![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)











































































































































































.jpg?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)






















































































_Olekcii_Mach_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
















































































































![Most iPhones Sold in the U.S. Will Be Made in India by 2026 [Report]](https://www.iclarified.com/images/news/97130/97130/97130-640.jpg)
![Apple to Shift Robotics Unit From AI Division to Hardware Engineering [Report]](https://www.iclarified.com/images/news/97128/97128/97128-640.jpg)

























































































































Document Loading, Parsing, and Cleaning in AI Applications
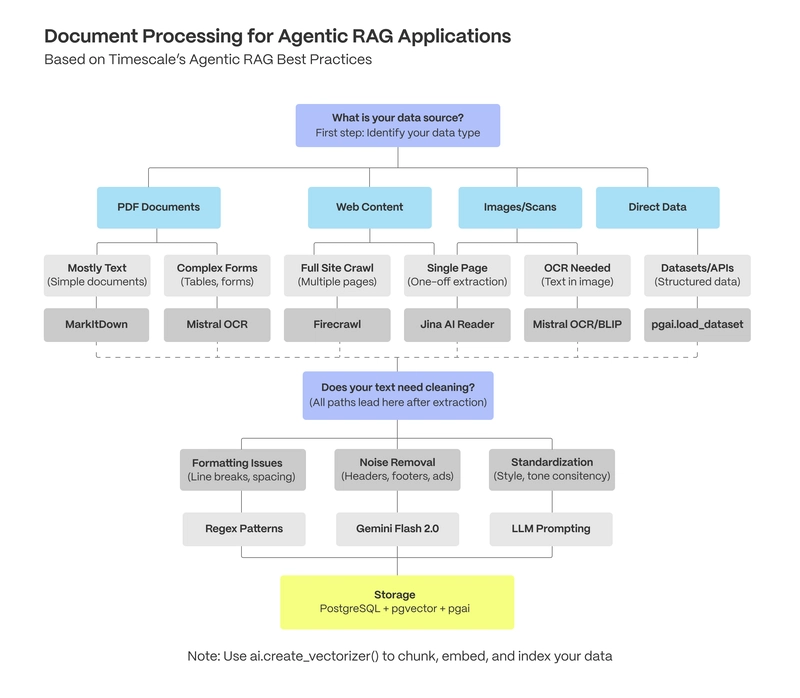
Welcome to part one of our Agentic RAG Best Practices series, where we cover how to load, parse, and clean documents for your agentic applications. This comprehensive guide will teach you how to build effective agentic retrieval applications with PostgreSQL. Every week, customers ask us about building AI applications. Their most pressing concern isn't advanced chunking strategies or vector databases—it's simply: "How do I clean my data before feeding it to my AI?" It’s simple: “Garbage in, garbage out.” Before worrying about writing even your first line of embeddings or retrieval code, you need clean data. In this first guide of our agentic RAG series, we'll cover gathering the right data, extracting text from various document types, pulling valuable metadata, web scraping techniques, and effectively storing data in PostgreSQL. We'll address common challenges like fixing formatting issues and handling images in documents. By the end, you'll know how to transform raw documents into clean, structured data that retrieval agents can effectively use. Don’t want to read all of this and just want to apply it? We have prepared a handy dandy preparation checklist for this topic in a preparation checklist. One fintech customer recently shared how they spent weeks fine-tuning their RAG application with different vector databases, only to realize their poor results stemmed from simply having dirty data. "I approached the whole thing with like, I don't trust these AIs (. … ) So we don't ask them to make decisions. We do normal modeling to figure out what the user needs, then feed that data to the LLM and just say, 'Summarize it.'" The garbage in, garbage out principle applies strongly to AI applications. Let's explore how to properly load, parse, and clean your data for AI use. Gathering the Right Data for AI Applications
Welcome to part one of our Agentic RAG Best Practices series, where we cover how to load, parse, and clean documents for your agentic applications.
This comprehensive guide will teach you how to build effective agentic retrieval applications with PostgreSQL.
Every week, customers ask us about building AI applications. Their most pressing concern isn't advanced chunking strategies or vector databases—it's simply: "How do I clean my data before feeding it to my AI?"
It’s simple: “Garbage in, garbage out.”
Before worrying about writing even your first line of embeddings or retrieval code, you need clean data.
In this first guide of our agentic RAG series, we'll cover gathering the right data, extracting text from various document types, pulling valuable metadata, web scraping techniques, and effectively storing data in PostgreSQL. We'll address common challenges like fixing formatting issues and handling images in documents.
By the end, you'll know how to transform raw documents into clean, structured data that retrieval agents can effectively use.
Don’t want to read all of this and just want to apply it? We have prepared a handy dandy preparation checklist for this topic in a preparation checklist.
One fintech customer recently shared how they spent weeks fine-tuning their RAG application with different vector databases, only to realize their poor results stemmed from simply having dirty data. "I approached the whole thing with like, I don't trust these AIs (. … ) So we don't ask them to make decisions. We do normal modeling to figure out what the user needs, then feed that data to the LLM and just say, 'Summarize it.'"
The garbage in, garbage out principle applies strongly to AI applications. Let's explore how to properly load, parse, and clean your data for AI use.
Gathering the Right Data for AI Applications