











































































































































































![[The AI Show Episode 147]: OpenAI Abandons For-Profit Plan, AI College Cheating Epidemic, Apple Says AI Will Replace Search Engines & HubSpot’s AI-First Scorecard](https://www.marketingaiinstitute.com/hubfs/ep%20147%20cover.png)

























![How to Enable Remote Access on Windows 10 [Allow RDP]](https://bigdataanalyticsnews.com/wp-content/uploads/2025/05/remote-access-windows.jpg)


































































































































































![Legends Reborn tier list of best heroes for each class [May 2025]](https://media.pocketgamer.com/artwork/na-33360-1656320479/pg-magnum-quest-fi-1.jpeg?#)































































-Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)





























































































![Apple using sketchy warning for apps bought using third-party payment systems [Updated]](https://i0.wp.com/9to5mac.com/wp-content/uploads/sites/6/2025/05/Apple-using-scary-looking-warning-for-apps-bought-using-third-party-payment-systems.jpg?resize=1200%2C628&quality=82&strip=all&ssl=1)




















![Watch Aston Martin and Top Gear Show Off Apple CarPlay Ultra [Video]](https://www.iclarified.com/images/news/97336/97336/97336-640.jpg)



























































































Efficient Cache Design with Bloom Filters in Go
In cache design, we often encounter a troublesome problem: a large number of “invalid queries” put tremendous pressure on the database. For example, when a user requests data that doesn’t exist, we typically query the database, which returns “not found.” If there are many such requests, the database gets busy handling these meaningless queries, affecting system performance. So, is there a way to know in advance whether data “might exist” before querying? This is where Bloom filters come into play. Problems in Traditional Cache Scenarios Imagine the following scenario: Our system has a cache layer (Redis) and a database layer (MySQL). When a user requests some data, we first check the cache. If it’s a cache hit, we return the result directly. If the data isn’t in the cache, we query the database. If the database doesn’t have it either, we return “not found” to the user. At first glance, this design seems reasonable. But in practice, you may encounter a large number of invalid queries: User requests data with ID=99999999 -> Not found in cache -> Query database for ID=99999999 -> Database returns: not found If users repeatedly request data that simply doesn’t exist, you end up with: Cache not working: Every request queries the database, making the cache layer pointless. Excessive database load: Numerous invalid requests slow down database response. A common optimization is to filter out invalid queries in advance, so data that we already know doesn’t exist is returned immediately, without querying the database. This is exactly where Bloom filters shine. What is a Bloom Filter? A Bloom filter is an efficient set-membership query algorithm. It can quickly determine whether a value might exist or definitely does not exist. Simply put: If the Bloom filter tells you “does not exist,” then it truly doesn’t exist, and you can return an error right away—no need to query the database. If the Bloom filter tells you “might exist,” then you query the database for confirmation. The underlying logic of a Bloom filter is simple: Use multiple hash functions to map data into a fixed-size bit array. When querying, compute the same hashes for the target data and check if all the corresponding bits are set to 1. If any of those bits are 0, the data definitely does not exist. If all bits are 1, the data might exist (with a certain false positive rate). Advantages: Saves memory—occupies less space than a traditional hash table. Fast queries—time complexity close to O(1). Efficient filtering—reduces database pressure. Disadvantages: Possible false positives (but the false positive rate can be reduced by tuning the number of hash functions). Cannot delete data (generally used for big data streams or cache scenarios). The Data Structure of a Bloom Filter The core data structures of a Bloom filter are two components: Bit array: Used to record whether a certain value exists; all bits are initialized to 0. Multiple hash functions: Used to calculate the bit positions corresponding to the data. Example: Insert "Leap"; after hash calculations, it maps to positions 2, 5, 8, and 9 in the bit array: Index: 0 1 2 3 4 5 6 7 8 9 Value: 0 0 1 0 0 1 0 0 1 1 When querying "Leap": Calculate the hashes for "Leap" and find that positions 2, 5, 8, and 9 are all 1, indicating it might exist. Calculate the hashes for "cell" and find some bits are 0, so it’s immediately returned as “does not exist”. Implementing a Bloom Filter in Go Below is a Bloom filter implementation using Go: The BloomFilter struct. The constructor NewBloomFilter, which automatically calculates the optimal bit array size (m) and number of hash functions (k) based on the expected number of elements and the acceptable false positive rate. The constructor NewBloomFilterWithMK, which allows you to specify m and k directly. The Add method, for adding elements. The MightContain method, for checking whether an element might exist (there may be false positives, but never false negatives). The internal getHashes method, which uses double hashing to generate k hash values. Here, we use two variants of the FNV-1a hash algorithm as base hashes. Bloom Filter Structure package main import ( "fmt" "hash/fnv" ) // Bloom filter struct type BloomFilter struct { m uint64 // Size of bit array (number of bits) k uint64 // Number of hash functions bits []byte // Bit array } // Create a Bloom filter func NewBloomFilter(expectedN uint64, falsePositiveRate float64) *BloomFilter { m, k := estimateParameters(expectedN, falsePositiveRate) if m == 0 || k == 0 { panic("Invalid parameters for Bloom filter: m or k is zero") } return NewBloomFilterWithMK(m, k) } // estimateParameters calculates the optimal m and k based on the expected number of elements n and the false positive rate p // m = - (n * ln(p)) / (ln(2))^2 // k = (m / n) * l

