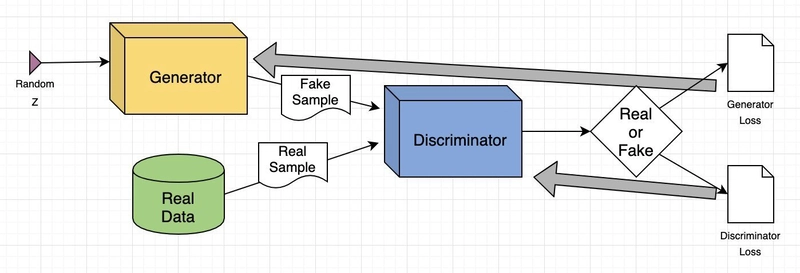
A Generative Adversarial Network (GAN) is a machine learning model that consists of two neural networks, a generator and a discriminator, that work against each other in a process called adversarial training. Here's how it works in detail:
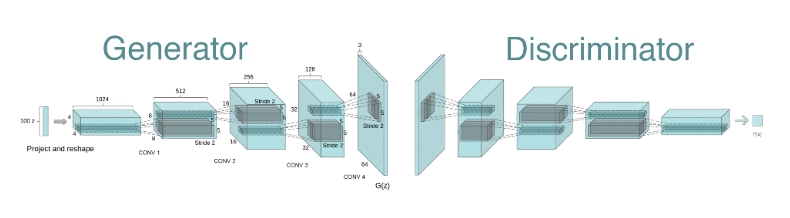
The Generator:
The generator is like an artist trying to create new data (e.g., images) that looks as real as possible. It starts with random noise and uses this as input to produce a generated output. The goal of the generator is to produce data that can fool the discriminator into thinking it’s real.
The Discriminator:
The discriminator is like a critic trying to tell whether a piece of data is real (from the training data) or fake (produced by the generator). It takes an input—either real data or a generated one—and outputs a probability that the input is real or fake. It can be considered as a supervised image classification problem.
Adversarial Training:
The key idea behind GANs is the competition between the generator and the discriminator:
The generator tries to improve by creating more convincing, realistic data to fool the discriminator.
The discriminator tries to improve by getting better at distinguishing real data from the fake data created by the generator.
This process is a game where the generator tries to "cheat" by generating better data, and the discriminator tries to become more skilled at detecting fake data. Over time, both networks improve.

The Objective:
Generator's Goal: Minimize how often the discriminator correctly identifies fake data. It wants to produce data that the discriminator can't distinguish from real data.
Discriminator's Goal: Maximize its ability to correctly classify real vs. fake data, helping it get better at spotting fakes.

The interaction between the discriminator and generator in a GAN requires a delicate balance. If the discriminator is too good, it can easily distinguish real from fake data, leaving the generator with little feedback and hindering its ability to improve. On the other hand, if the generator is too strong, it may exploit weaknesses in the discriminator, producing fake data that the discriminator wrongly classifies as real (false negatives). The ideal situation occurs when the discriminator outputs a value close to 0.5, meaning it cannot distinguish between real and fake data, indicating that the generator is producing high-quality samples. For example, if the discriminator outputs ~1, the fake images are too realistic, and the generator won't be forced to improve. If it outputs ~0, the fake images are too obvious, and the generator needs more training. However, when the discriminator outputs ~0.5, it suggests the generator is performing well, producing convincing, realistic samples.

The Loss Functions:
The generator's job in a GAN is to create fake data that looks so real that the discriminator can’t tell it apart from the real data. Instead of directly focusing on the quality of the data, the generator’s main goal is to trick the discriminator into thinking the fake data is real. The generator gets feedback from the discriminator, which helps it improve. The loss function for the generator encourages it to produce data that has a high probability of being classified as real by the discriminator
The discriminator in a GAN's job is to tell whether the data it sees is real (from the true data source) or fake (generated by the generator). It outputs a probability (between 0 and 1) that the input is real.
The goal of the discriminator is to correctly classify Real data as real and Fake data as fake.

