

























































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)






















































































































































































































































-All-will-be-revealed-00-35-05.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)


















































































































![What iPhone 17 model are you most excited to see? [Poll]](https://9to5mac.com/wp-content/uploads/sites/6/2025/04/iphone-17-pro-sky-blue.jpg?quality=82&strip=all&w=290&h=145&crop=1)
















![Hands-On With 'iPhone 17 Air' Dummy Reveals 'Scary Thin' Design [Video]](https://www.iclarified.com/images/news/97100/97100/97100-640.jpg)
![Mike Rockwell is Overhauling Siri's Leadership Team [Report]](https://www.iclarified.com/images/news/97096/97096/97096-640.jpg)
![Instagram Releases 'Edits' Video Creation App [Download]](https://www.iclarified.com/images/news/97097/97097/97097-640.jpg)
![Inside Netflix's Rebuild of the Amsterdam Apple Store for 'iHostage' [Video]](https://www.iclarified.com/images/news/97095/97095/97095-640.jpg)



















































































































Web Scraping with Playwright in Python
This tutorial shows how to scrape online store pages using Playwright in Python and save the data to a file. As a bonus, you'll see how to generate code from your actions. Install Playwright and Dependencies The script requires Python 3.7 or higher. To install Playwright, run this in your terminal or command line: pip install playwright This installs the library, but not the browsers. To add them, run: playwright install After that, you can use Chromium, Firefox, and WebKit. Step 1: Minimal Working Example (MWE) Here’s a minimal example to launch a browser and extract the page title: from playwright.sync_api import sync_playwright def main(): with sync_playwright() as p: browser = p.chromium.launch(headless=True) page = browser.new_page() page.goto('https://www.amazon.com/ ') print(page.content()) browser.close() if __name__ == "__main__": main() We'll build on this to turn it into a scraper. Step 2: Navigating to Product Page Replace the URL with the actual product search page: page.goto('https://www.amazon.com/b?node=283155') Add a wait for the product card selector to make sure the page is fully loaded before scraping: page.wait_for_selector('.a-column') Waiting for a selector is better than using fixed timeouts, as it waits exactly as long as needed, no more, no less. Step 3: Extracting Product Data Now let’s go on how to extract the data. Locate Elements First, we need to find the selectors for the elements we want. Go to the Amazon search page and use DevTools (F12 or right-click and Inspect) to check the HTML structure. Here’s a quick reference table of the elements we need: Element CSS Selector XPath Product container div.a-column //div[@class="a-column"] Product image img.p13n-product-image //img[contains(@class, "p13n-product-image")] Product title div.p13n-sc-truncate-desktop-type2 //div[contains(@class, "p13n-sc-truncate-desktop-type2")] Rating (stars) i.a-icon-star-small > span.a-icon-alt //i[contains(@class, "a-icon-star-small")]/span[@class="a-icon-alt"] Number of ratings span.a-size-small (inside rating block) //div[@class="a-icon-row"]/span[@class="a-size-small"] One last thing: scraping e-commerce sites like Amazon can be difficult. They