

























































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)
























































































































































![Is This Programming Paradigm New? [closed]](https://miro.medium.com/v2/resize:fit:1200/format:webp/1*nKR2930riHA4VC7dLwIuxA.gif)


















































































(1).jpg?#)
.jpg?#)




-Classic-Nintendo-GameCube-games-are-coming-to-Nintendo-Switch-2!-00-00-13.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)

























_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)








































































































![M4 MacBook Air Drops to New All-Time Low of $912 [Deal]](https://www.iclarified.com/images/news/97108/97108/97108-640.jpg)
![New iPhone 17 Dummy Models Surface in Black and White [Images]](https://www.iclarified.com/images/news/97106/97106/97106-640.jpg)






























































































































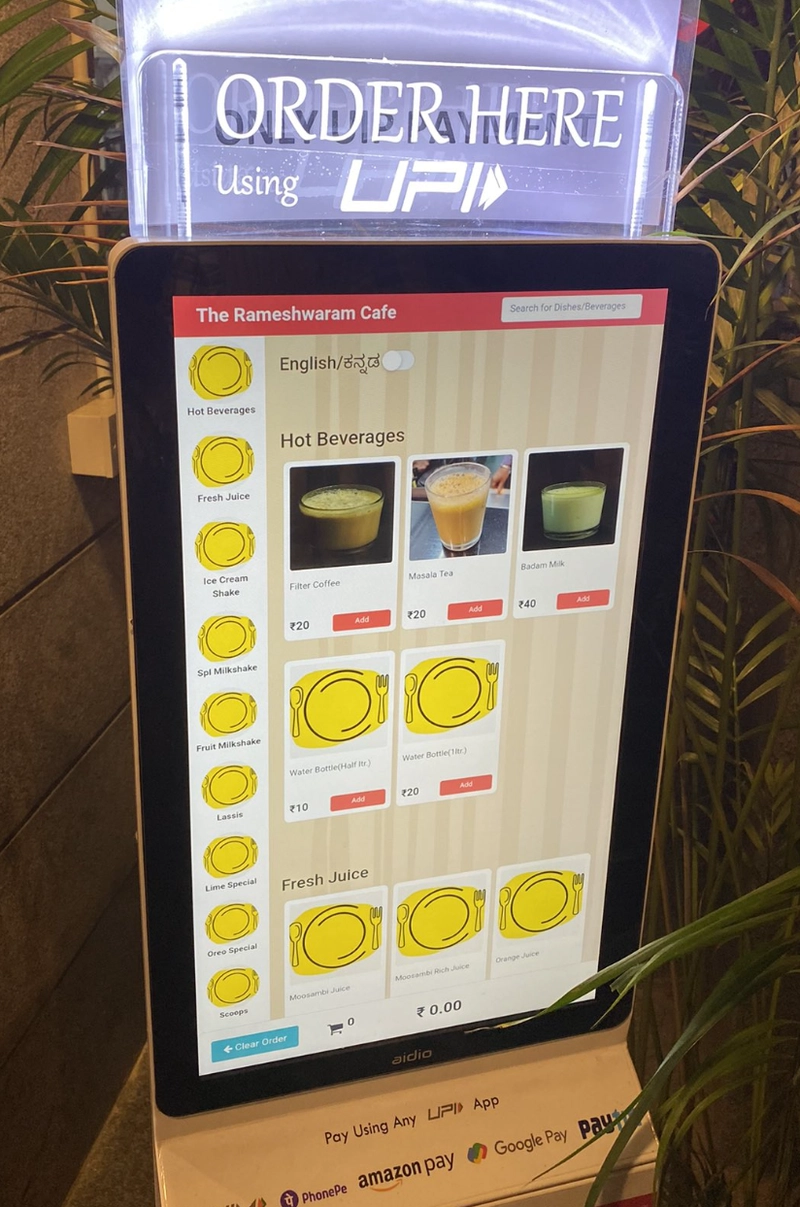
From Idlis to AI: The FACT of AI Model Management through Rameshwaram Cafe's Lens
Ever visited Rameshwaram Cafe in Bengaluru during peak hours? It's a marvel of efficiency – hundreds of customers, dozens of dosas and idlis being prepared simultaneously, staff coordinating seamlessly, and somehow every plate of food arrives hot, fresh and perfect. That's exactly what good AI model management looks like in 2025. Hey there! I'm guessing if you're reading this, you've got some AI models running (or are planning to), and you've realized that getting them to work well is surprisingly complex. Don't worry - you're not alone. Why AI Model Management Matters? Let me tell you a quick story. A friend of mine deployed a language model for customer service last year. The situation was like opening a Rameshwaram Cafe branch without their famous management system. It worked during the test phase with a few customers, but when hundreds started pouring in? Slow service, missing orders, and occasionally serving upma when someone ordered idli. The culprit? They didn't have a proper model management strategy. Think about it: AI models are like Rameshwaram Cafe's signature recipes. Sure, you can get the ingredients and basic instructions, but without their precise preparation techniques, equipment calibration, and synchronized cooking process, you won't get that same magic on the plate. To make this super easy to remember, I've created a simple framework called FACT: Fidelity (accuracy/quality) - Like Rameshwaram's consistent taste Adaptability (hardware compatibility) - Like their ability to scale from slow to peak hours Cost (efficiency/resources) - Like their optimal use of ingredients and staff Traceability (versioning/reproducibility) - Like their standardized recipes and training Let's break each of these down in plain English, with a special focus on