







































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)
































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)



















![Re-designing a Git/development workflow with best practices [closed]](https://i.postimg.cc/tRvBYcrt/branching-example.jpg)






















































































(1).jpg?#)































_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





























































































![The Material 3 Expressive redesign of Google Clock leaks out [Gallery]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2024/03/Google-Clock-v2.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)
![What Google Messages features are rolling out [May 2025]](https://i0.wp.com/9to5google.com/wp-content/uploads/sites/4/2023/12/google-messages-name-cover.png?resize=1200%2C628&quality=82&strip=all&ssl=1)












![New Apple iPad mini 7 On Sale for $399! [Lowest Price Ever]](https://www.iclarified.com/images/news/96096/96096/96096-640.jpg)
![Apple to Split iPhone Launches Across Fall and Spring in Major Shakeup [Report]](https://www.iclarified.com/images/news/97211/97211/97211-640.jpg)
![Apple to Move Camera to Top Left, Hide Face ID Under Display in iPhone 18 Pro Redesign [Report]](https://www.iclarified.com/images/news/97212/97212/97212-640.jpg)
![Apple Developing Battery Case for iPhone 17 Air Amid Battery Life Concerns [Report]](https://www.iclarified.com/images/news/97208/97208/97208-640.jpg)



























































































Enable Risk management with ML through Scalable Cloud-Native Data Management
Financial crimes are a persistent threat to financial institutions. Financial institutions have to build intelligent Risk management systems leveraging AI/ML which can defect and present malicious activities. Ability of computing power with the evolution of cloud computing has enabled leveraging machine learning(ML) for Risk management functions like anti money laundering. Data is the foundation of any machine learning project. One of key consideration is availability of high quality data as data quality plays a vital role in identifying and mitigating financial crimes. Why data quality is important => According to Gartner, organizations in the financial sector experience an average annual loss of $15 million due to poor data quality Data quality and integrity is a critical challenge 66% of banks struggle with data quality, gaps in important data points and some transaction flows not being captured at all What are possible data quality challenges :- Lack of data standardization across enterprise => Different systems across the enterprise may have data in various formats. For example, key data elements may have been defined using different data types across systems. This can cause issues in merging the data if required Accuracy and completeness => Data might not be complete or missing. If data is not complete then it can lead to issues in reporting which may lead to financial penalties If data updates may not be reflected across all systems it may lead to using incorrect data for compliance purposes Machine learning models may need data from past years which might not have been updated or may be in different formats What are ways to solve for these challenge : Define data management policies and enforcing the policies Enterprises can look to define data management policies to define standards on how datasets and data elements should be defined Technology investment With Onset of cloud computing, building cloud native solutions which can allow for data lineage tracking, real-time validation and anomaly detection Building an technology ecosystem to ensure adherence to data management policies throughout data life cycle Let's look at below reference architecture : Architecture components => Data Sources (Structured & Unstructured) Financial Transactions Customer & Credit Data Compliance Data External Feeds (Sanctions, Market Data, etc) Data Ingestion Layer AWS Glue / Apache Kafka for real-time ingestion AWS Lambda for event-driven processing Amazon S3 for raw data storage Data Processing & Quality Validation Databricks / AWS EMR for batch data processing Apache Spark for large-scale transformations Metadata & Data Lineage Management AWS Glue Data Catalog Data Storage & Warehousing Amazon Redshift / Snowflake for structured risk data Amazon S3 (Lakehouse Architecture) Data Lake Data Quality Monitoring & Alerts AWS CloudWatch / Prometheus for monitoring Custom dashboards using Amazon QuickSight / Power BI Risk & Compliance Reporting ML-powered anomaly detection for risk scoring Self-service analytics using Databricks SQL / AWS Athena Benefits of Cloud native solution => Accurate Data for Monitoring and Detection to ensure better data quality. This will enable accurate reporting for Compliance with Regulatory Requirements Seamless capture of metadata required for data management functions Efficient Risk Management through system controls avoid manual errors allowing key performers to focus on tasks requiring judgement Conclusion => Implementing cloud native solutions will integrate data management into the data lifecycle. This will benefit internal users as required data will be available to the users in an automated manner. Internal users can focus on data analysis required to complete regulatory reporting Improved data management will aid to reduce data quality errors which will enable machine learning/AI model development and adoption
Financial crimes are a persistent threat to financial institutions. Financial institutions have to build intelligent Risk management systems leveraging AI/ML which can defect and present malicious activities. Ability of computing power with the evolution of cloud computing has enabled leveraging machine learning(ML) for Risk management functions like anti money laundering.
Data is the foundation of any machine learning project. One of key consideration is availability of high quality data as data quality plays a vital role in identifying and mitigating financial crimes.
Why data quality is important =>
According to Gartner, organizations in the financial sector experience an average annual loss of $15 million due to poor data quality
Data quality and integrity is a critical challenge 66% of banks struggle with data quality, gaps in important data points and some transaction flows not being captured at all
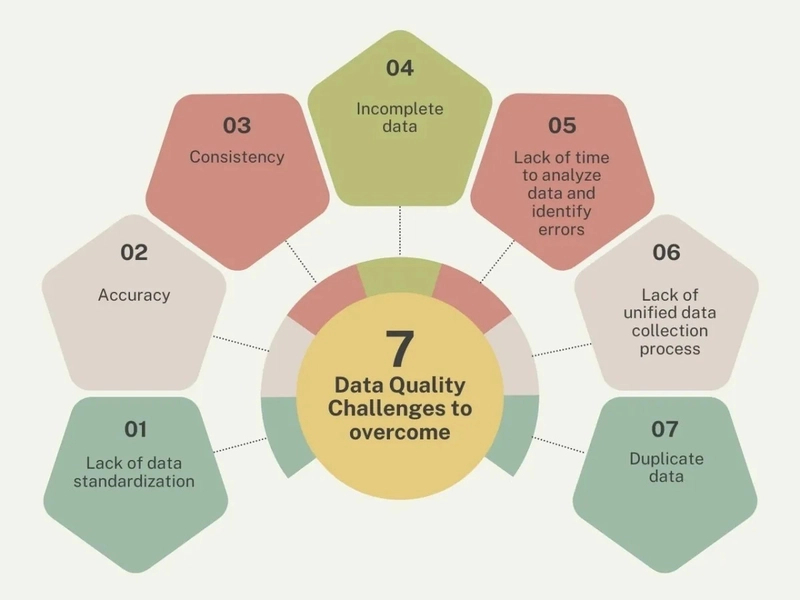
What are possible data quality challenges :-
Lack of data standardization across enterprise =>
Different systems across the enterprise may have data in various formats. For example, key data elements may have been defined using different data types across systems.
This can cause issues in merging the data if required
Accuracy and completeness =>
Data might not be complete or missing. If data is not complete then it can lead to issues in reporting which may lead to financial penalties
If data updates may not be reflected across all systems it may lead to using incorrect data for compliance purposes
Machine learning models may need data from past years which might not have been updated or may be in different formats
What are ways to solve for these challenge :
Define data management policies and enforcing the policies
Enterprises can look to define data management policies to define standards on how datasets and data elements should be defined
Technology investment
With Onset of cloud computing, building cloud native solutions which can allow for data lineage tracking, real-time validation and anomaly detection
Building an technology ecosystem to ensure adherence to data management policies throughout data life cycle
Let's look at below reference architecture :

