














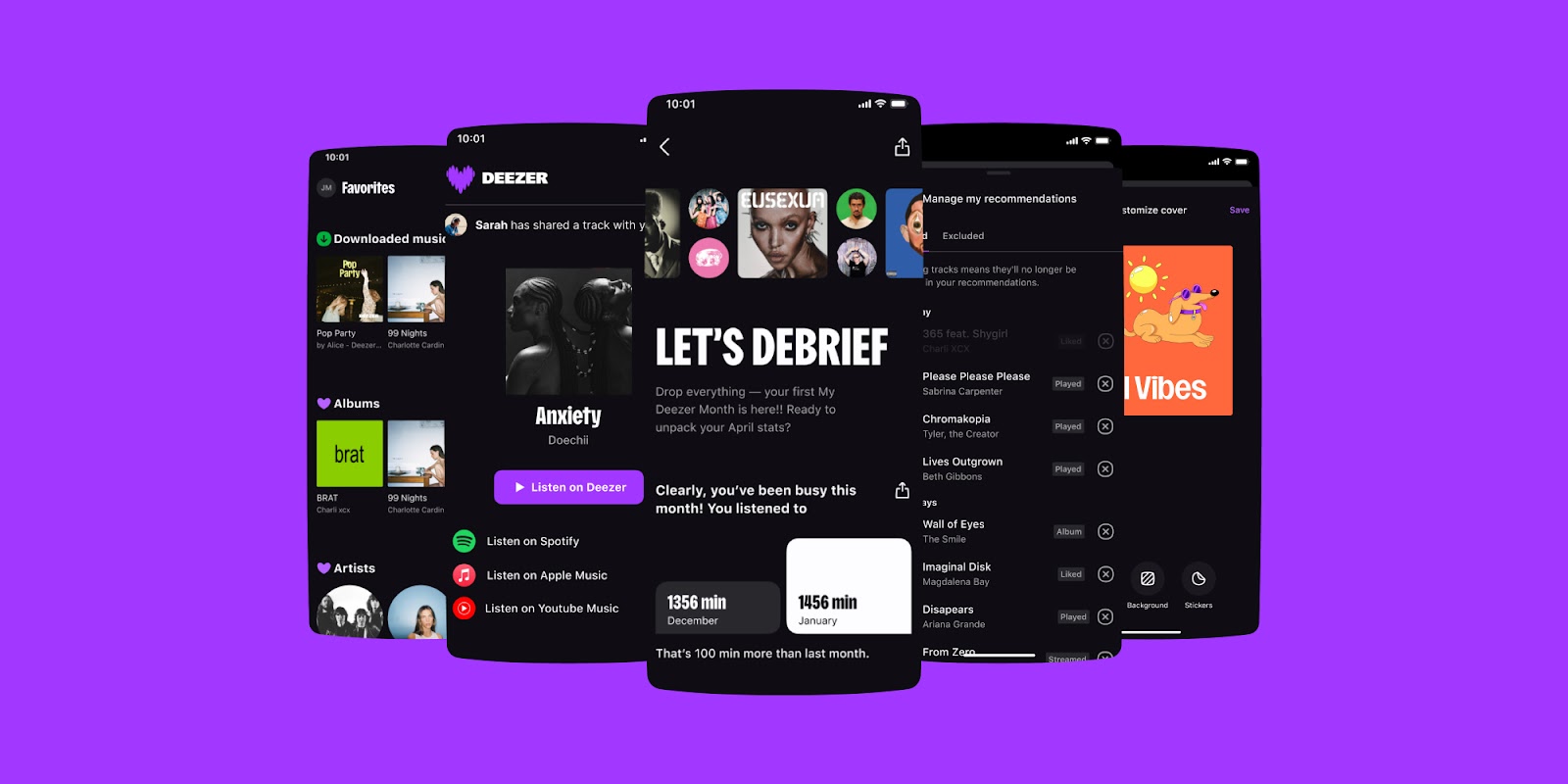


























































































































































![[The AI Show Episode 144]: ChatGPT’s New Memory, Shopify CEO’s Leaked “AI First” Memo, Google Cloud Next Releases, o3 and o4-mini Coming Soon & Llama 4’s Rocky Launch](https://www.marketingaiinstitute.com/hubfs/ep%20144%20cover.png)















































































