often use dynamic class names and change their layout regularly. Try to rely on stable IDs or the structure of elements rather than specific class names. Scrape the Data Create a variable to store the scraped data: product_data = [] Next, scrape the data from elements using their selectors: product = page.query_selector('.a-cardui') title = product.query_selector('.p13n-sc-truncate-desktop-type2').inner_text() rating = product.query_selector('.a-icon-alt').inner_text() reviews_count = product.query_selector('.a-size-small').inner_text() image_url = product.query_selector('img').get_attribute('src') Add it all to the list: product_data.append({ 'title': title, 'rating': rating, 'reviews_count': reviews_count, 'image_url': image_url }) You can print this data, save it, or process it further. Step 5: Scraping Multiple Products The code above works for just one product – the first one. To scrape all products on the page, use a loop: for product in products: # Here your code To avoid saving empty or invalid items, filter them a bit: title = product.query_selector('.p13n-sc-truncate-desktop-type2') if title: rating = product.query_selector('.a-icon-alt') reviews_count = product.query_selector('.a-size-small') image = product.query_selector('img') product_data.append({ 'title': title.inner_text() if title else None, 'rating': rating.inner_text() if rating else None, 'reviews_count': reviews_count.inner_text() if reviews_count else None, 'image_url': image.get_attribute('src') if image else None }) Now you’ll get a clean list of products and skip over anything that’s missing data or just looks like a product card but isn’t. Step 6: Exporting Data to JSON Finally, save the result to a file. JSON is a good choice – easy to read and use later: with open('product_data.json', 'w', encoding='utf-8') as f: json.dump(product_data, f, ensure_ascii=False, indent=2) If you need to export to something like a database or Excel, you can use the pandas library. TL;DR Here’s the full script, don’t forget to change the URL to the one you need: import json from playwright.sync_api import sync_playwright def main(): with sync_playwright() as p: browser =
This tutorial shows how to scrape online store pages using Playwright in Python and save the data to a file. As a bonus, you'll see how to generate code from your actions.
Install Playwright and Dependencies
The script requires Python 3.7 or higher. To install Playwright, run this in your terminal or command line:
pip install playwright
This installs the library, but not the browsers. To add them, run:
playwright install
After that, you can use Chromium, Firefox, and WebKit.
Step 1: Minimal Working Example (MWE)
Here’s a minimal example to launch a browser and extract the page title:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://www.amazon.com/ ')
print(page.content())
browser.close()
if __name__ == "__main__":
main()
We'll build on this to turn it into a scraper.
Step 2: Navigating to Product Page
Replace the URL with the actual product search page:
page.goto('https://www.amazon.com/b?node=283155')
Add a wait for the product card selector to make sure the page is fully
loaded before scraping:
page.wait_for_selector('.a-column')
Waiting for a selector is better than using fixed timeouts, as it waits exactly as long as needed, no more, no less.
Step 3: Extracting Product Data
Now let’s go on how to extract the data.
Locate Elements
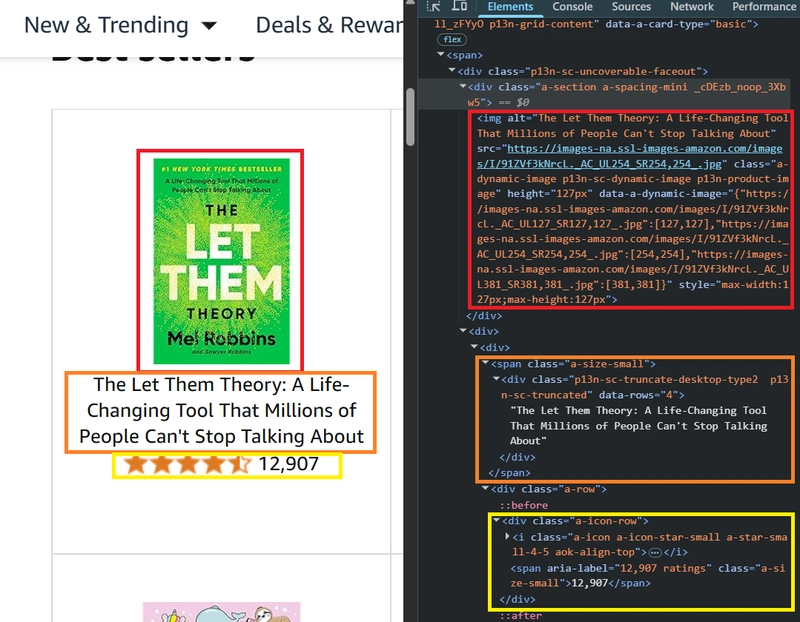
First, we need to find the selectors for the elements we want. Go to the Amazon search page and use DevTools (F12 or right-click and Inspect) to check the HTML structure.