Architecture components =>
Data Sources (Structured & Unstructured)
- Financial Transactions
- Customer & Credit Data
- Compliance Data
- External Feeds (Sanctions, Market Data, etc)
Data Ingestion Layer
- AWS Glue / Apache Kafka for real-time ingestion
- AWS Lambda for event-driven processing
- Amazon S3 for raw data storage
Data Processing & Quality Validation
- Databricks / AWS EMR for batch data processing
- Apache Spark for large-scale transformations
Metadata & Data Lineage Management
- AWS Glue Data Catalog
Data Storage & Warehousing
- Amazon Redshift / Snowflake for structured risk data
- Amazon S3 (Lakehouse Architecture)
- Data Lake
Data Quality Monitoring & Alerts
- AWS CloudWatch / Prometheus for monitoring
- Custom dashboards using Amazon QuickSight / Power BI
Risk & Compliance Reporting
- ML-powered anomaly detection for risk scoring
- Self-service analytics using Databricks SQL / AWS Athena
Benefits of Cloud native solution =>
Accurate Data for Monitoring and Detection to ensure better data quality. This will enable accurate reporting for Compliance with Regulatory Requirements
Seamless capture of metadata required for data management functions
Efficient Risk Management through system controls avoid manual errors allowing key performers to focus on tasks requiring judgement
Conclusion =>
Implementing cloud native solutions will integrate data management into the data lifecycle. This will benefit internal users as required data will be available to the users in an automated manner. Internal users can focus on data analysis required to complete regulatory reporting
Improved data management will aid to reduce data quality errors which will enable machine learning/AI model development and adoption