![Pet Projects That Got You Hired (C++ Edition) [closed]](https://cdn.sstatic.net/Sites/softwareengineering/Img/apple-touch-icon@2.png?v=1ef7363febba)






















































































![GrandChase tier list of the best characters available [April 2025]](https://media.pocketgamer.com/artwork/na-33057-1637756796/grandchase-ios-android-3rd-anniversary.jpg?#)












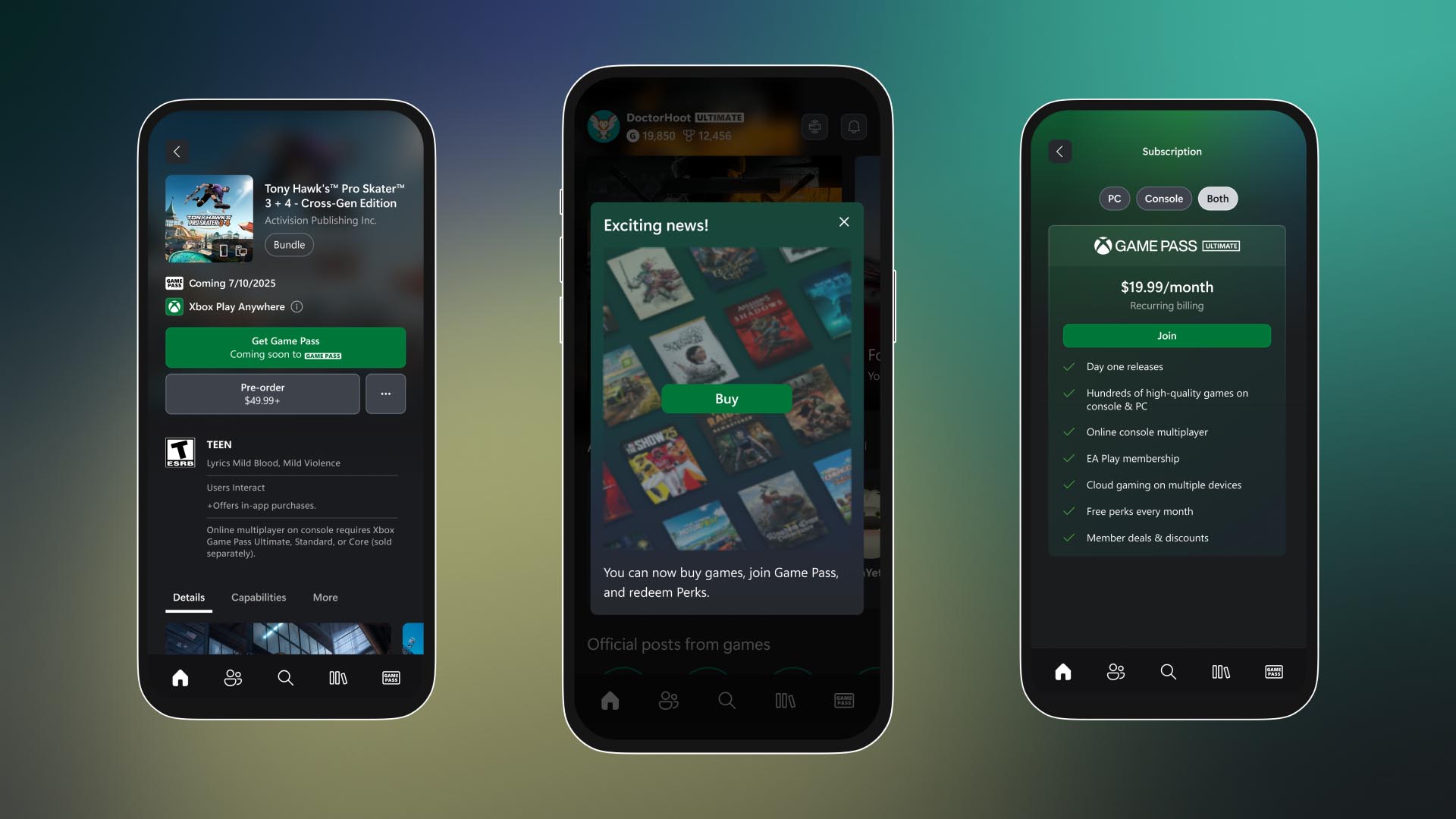































.png?width=1920&height=1920&fit=bounds&quality=70&format=jpg&auto=webp#)






































































