quantization (that magical process that makes models faster and smaller). The Quantization Conundrum (Fidelity) At Rameshwaram Cafe, they use different preparation methods based on volume needs while maintaining taste. During slow hours, they might prepare dosas individually with maximum attention. During rush hour, they optimize their process, maybe using pre-mixed batters or slightly larger batches. That's basically what quantization does for AI models. Here's a simple breakdown: FP32 (32-bit): The "master chef personally preparing each dosa" version - highest quality, but can only serve a few customers FP16 (16-bit): The "senior chef with standardized process" - virtually identical quality, twice the serving capacity INT8 (8-bit): The "efficient team cooking" - slight variations in quality, but four times the output INT4 (4-bit): The "streamlined rush hour process" - noticeable quality differences, but massive volume capability INT2 (2-bit): The "express preparation" - significant quality compromises, but incredibly fast Let me make this concrete. Say you've got a language model for generating marketing copy: With FP32, it's like the founder of Rameshwaram personally making your dosa - perfect but limited availability With FP16, it's like their head chef - the quality is virtually identical, but serves twice as many With INT8, occasionally there might be slight inconsistencies, but most customers can't tell the difference With INT4, regular customers will notice the difference, but it's still satisfying for basic hunger With INT2, you're getting the core flavors, but missing the subtleties that make it special The fidelity part of the FACT framework asks: "What's the minimum quality level your customers (applications) can tolerate?" Hardware Harmony (Adaptability) Rameshwaram Cafe would use different equipment in different locations. Their flagship store has top-of-the-line dosa tawas and industrial grinders. A smaller airport kiosk might use compact equipment. A food truck would need portable, energy-efficient setups. Not all hardware is created equal when it comes to running AI models: Gaming GPUs: Like a medium-sized Rameshwaram branch - great at standard preparations, decent volume Server GPUs: The flagship store - handles everything beautifully, but expensive to build and maintain Apple Silicon (like M1 Pro): Like their specially designed compact kitchens - surprisingly efficient for certain preparations Mobile chips: Their food truck setup - optimized for efficiency over variety Edge devices: The home meal kits - extremely limited but gets the basic job done This matters enormously! Running an FP16 model on hardware optimized for INT8 is like trying to use Rameshwaram's industrial-scale batter grinder in a food truck - technically possible, but woefully inefficient. Let's get specific: If you're running on a MacBook with M1 Pro, FP16 is often your sweet spot. The Neural Engine in those chips absolutely loves half-precision operations, like how Rameshwaram's compact locations have specialized equipment for their most popular items. Meanwhile, on a Jetson d