Here’s a quick reference table of the elements we need:
| Element | CSS Selector | XPath |
|---|---|---|
| Product container | div.a-column |
//div[@class="a-column"] |
| Product image | img.p13n-product-image |
//img[contains(@class, "p13n-product-image")] |
| Product title | div.p13n-sc-truncate-desktop-type2 |
//div[contains(@class, "p13n-sc-truncate-desktop-type2")] |
| Rating (stars) | i.a-icon-star-small > span.a-icon-alt |
//i[contains(@class, "a-icon-star-small")]/span[@class="a-icon-alt"] |
| Number of ratings |
span.a-size-small (inside rating block) |
//div[@class="a-icon-row"]/span[@class="a-size-small"] |
One last thing: scraping e-commerce sites like Amazon can be difficult. They often use dynamic class names and change their layout regularly. Try to rely on stable IDs or the structure of elements rather than specific class names.
Scrape the Data
Create a variable to store the scraped data:
product_data = []
Next, scrape the data from elements using their selectors:
product = page.query_selector('.a-cardui')
title = product.query_selector('.p13n-sc-truncate-desktop-type2').inner_text()
rating = product.query_selector('.a-icon-alt').inner_text()
reviews_count = product.query_selector('.a-size-small').inner_text()
image_url = product.query_selector('img').get_attribute('src')
Add it all to the list:
product_data.append({
'title': title,
'rating': rating,
'reviews_count': reviews_count,
'image_url': image_url
})
You can print this data, save it, or process it further.
Step 5: Scraping Multiple Products
The code above works for just one product – the first one. To scrape all products on the page, use a loop:
for product in products:
# Here your code
To avoid saving empty or invalid items, filter them a bit:
title = product.query_selector('.p13n-sc-truncate-desktop-type2')
if title:
rating = product.query_selector('.a-icon-alt')
reviews_count = product.query_selector('.a-size-small')
image = product.query_selector('img')
product_data.append({
'title': title.inner_text() if title else None,
'rating': rating.inner_text() if rating else None,
'reviews_count': reviews_count.inner_text() if reviews_count else None,
'image_url': image.get_attribute('src') if image else None