![Global security vulnerability database gets 11 more months of funding [u]](https://photos5.appleinsider.com/gallery/63338-131616-62453-129471-61060-125967-51013-100774-49862-97722-Malware-Image-xl-xl-xl-(1)-xl-xl.jpg)






















![Apple M4 13-inch iPad Pro On Sale for $200 Off [Deal]](https://www.iclarified.com/images/news/97056/97056/97056-640.jpg)
![Apple Shares New 'Mac Does That' Ads for MacBook Pro [Video]](https://www.iclarified.com/images/news/97055/97055/97055-640.jpg)

![Apple Releases tvOS 18.4.1 for Apple TV [Download]](https://www.iclarified.com/images/news/97047/97047/97047-640.jpg)


















































































































Cost Comparison: Databricks Cluster Jobs vs. SQL Warehouse for Batch Processing
1. Introduction Batch processing is a fundamental component of data engineering, allowing businesses to process large volumes of data efficiently. Databricks offers multiple compute options for batch workloads, but choosing the right one can significantly impact cost, performance, and overall efficiency. Two common choices for running batch jobs in Databricks are Cluster Jobs and SQL Warehouse. While both options provide scalability and reliability, they come with different pricing models, resource allocations, and execution behaviors. Selecting the most cost-effective solution requires understanding their strengths and trade-offs. This article compares Databricks Cluster Jobs and SQL Warehouse, evaluating their cost-effectiveness for batch processing. By the end, you’ll have a clearer understanding of which compute option best suits your workload and budget. 2. Understanding Databricks Compute Options Databricks provides multiple compute options tailored for different workloads. Choosing the right option depends on factors such as workload type, scalability needs, and cost considerations. Databricks Cluster Jobs Databricks Cluster Jobs run on standard compute clusters and are ideal for general-purpose batch processing, including ETL pipelines and machine learning workloads. Key features include: Supports notebooks, scripts, and workflows, making it flexible for various data processing tasks. Can scale dynamically with autoscaling, allowing efficient resource utilization. Supports spot instances and cluster policies to optimize cost and governance. SQL Warehouse Databricks SQL Warehouse is designed specifically for SQL-based workloads and provides a managed compute layer optimized for querying large datasets. Key characteristics include: Runs in three modes: Serverless Mode – Fully managed, Databricks handles infrastructure and auto-scaling. Pro Mode – Uses dedicated clusters, giving more control over configurations. Classic Mode – The legacy option with manual cluster management, but fewer optimizations compared to Pro Mode. Ideal for analytics and reporting workloads requiring high concurrency and fast query execution. Cost is based on DBU (Databricks Unit) pricing and the selected warehouse tier, making it more predictable for SQL-heavy processing. Understanding these compute options is crucial for selecting the most efficient and cost-effective solution for batch processing in Databricks. Performance & Use Case Considerations Databricks Cluster Jobs Best for complex ETL/ELT workflows involving Python, Scala, or R. Suitable for data engineering pipelines requiring heavy transformations. Provides more control over tuning, caching, and parallel execution. SQL Warehouse Best for SQL-based transformations (CTEs, aggregations, analytics). Better suited for BI/analytics workloads that require fast query performance. Can be more expensive for long-running transformations due to DBU-based pricing. Use Case: Evaluating Compute Options for Large SQL Queries Initial Considerations To evaluate the best compute option for running complex SQL queries in Databricks, we tested a query involving multiple joins on tables exceeding 1TB in size. The query was initially executed using a X-Small Serverless SQL Warehouse in Databricks, with the following setup: The query was run in a dedicated warehouse