![[The AI Show Episode 143]: ChatGPT Revenue Surge, New AGI Timelines, Amazon’s AI Agent, Claude for Education, Model Context Protocol & LLMs Pass the Turing Test](https://www.marketingaiinstitute.com/hubfs/ep%20143%20cover.png)











































































































































































































































































_Muhammad_R._Fakhrurrozi_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)
_NicoElNino_Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)











































































































![Apple Releases iOS 18.5 Beta 4 and iPadOS 18.5 Beta 4 [Download]](https://www.iclarified.com/images/news/97145/97145/97145-640.jpg)
![Apple Seeds watchOS 11.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97147/97147/97147-640.jpg)
![Apple Seeds visionOS 2.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97150/97150/97150-640.jpg)
![Apple Seeds tvOS 18.5 Beta 4 to Developers [Download]](https://www.iclarified.com/images/news/97153/97153/97153-640.jpg)






























































































Building a Smarter Way to Explore Next.js Docs: My Weekend with Semantic Search + RAG
Introduction This past weekend, fueled by curiosity and the "learn by doing" mantra, I embarked on a mission: to build a more intelligent way to navigate the vast landscape of the Next.js documentation. The result? An AI-powered semantic search and Retrieval-Augmented Generation (RAG) tool specifically designed for the official Next.js docs. The Problem with Simple Keyword Search We've all experienced the frustration of sifting through numerous search results, many only tangentially related to our actual query. Traditional keyword-based search often struggles with understanding the nuances of language and the context of our questions. This is particularly true for complex documentation like that of a powerful framework like Next.js. My Solution: Semantic Search + RAG To tackle this, I decided to leverage the power of semantic search and Retrieval-Augmented Generation (RAG). Here's the core idea: Semantic Search: Instead of just matching keywords, the system understands the meaning behind your question. This allows for more relevant results, even if your query doesn't use the exact terminology present in the documentation. Retrieval-Augmented Generation (RAG): Once relevant documentation snippets are found, a language model uses this context to generate a more informed and accurate answer to your question, complete with citations. Diving into the Implementation Here's a peek under the hood at the technologies and processes involved: 1. Populating the Knowledge Base: The first crucial step was to ingest and process the Next.js documentation. This involved: Fetching Navigation Links: I started by scraping the main Next.js documentation page to extract all the links to individual documentation pages. Crawling and Extracting Content: For each of these links, I used CheerioWebBaseLoader to fetch the content of the page. Chunking the Text: Large documents were split into smaller, manageable chunks using RecursiveCharacterTextSplitter. This is important for efficient embedding and retrieval. Generating Embeddings: The heart of semantic search! I used GoogleGenerativeAIEmbeddings to create vector embeddings for each chunk of the documentation. These embeddings capture the semantic meaning of the text. Storing in a Vector Database: The generated embeddings were stored in Chroma, an efficient vector store that allows for fast similarity searches. import { Chroma } from "@langchain/community/vectorstores/chroma"; import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters"; import { GoogleGenerativeAIEmbeddings } from "@langchain/google-genai"; import { load } from "cheerio"; import "dotenv/config"; import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio"; import { Document } from "@langchain/core/documents"; const embeddings = new GoogleGenerativeAIEmbeddings({ model: "models/text-embedding-004", apiKey: process.env.GOOGLE_API_KEY, }); const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: 1000, chunkOverlap: 200, }); const vectorStore = new Chroma(embeddings, { collectionName: "next-js-docs", }); export async function PopulateDatabase() { const navs = await GetNavLinks(); if (!Array.isArray(navs) || navs.length < 0) { throw new Error("Failed to populate database"); } // const testNavs = navs.slice(0, 3); const testNavs = navs.slice(1, 375) for (let index = 0; index < testNavs.length; index++) { const i = testNavs[index]; try { console.info( `
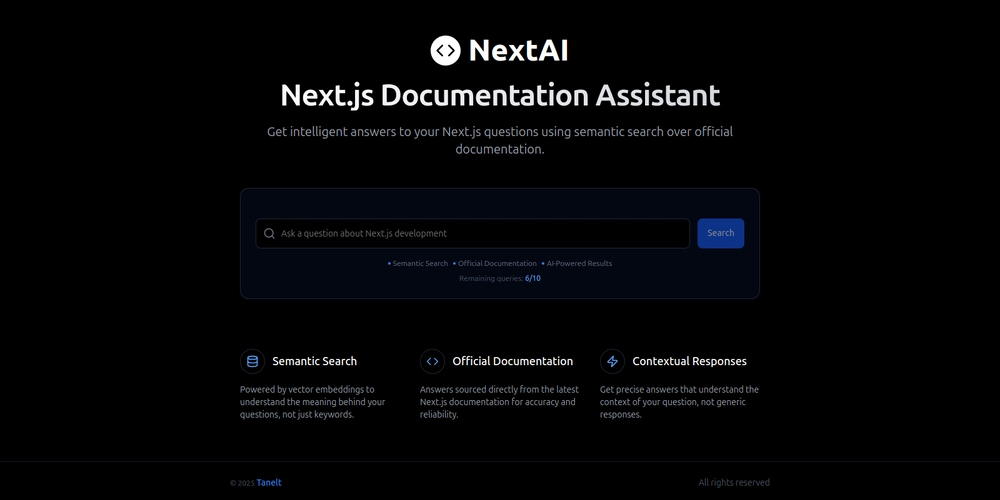
Introduction
This past weekend, fueled by curiosity and the "learn by doing" mantra, I embarked on a mission: to build a more intelligent way to navigate the vast landscape of the Next.js documentation. The result? An AI-powered semantic search and Retrieval-Augmented Generation (RAG) tool specifically designed for the official Next.js docs.
The Problem with Simple Keyword Search
We've all experienced the frustration of sifting through numerous search results, many only tangentially related to our actual query. Traditional keyword-based search often struggles with understanding the nuances of language and the context of our questions. This is particularly true for complex documentation like that of a powerful framework like Next.js.
My Solution: Semantic Search + RAG
To tackle this, I decided to leverage the power of semantic search and Retrieval-Augmented Generation (RAG). Here's the core idea:
Semantic Search: Instead of just matching keywords, the system understands the meaning behind your question. This allows for more relevant results, even if your query doesn't use the exact terminology present in the documentation.
Retrieval-Augmented Generation (RAG): Once relevant documentation snippets are found, a language model uses this context to generate a more informed and accurate answer to your question, complete with citations.
Diving into the Implementation
Here's a peek under the hood at the technologies and processes involved:
1. Populating the Knowledge Base:
The first crucial step was to ingest and process the Next.js documentation. This involved:
Fetching Navigation Links: I started by scraping the main Next.js documentation page to extract all the links to individual documentation pages.
Crawling and Extracting Content: For each of these links, I used CheerioWebBaseLoader to fetch the content of the page.
Chunking the Text: Large documents were split into smaller, manageable chunks using RecursiveCharacterTextSplitter. This is important for efficient embedding and retrieval.
Generating Embeddings: The heart of semantic search! I used GoogleGenerativeAIEmbeddings to create vector embeddings for each chunk of the documentation. These embeddings capture the semantic meaning of the text.
Storing in a Vector Database: The generated embeddings were stored in Chroma, an efficient vector store that allows for fast similarity searches.
import { Chroma } from "@langchain/community/vectorstores/chroma";
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
import { GoogleGenerativeAIEmbeddings } from "@langchain/google-genai";
import { load } from "cheerio";
import "dotenv/config";
import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio";
import { Document } from "@langchain/core/documents";
const embeddings = new GoogleGenerativeAIEmbeddings({
model: "models/text-embedding-004",
apiKey: process.env.GOOGLE_API_KEY,
});
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const vectorStore = new Chroma(embeddings, {
collectionName: "next-js-docs",
});
export async function PopulateDatabase() {
const navs = await GetNavLinks();
if (!Array.isArray(navs) || navs.length < 0) {
throw new Error("Failed to populate database");
}
// const testNavs = navs.slice(0, 3);
const testNavs = navs.slice(1, 375)
for (let index = 0; index < testNavs.length; index++) {
const i = testNavs[index];
try {
console.info(
`