In cache design, we often encounter a troublesome problem: a large number of “invalid queries” put tremendous pressure on the database. For example, when a user requests data that doesn’t exist, we typically query the database, which returns “not found.” If there are many such requests, the database gets busy handling these meaningless queries, affecting system performance. So, is there a way to know in advance whether data “might exist” before querying? This is where Bloom filters come into play.
Problems in Traditional Cache Scenarios
Imagine the following scenario:
- Our system has a cache layer (Redis) and a database layer (MySQL).
- When a user requests some data, we first check the cache. If it’s a cache hit, we return the result directly.
- If the data isn’t in the cache, we query the database. If the database doesn’t have it either, we return “not found” to the user.
At first glance, this design seems reasonable. But in practice, you may encounter a large number of invalid queries:
User requests data with ID=99999999
-> Not found in cache
-> Query database for ID=99999999
-> Database returns: not found
If users repeatedly request data that simply doesn’t exist, you end up with:
- Cache not working: Every request queries the database, making the cache layer pointless.
- Excessive database load: Numerous invalid requests slow down database response.
A common optimization is to filter out invalid queries in advance, so data that we already know doesn’t exist is returned immediately, without querying the database. This is exactly where Bloom filters shine.
What is a Bloom Filter?
A Bloom filter is an efficient set-membership query algorithm. It can quickly determine whether a value might exist or definitely does not exist. Simply put:
- If the Bloom filter tells you “does not exist,” then it truly doesn’t exist, and you can return an error right away—no need to query the database.
- If the Bloom filter tells you “might exist,” then you query the database for confirmation.
The underlying logic of a Bloom filter is simple:
- Use multiple hash functions to map data into a fixed-size bit array.
- When querying, compute the same hashes for the target data and check if all the corresponding bits are set to 1.
- If any of those bits are 0, the data definitely does not exist.
- If all bits are 1, the data might exist (with a certain false positive rate).
Advantages:
- Saves memory—occupies less space than a traditional hash table.
- Fast queries—time complexity close to O(1).
- Efficient filtering—reduces database pressure.
Disadvantages:
- Possible false positives (but the false positive rate can be reduced by tuning the number of hash functions).
- Cannot delete data (generally used for big data streams or cache scenarios).
The Data Structure of a Bloom Filter
The core data structures of a Bloom filter are two components:
- Bit array: Used to record whether a certain value exists; all bits are initialized to 0.
- Multiple hash functions: Used to calculate the bit positions corresponding to the data.
Example:
Insert "Leap"; after hash calculations, it maps to positions 2, 5, 8, and 9 in the bit array:
Index: 0 1 2 3 4 5 6 7 8 9
Value: 0 0 1 0 0 1 0 0 1 1
When querying "Leap":
- Calculate the hashes for "Leap" and find that positions 2, 5, 8, and 9 are all 1, indicating it might exist.
- Calculate the hashes for "cell" and find some bits are 0, so it’s immediately returned as “does not exist”.
Implementing a Bloom Filter in Go
Below is a Bloom filter implementation using Go:
- The
BloomFilterstruct. - The constructor
NewBloomFilter, which automatically calculates the optimal bit array size (m) and number of hash functions (k) based on the expected number of elements and the acceptable false positive rate. - The constructor
NewBloomFilterWithMK, which allows you to specify m and k directly. - The
Addmethod, for adding elements. - The
MightContainmethod, for checking whether an element might exist (there may be false positives, but never false negatives). - The internal
getHashesmethod, which uses double hashing to generate k hash values. Here, we use two variants of the FNV-1a hash algorithm as base hashes.