Ever visited Rameshwaram Cafe in Bengaluru during peak hours?
It's a marvel of efficiency – hundreds of customers, dozens of dosas and idlis being prepared simultaneously, staff coordinating seamlessly, and somehow every plate of food arrives hot, fresh and perfect. That's exactly what good AI model management looks like in 2025.
Hey there! I'm guessing if you're reading this, you've got some AI models running (or are planning to), and you've realized that getting them to work well is surprisingly complex. Don't worry - you're not alone.
Why AI Model Management Matters?
Let me tell you a quick story. A friend of mine deployed a language model for customer service last year. The situation was like opening a Rameshwaram Cafe branch without their famous management system. It worked during the test phase with a few customers, but when hundreds started pouring in? Slow service, missing orders, and occasionally serving upma when someone ordered idli.
The culprit?
They didn't have a proper model management strategy.

Think about it: AI models are like Rameshwaram Cafe's signature recipes. Sure, you can get the ingredients and basic instructions, but without their precise preparation techniques, equipment calibration, and synchronized cooking process, you won't get that same magic on the plate.

To make this super easy to remember, I've created a simple framework called FACT:
- Fidelity (accuracy/quality) - Like Rameshwaram's consistent taste
- Adaptability (hardware compatibility) - Like their ability to scale from slow to peak hours
- Cost (efficiency/resources) - Like their optimal use of ingredients and staff
- Traceability (versioning/reproducibility) - Like their standardized recipes and training
Let's break each of these down in plain English, with a special focus on quantization (that magical process that makes models faster and smaller).
The Quantization Conundrum (Fidelity)
At Rameshwaram Cafe, they use different preparation methods based on volume needs while maintaining taste. During slow hours, they might prepare dosas individually with maximum attention. During rush hour, they optimize their process, maybe using pre-mixed batters or slightly larger batches.
That's basically what quantization does for AI models.
Here's a simple breakdown:
- FP32 (32-bit): The "master chef personally preparing each dosa" version - highest quality, but can only serve a few customers
- FP16 (16-bit): The "senior chef with standardized process" - virtually identical quality, twice the serving capacity
- INT8 (8-bit): The "efficient team cooking" - slight variations in quality, but four times the output
- INT4 (4-bit): The "streamlined rush hour process" - noticeable quality differences, but massive volume capability
- INT2 (2-bit): The "express preparation" - significant quality compromises, but incredibly fast
Let me make this concrete. Say you've got a language model for generating marketing copy:
- With FP32, it's like the founder of Rameshwaram personally making your dosa - perfect but limited availability
- With FP16, it's like their head chef - the quality is virtually identical, but serves twice as many
- With INT8, occasionally there might be slight inconsistencies, but most customers can't tell the difference
- With INT4, regular customers will notice the difference, but it's still satisfying for basic hunger
- With INT2, you're getting the core flavors, but missing the subtleties that make it special
The fidelity part of the FACT framework asks: "What's the minimum quality level your customers (applications) can tolerate?"
Hardware Harmony (Adaptability)