})
Now you’ll get a clean list of products and skip over anything that’s missing data or just looks like a product card but isn’t.
Step 6: Exporting Data to JSON
Finally, save the result to a file. JSON is a good choice – easy to read and use later:
with open('product_data.json', 'w', encoding='utf-8') as f:
json.dump(product_data, f, ensure_ascii=False, indent=2)
If you need to export to something like a database or Excel, you can use the pandas library.
TL;DR
Here’s the full script, don’t forget to change the URL to the one you need:
import json
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
page = browser.new_page()
page.goto('https://www.amazon.com/b?node=283155')
page.wait_for_selector('.a-column')
product_data = []
products = page.query_selector_all('.a-column')
for product in products:
title = product.query_selector('.p13n-sc-truncate-desktop-type2')
if title:
rating = product.query_selector('.a-icon-alt')
reviews_count = product.query_selector('.a-size-small')
image = product.query_selector('img')
product_data.append({
'title': title.inner_text() if title else None,
'rating': rating.inner_text() if rating else None,
'reviews_count': reviews_count.inner_text() if reviews_count else None,
'image_url': image.get_attribute('src') if image else None
})
with open('product_data.json', 'w', encoding='utf-8') as f:
json.dump(product_data, f, ensure_ascii=False, indent=2)
browser.close()
if __name__ == "__main__":
main()
If the script doesn’t work, double-check the selectors, they can change over time for security reasons.
Bonus: Record Actions into Code with Playwright Codegen
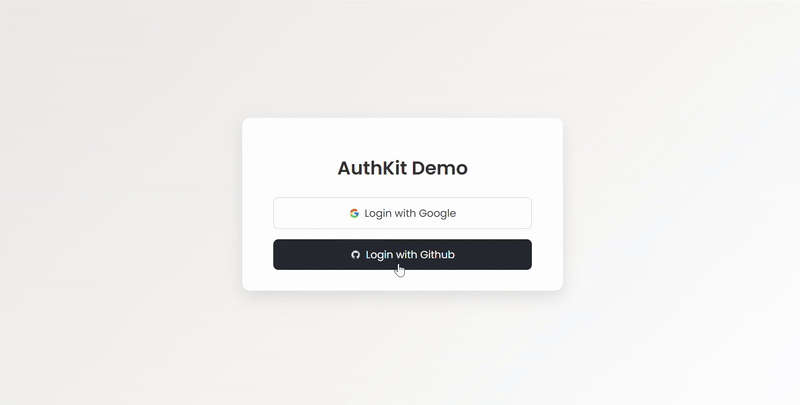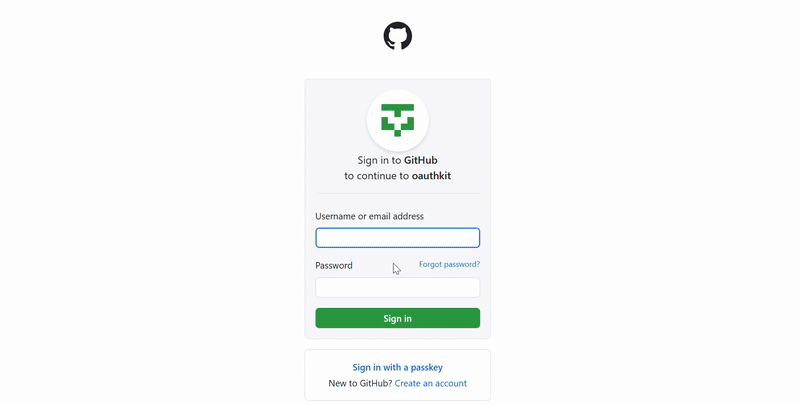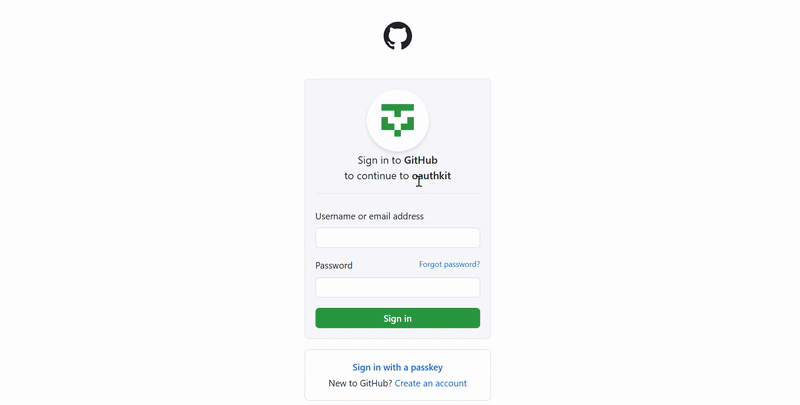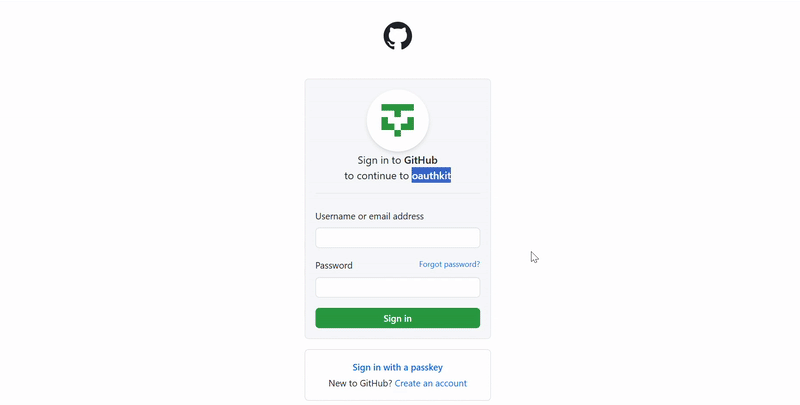
If you're not too confident with coding or just want to speed things up, Playwright has a built-in tool called codegen that helps generate code based on your actions. Just run:
playwright codegen https://www.amazon.com
This will launch a web driver:
And open the Playwright Inspector:
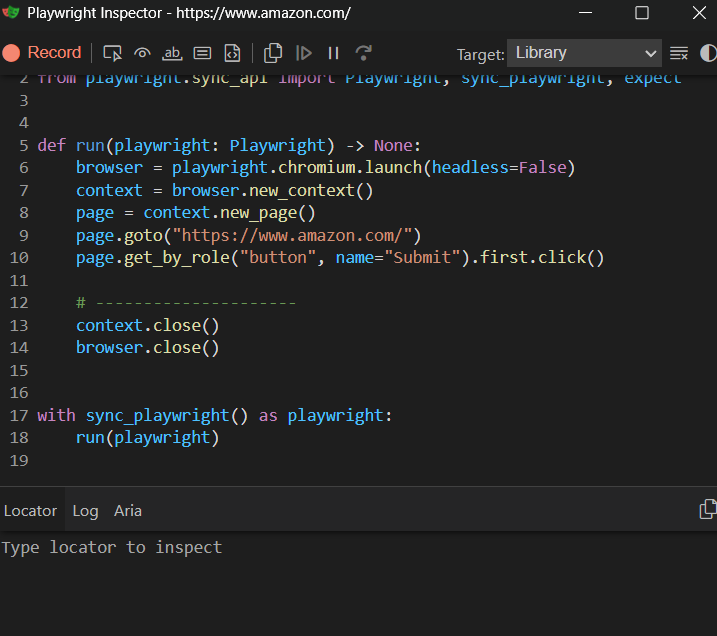
You probably won’t build a full scraper with codegen alone, but it’s a handy tool to use alongside manual coding.