Bloom Filter Structure
package main
import (
"fmt"
"hash/fnv"
)
// Bloom filter struct
type BloomFilter struct {
m uint64 // Size of bit array (number of bits)
k uint64 // Number of hash functions
bits []byte // Bit array
}
// Create a Bloom filter
func NewBloomFilter(expectedN uint64, falsePositiveRate float64) *BloomFilter {
m, k := estimateParameters(expectedN, falsePositiveRate)
if m == 0 || k == 0 {
panic("Invalid parameters for Bloom filter: m or k is zero")
}
return NewBloomFilterWithMK(m, k)
}
// estimateParameters calculates the optimal m and k based on the expected number of elements n and the false positive rate p
// m = - (n * ln(p)) / (ln(2))^2
// k = (m / n) * ln(2)
func estimateParameters(n uint64, p float64) (m uint64, k uint64) {
if n == 0 || p <= 0 || p >= 1 {
return 1000, 10
}
mFloat := -(float64(n) * math.Log(p)) / (math.Ln2 * math.Ln2)
kFloat := (mFloat / float64(n)) * math.Ln2
m = uint64(math.Ceil(mFloat))
k = uint64(math.Ceil(kFloat))
if k < 1 {
k = 1
}
return
}
// NewBloomFilterWithMK creates a Bloom filter using the specified m and k
func NewBloomFilterWithMK(m, k uint64) *BloomFilter {
if m == 0 || k == 0 {
panic("Invalid parameters for Bloom filter: m or k is zero")
}
numBytes := (m + 7) / 8
return &BloomFilter{
m: m,
k: k,
bits: make([]byte, numBytes),
}
}
// getHashes uses double hashing to generate k hash values for the data
func (bf *BloomFilter) getHashes(data []byte) []uint64 {
hashes := make([]uint64, bf.k)
// Use two different versions (or seeds) of FNV-1a as base hash functions
h1 := fnv.New64()
h1.Write(data)
hash1Val := h1.Sum64()
h2 := fnv.New64a()
h2.Write(data)
hash2Val := h2.Sum64()
for i := uint64(0); i < bf.k; i++ {
if hash2Val == 0 && i > 0 {
hash2Val = 1
}
hashes[i] = (hash1Val + i*hash2Val) % bf.m
}
return hashes
}
Inserting Data
// Insert data into the Bloom filter
func (bf *BloomFilter) Add(data []byte) {
hashes := bf.getHashes(data)
for _, h := range hashes {
byteIndex := h / 8 // Find the byte index
bitOffset := h % 8 // Find the bit offset within the byte
bf.bits[byteIndex] |= (1 << bitOffset) // Set the corresponding position to 1
}
}
Querying Data
// Check whether data might exist
func (bf *BloomFilter) MightContain(data []byte) bool {
hashes := bf.getHashes(data)
for _, h := range hashes {
byteIndex := h / 8
bitOffset := h % 8
if (bf.bits[byteIndex] & (1 << bitOffset)) == 0 {
// If any bit corresponding to a hash is 0, the element definitely does not exist
return false
}
}
// If all bits corresponding to hashes are 1, the element might exist
return true
}
Resetting the Bloom Filter
// Reset clears the Bloom filter (sets all bits to 0)
func (bf *BloomFilter) Reset() {
for i := range bf.bits {
bf.bits[i] = 0
}
}
Test Code
func main() {
// Example: expect 1000 elements, false positive rate 1%
expectedN := uint64(1000)
falsePositiveRate := 0.01
m, k := estimateParameters(expectedN, falsePositiveRate)
fmt.Printf("Estimated parameters: m = %d, k = %d\n", m, k)
bf := NewBloomFilter(expectedN, falsePositiveRate)
// Or bf := NewBloomFilterWithMK(m, k)
// Add some elements
item1 := []byte("apple")
item2 := []byte("banana")
item3 := []byte("cherry")
bf.Add(item1)
bf.Add(item2)
fmt.Printf("MightContain 'apple': %t\n", bf.MightContain(item1)) // true
fmt.Printf("MightContain 'banana': %t\n", bf.MightContain(item2)) // true
fmt.Printf("MightContain 'cherry': %t\n", bf.MightContain(item3)) // false (should be false, as it wasn't added)
fmt.Printf("MightContain 'grape': %t\n", bf.MightContain([]byte("grape"))) // false (should also be false)
bf.Reset()
fmt.Println("After Reset:")
fmt.Printf("MightContain 'apple': %t\n", bf.MightContain(item1)) // false
}
Summary
A Bloom filter can help us in cache systems by:
- Reducing invalid database queries: first judge whether the data might exist, to avoid directly accessing the database.
- Saving storage space: uses less memory than hash tables, suitable for large-scale data.
- Improving query efficiency: O(1) time complexity for queries, no need to traverse the entire dataset.
We used Go to implement a simple Bloom filter, applying it to cache scenarios to optimize database load.
We are Leapcell, your top choice for hosting Go projects.