Together, the overall training objective for the GAN can be summarized as :
GAN Loss = Discriminator Loss + Generator Loss
Training Process:
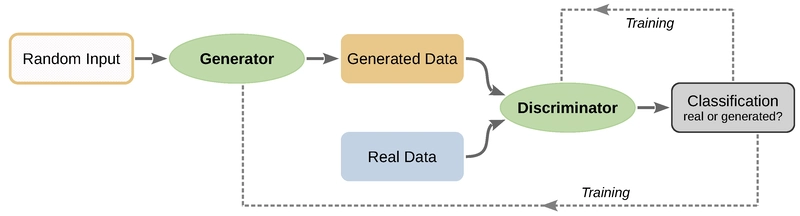
The training process of a Generative Adversarial Network (GAN) involves a series of steps that alternate between training the discriminator and the generator.
- Initialize the generator and discriminator.
- Train the discriminator on real and fake data.
- Train the generator to fool the discriminator.
- Alternate between training the discriminator and the generator.
- Repeat until the generator produces convincing fake data.
We must alternate the training of these two networks, making sure that we only update the weights of one network at a time!
Initially, the generator creates very poor, random data, and the discriminator easily detects it as fake. This adversarial training process continues until the generator has learned to produce realistic data, and the discriminator has become more adept at distinguishing real from fake data.
Training can be stopped when the generator produces high-quality data that the discriminator cannot reliably distinguish from real data (i.e., the discriminator’s output approaches 0.5, meaning it cannot differentiate between real and fake data).
Situations in GAN
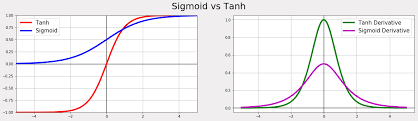
1) - We normalize the input range from 0, 255 to [-1, 1] instead of [0, 1] because the tanh activation function works better with inputs in the range of [-1, 1]. The tanh function outputs values between -1 and 1, and normalizing the data to this range helps ensure the gradients are stronger and more stable during training. In contrast, the sigmoid activation function has a range of [0, 1] and produces weaker gradients, which can slow down learning. Therefore, using [-1, 1] helps improve the training process.
2) - The training process of GANs can be unstable because the generator and discriminator are constantly competing. Over time, the discriminator may become too good at distinguishing real from fake data, which could cause issues. However, this isn't always a problem because the generator might have already learned enough by that point. To improve stability, we can add a small amount of random noise to the training labels, which helps prevent the discriminator from becoming too dominant too quickly

3) - When the Discriminator Overpowers the Generator,
- The discriminator becomes too good at distinguishing real from fake images.
- This causes the generator to receive weak feedback, and the loss signal becomes too weak to improve the generator.
The discriminator perfectly classifies real and fake images, causing the gradients to vanish, and the generator stops training.
Solutions to Weaken the Discriminator:
Increase the Dropout rate in the discriminator to reduce its ability to overfit.
Reduce the learning rate of the discriminator to slow down its training.
Reduce the number of convolutional filters in the discriminator to limit its capacity.
Add noise to the labels when training the discriminator to make it harder for the discriminator to distinguish real from fake.
Randomly flip labels of some images during training to confuse the discriminator and prevent it from becoming too powerful.

4) - When the Generator Overpowers the Discriminator:
- The discriminator becomes too weak, and the generator tricks it with a small set of nearly identical images.
This results in mode collapse, where the generator produces limited variety in its outputs, focusing on a single observation that fools the discriminator.
Solutions to Weaken the Generator:
If you find that your generator is suffering from mode collapse, you can try strengthening the discriminator using the opposite suggestions to those listed in the previous section. Also, you can try reducing the learning rate of both networks and increasing the batch size.
5) - The generator's loss is evaluated based on the current discriminator, which constantly improves during training. This makes it hard to compare the generator's loss at different stages, as it may not reflect the actual quality of generated images. The loss can even increase over time, despite the images improving, because the discriminator is getting better, making it harder for the generator to fool it.

Disadvantages of GAN.
Mode Collapse: The generator may start producing limited, identical outputs, tricking the discriminator, and failing to capture the full diversity of the data.

Uninformative Loss: The generator's loss may increase even as image quality improves, making it hard to track progress.
Vanishing Gradients: If the discriminator becomes too powerful, the generator may receive weak gradients, preventing meaningful learning.
Hyperparameter Sensitivity: GANs are sensitive to choices like learning rates, dropout rates, and the number of layers, requiring careful tuning for optimal performance.