to avoid bottlenecks from other workloads. Only one node was used (no auto-scaling). Execution time: ~10 minutes. Minimum time to terminate the instance after each execution: ~5 minutes. This job runs once every two hours, totaling 12 executions per day, equating to 3 hours of Serverless Warehouse usage daily. What We Tested To compare performance and cost-effectiveness, we tested three compute options: X-Small Serverless SQL Warehouse Jobs Compute Without Photon (r6id.xlarge, 16 CPUs, 128GB RAM, no autoscaling) Jobs Compute With Photon (r6id.xlarge, 16 CPUs, 128GB RAM, no autoscaling) Results 1) X-Small Serverless SQL Warehouse Execution Time: ~10 minutes Run Mode: Executed directly in the Databricks console Minimum Warehouse Tear-down Time: 5 minutes after query execution Total Compute Time per Execution: 15 minutes 2) Jobs Compute Without Photon Instance Type: r6id.xlarge (16 CPUs, 128GB RAM) Execution Time: ~23 minutes Instance Setup Time: ~5 minutes Tear-down Time:
1. Introduction
Batch processing is a fundamental component of data engineering, allowing businesses to process large volumes of data efficiently. Databricks offers multiple compute options for batch workloads, but choosing the right one can significantly impact cost, performance, and overall efficiency.
Two common choices for running batch jobs in Databricks are Cluster Jobs and SQL Warehouse. While both options provide scalability and reliability, they come with different pricing models, resource allocations, and execution behaviors. Selecting the most cost-effective solution requires understanding their strengths and trade-offs.
This article compares Databricks Cluster Jobs and SQL Warehouse, evaluating their cost-effectiveness for batch processing. By the end, you’ll have a clearer understanding of which compute option best suits your workload and budget.
2. Understanding Databricks Compute Options
Databricks provides multiple compute options tailored for different workloads. Choosing the right option depends on factors such as workload type, scalability needs, and cost considerations.
Databricks Cluster Jobs
Databricks Cluster Jobs run on standard compute clusters and are ideal for general-purpose batch processing, including ETL pipelines and machine learning workloads. Key features include:
- Supports notebooks, scripts, and workflows, making it flexible for various data processing tasks.
- Can scale dynamically with autoscaling, allowing efficient resource utilization.
- Supports spot instances and cluster policies to optimize cost and governance.
SQL Warehouse
Databricks SQL Warehouse is designed specifically for SQL-based workloads and provides a managed compute layer optimized for querying large datasets. Key characteristics include:
- Runs in three modes:
- Serverless Mode – Fully managed, Databricks handles infrastructure and auto-scaling.
- Pro Mode – Uses dedicated clusters, giving more control over configurations.
- Classic Mode – The legacy option with manual cluster management, but fewer optimizations compared to Pro Mode.
- Ideal for analytics and reporting workloads requiring high concurrency and fast query execution.
- Cost is based on DBU (Databricks Unit) pricing and the selected warehouse tier, making it more predictable for SQL-heavy processing.
Understanding these compute options is crucial for selecting the most efficient and cost-effective solution for batch processing in Databricks.
Performance & Use Case Considerations
Databricks Cluster Jobs
- Best for complex ETL/ELT workflows involving Python, Scala, or R.
- Suitable for data engineering pipelines requiring heavy transformations.
- Provides more control over tuning, caching, and parallel execution.
SQL Warehouse
- Best for SQL-based transformations (CTEs, aggregations, analytics).
- Better suited for BI/analytics workloads that require fast query performance.
- Can be more expensive for long-running transformations due to DBU-based pricing.
Use Case: Evaluating Compute Options for Large SQL Queries
Initial Considerations