Rameshwaram Cafe would use different equipment in different locations. Their flagship store has top-of-the-line dosa tawas and industrial grinders. A smaller airport kiosk might use compact equipment. A food truck would need portable, energy-efficient setups.
Not all hardware is created equal when it comes to running AI models:
- Gaming GPUs: Like a medium-sized Rameshwaram branch - great at standard preparations, decent volume
- Server GPUs: The flagship store - handles everything beautifully, but expensive to build and maintain
- Apple Silicon (like M1 Pro): Like their specially designed compact kitchens - surprisingly efficient for certain preparations
- Mobile chips: Their food truck setup - optimized for efficiency over variety
- Edge devices: The home meal kits - extremely limited but gets the basic job done
This matters enormously! Running an FP16 model on hardware optimized for INT8 is like trying to use Rameshwaram's industrial-scale batter grinder in a food truck - technically possible, but woefully inefficient.
Let's get specific: If you're running on a MacBook with M1 Pro, FP16 is often your sweet spot. The Neural Engine in those chips absolutely loves half-precision operations, like how Rameshwaram's compact locations have specialized equipment for their most popular items. Meanwhile, on a Jetson device, INT8 with TensorRT optimizations will run circles around FP16 implementations, just like how their express counters are optimized for quick-serve items.
The adaptability question is: "What quantization level best matches my hardware's strengths, like how Rameshwaram matches equipment to each location?"
Application Adaptation (Cost)

Different Rameshwaram Cafe locations serve different purposes. The main branch offers the full experience. Airport locations focus on quick service. Catering services prioritize volume. Each requires different resource allocation.
Different AI applications have wildly different requirements:
- Chatbots: Need to preserve nuanced understanding, like Rameshwaram's signature sambar recipe → FP16 or INT8 (Q8_0)
- Embeddings: Just need to maintain basic relationships, like knowing which side dishes go with which main items → Can go as low as INT2 (IQ2_XXS)
- Medical diagnosis: Requires maximum accuracy, like preparing food for someone with serious allergies → FP16 or higher
- Content recommendation: More tolerant of minor inaccuracies, like casual snack recommendations → INT8 or INT4
I often ask clients: "Would you rather have one perfect Rameshwaram experience or three good-enough experiences for the same cost?" That question gets to the heart of the cost consideration.
For production environments, here's a rule of thumb:
- Critical applications: Use higher precision, like how Rameshwaram never compromises on rice quality for their idlis
- Consumer applications: Can generally use more aggressive optimization, like how they streamline service during rush hour
- Memory-constrained devices: Push to INT4 or mixed precision, like how their take-away counter focuses on transportable items
The cost question is: "What's the optimal balance between resource usage and model quality for my specific use case, just like how Rameshwaram balances speed and quality differently at different locations?"
The Complete Kitchen (Traceability)
Even with perfect recipes and equipment, Rameshwaram Cafe needs systems around it all - staff training, quality control, inventory management, and customer feedback loops.
The key components of a complete model management system include:
- Version control for models: Which quantization method was applied to which model? Like how Rameshwaram tracks recipe variations across locations.
- Automated testing pipeline: How does each quantization level affect accuracy? Like their quality testing of ingredients before service.
- Deployment automation: How do you consistently deploy the right model format? Like their standardized opening procedures for all locations.
- Performance monitoring: Is the quantized model maintaining quality? Like managers who taste-test throughout the day.
Think of it this way: Rameshwaram doesn't just rely on skilled chefs; they have systems to ensure consistency. The batter must ferment for exactly the right time, the temperature of the tawa must be precisely controlled, and the portioning must be consistent across thousands of servings.
The traceability question is: "Can I reproduce and explain exactly how each model was optimized and deployed, just like how Rameshwaram can trace the preparation of every dish?"
Putting It All Together
AI model management isn't just some fancy ML DevOps term - it's the difference between running a world-famous restaurant chain like Rameshwaram Cafe and a chaotic food stall that can't handle the lunch rush.
The FACT framework gives you a simple way to think about it:
- Fidelity: Choose the right quality level, like Rameshwaram balances quality and volume
- Adaptability: Match quantization to hardware, like they match equipment to each location
- Cost: Optimize for specific requirements, like they customize menus for different branches
- Traceability: Build systems for consistency, like their standardized training and quality control
Next time someone asks you about your AI deployment strategy, you can confidently talk about how you're managing the FACT of the matter - and maybe suggest a trip to Rameshwaram Cafe to see these principles in delicious action!
What aspect of AI model management are you finding most challenging? Drop me a comment below - I'd love to hear about your experiences!