Leapcell is the Next-Gen Serverless Platform for Web Hosting, Async Tasks, and Redis:
Multi-Language Support
- Develop with Node.js, Python, Go, or Rust.
Deploy unlimited projects for free
- pay only for usage — no requests, no charges.
Unbeatable Cost Efficiency
- Pay-as-you-go with no idle charges.
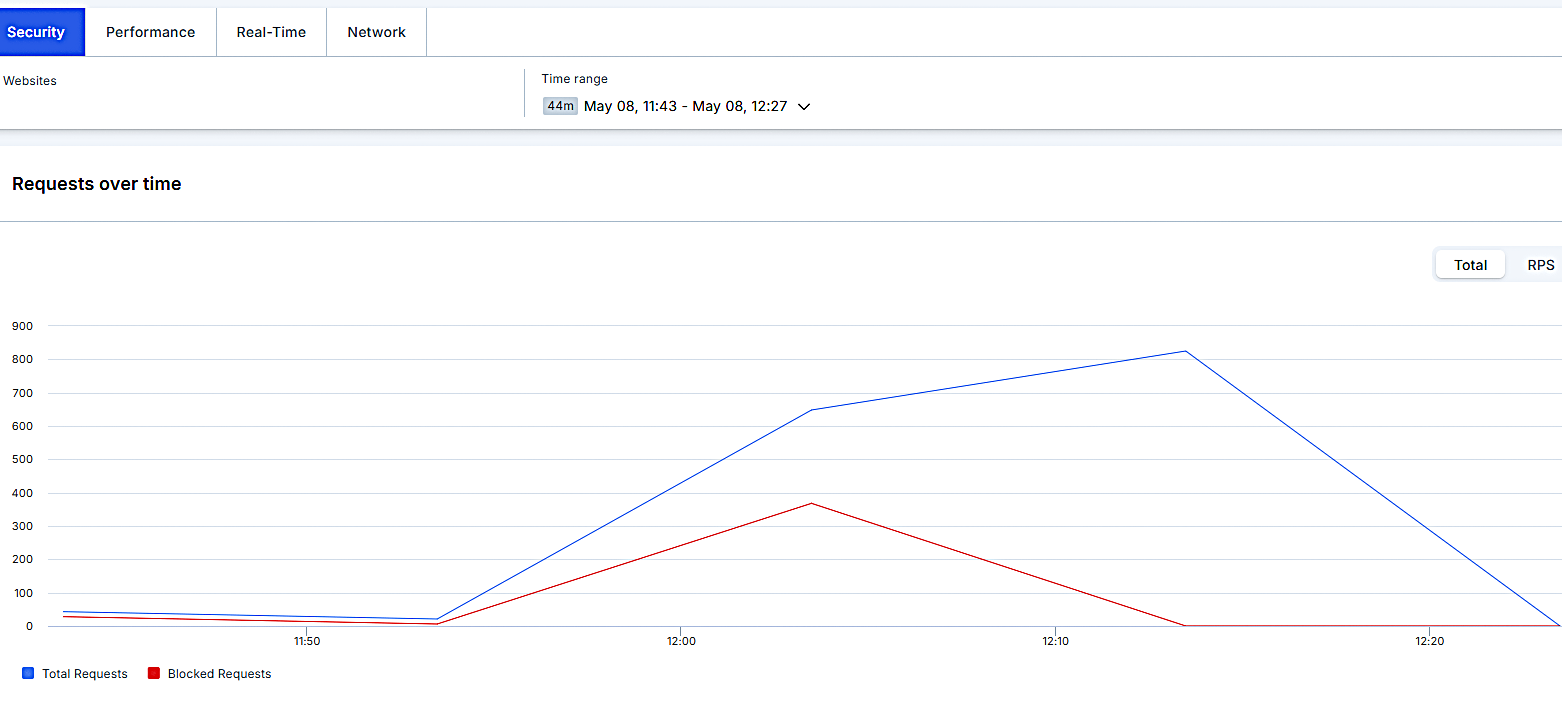
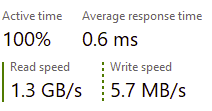
- Example: $25 supports 6.94M requests at a 60ms average response time.
Streamlined Developer Experience
- Intuitive UI for effortless setup.
- Fully automated CI/CD pipelines and GitOps integration.
- Real-time metrics and logging for actionable insights.
Effortless Scalability and High Performance
- Auto-scaling to handle high concurrency with ease.
- Zero operational overhead — just focus on building.
Explore more in the Documentation!

Follow us on X: @LeapcellHQ