To evaluate the best compute option for running complex SQL queries in Databricks, we tested a query involving multiple joins on tables exceeding 1TB in size. The query was initially executed using a X-Small Serverless SQL Warehouse in Databricks, with the following setup:
- The query was run in a dedicated warehouse to avoid bottlenecks from other workloads.
- Only one node was used (no auto-scaling).
- Execution time: ~10 minutes.
- Minimum time to terminate the instance after each execution: ~5 minutes.
- This job runs once every two hours, totaling 12 executions per day, equating to 3 hours of Serverless Warehouse usage daily.
What We Tested
To compare performance and cost-effectiveness, we tested three compute options:
- X-Small Serverless SQL Warehouse
- Jobs Compute Without Photon (r6id.xlarge, 16 CPUs, 128GB RAM, no autoscaling)
- Jobs Compute With Photon (r6id.xlarge, 16 CPUs, 128GB RAM, no autoscaling)
Results
1) X-Small Serverless SQL Warehouse
- Execution Time: ~10 minutes
- Run Mode: Executed directly in the Databricks console
- Minimum Warehouse Tear-down Time: 5 minutes after query execution
- Total Compute Time per Execution: 15 minutes
2) Jobs Compute Without Photon
- Instance Type: r6id.xlarge (16 CPUs, 128GB RAM)
- Execution Time: ~23 minutes
- Instance Setup Time: ~5 minutes
- Tear-down Time: <1 minute
- Total Compute Time per Execution: ~28 minutes
3) Jobs Compute With Photon
- Instance Type: r6id.xlarge (16 CPUs, 128GB RAM)
- Execution Time: ~10 minutes
- Instance Setup Time: ~5 minutes
- Tear-down Time: <1 minute
- Total Compute Time per Execution: ~15 minutes
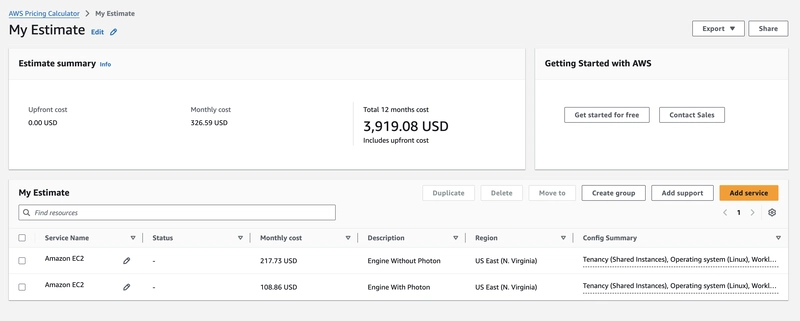
AWS Prices
This prices were calculated based on the time that the instances were up and running for both
Performance & Cost Comparison
| Engine | Execution Time | Price for Each Execution | Executions a Day | Days | Price AWS Monthly | Total Price Monthly |
|---|---|---|---|---|---|---|
| Jobs Compute With Photon | 15 minutes | $0.475161 | 12 | 30 | $108.86 | $279.92 |
| Jobs Compute Without Photon | 27 minutes | $0.56112 | 12 | 30 | $217.73 | $419.73 |
| X-Small Serverless SQL Warehouse | 15 minutes | $1.377465 | 12 | 30 | $0 | $495.89 |
Summary
This analysis provides insights into the cost and performance of different Databricks compute options for batch processing:
- Jobs Compute With Photon is the most cost-effective option, costing $279.92 per month with a 15-minute execution time. Photon significantly improves performance while keeping costs lower than the other options.
- Jobs Compute Without Photon increases execution time to 27 minutes and has a higher total monthly cost of $419.73. This is due to both Databricks execution pricing and additional AWS instance costs.
- X-Small Serverless SQL Warehouse achieves the same 15-minute execution time as the Photon job but at a significantly higher cost of $495.89 per month due to Databricks' serverless pricing model.
Key Takeaways
- Photon optimizations significantly lower costs and execution time, making Jobs Compute With Photon the best option for this workload.
- Serverless SQL Warehouse, while convenient, is the most expensive option due to Databricks’ pricing model. AWS costs are included in the Databricks pricing for Serverless, which explains the $0 AWS Monthly cost in the table.
- Jobs Compute Without Photon is both slower and more expensive than the Photon version, making it the least efficient choice. This conclusion is based on a use case involving a huge query with multiple joins. Simpler queries are not considered in this use case and must be reevaluated separately.
When to Choose Each Option
- Use Serverless SQL Warehouse if you need simplicity and minimal infrastructure management, as Databricks handles all scaling and maintenance.
- Use Jobs Compute With Photon for cost-efficient, high-performance workloads, particularly if your SQL queries benefit from Photon's vectorized execution and query optimizations.
- Use Jobs Compute Without Photon only if your workload does not benefit from Photon optimizations or if specific constraints prevent you from using it.
This comparison highlights how choosing the right compute option can lead to significant cost savings without sacrificing performance.



