








































































































































































![[The AI Show Episode 145]: OpenAI Releases o3 and o4-mini, AI Is Causing “Quiet Layoffs,” Executive Order on Youth AI Education & GPT-4o’s Controversial Update](https://www.marketingaiinstitute.com/hubfs/ep%20145%20cover.png)
































































































































![From Art School Drop-out to Microsoft Engineer with Shashi Lo [Podcast #170]](https://cdn.hashnode.com/res/hashnode/image/upload/v1746203291209/439bf16b-c820-4fe8-b69e-94d80533b2df.png?#)





































































































(1).jpg?#)
































_Inge_Johnsson-Alamy.jpg?width=1280&auto=webp&quality=80&disable=upscale#)









































































































![Apple to Split iPhone Launches Across Fall and Spring in Major Shakeup [Report]](https://www.iclarified.com/images/news/97211/97211/97211-640.jpg)
![Apple to Move Camera to Top Left, Hide Face ID Under Display in iPhone 18 Pro Redesign [Report]](https://www.iclarified.com/images/news/97212/97212/97212-640.jpg)
![Apple Developing Battery Case for iPhone 17 Air Amid Battery Life Concerns [Report]](https://www.iclarified.com/images/news/97208/97208/97208-640.jpg)
![AirPods 4 On Sale for $99 [Lowest Price Ever]](https://www.iclarified.com/images/news/97206/97206/97206-640.jpg)






























![[Updated] Samsung’s 65-inch 4K Smart TV Just Crashed to $299 — That’s Cheaper Than an iPad](https://www.androidheadlines.com/wp-content/uploads/2025/05/samsung-du7200.jpg)






























































Building a Scalable and Resilient Architecture on AWS
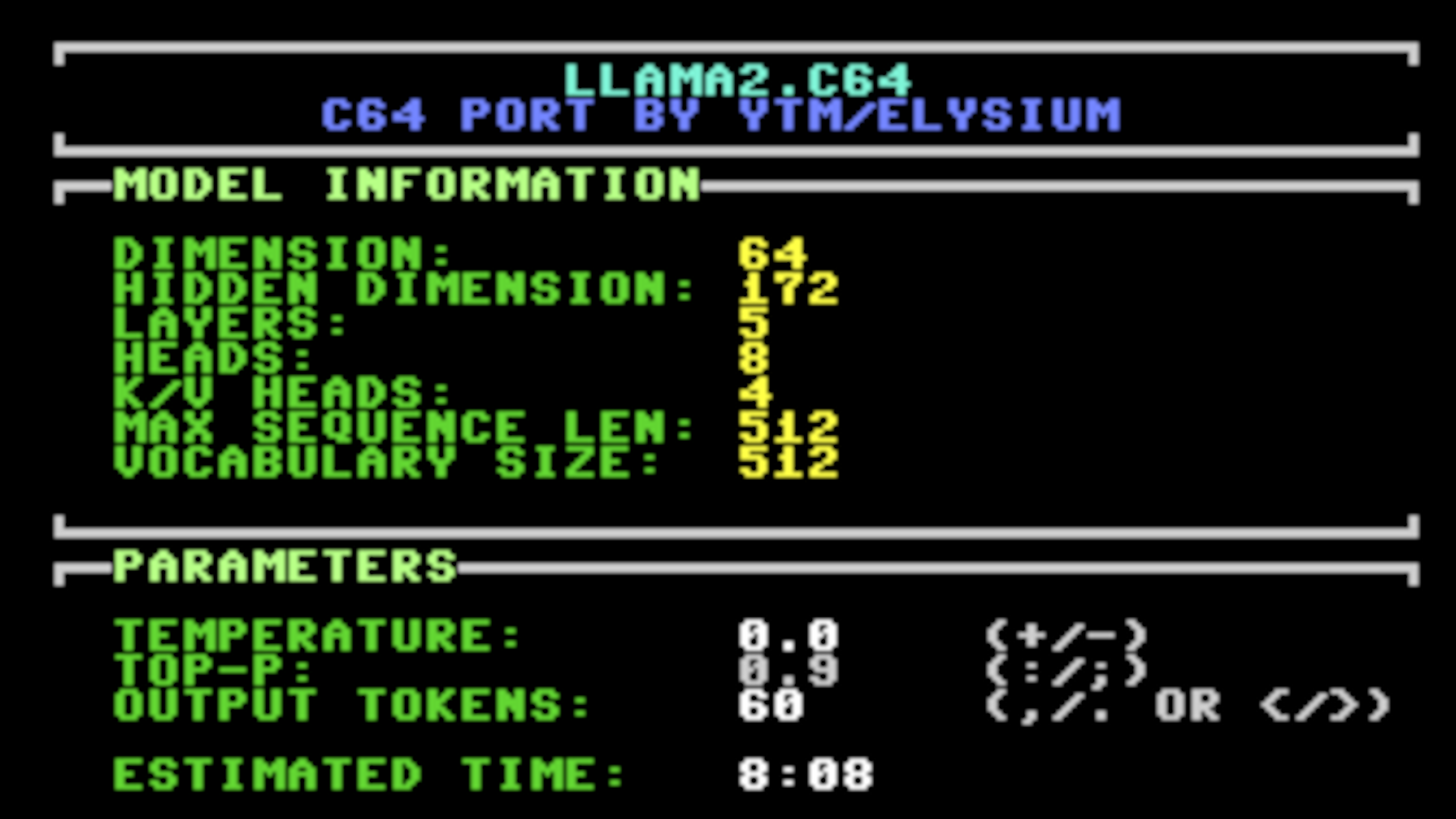
Creating a large-scale system is a complex challenge that often requires first-principles thinking. To design an architecture that supports client needs effectively, it’s important to start with simplicity and evolve toward a more robust and reliable system over time. Many companies begin with overly complex architectures, but in my view, it’s best to start simple and iteratively build upon it—adapting and scaling as requirements grow. VPC The foundation is a robust Virtual Private Cloud (VPC) architecture, including: A three-tier setup (Public, Application, Database) across three Availability Zones (AZs) Public subnets with Internet Gateway access Security Groups to control traffic between layers High availability through multi-AZ deployment IPv4 and IPv6 support EFS for shared storage Integrated monitoring via CloudWatch Single Server Setup – EC2 Initially, I would start with a monolithic application deployed in the public subnet. For example, a WordPress instance capable of handling the early traffic. However, if this instance is stopped, it receives a new public IP, causing users to lose access. More critically, both data and files can be lost—something we must avoid from the beginning. Database A key early step is to decouple the data layer by deploying a managed database in the DB subnets. This not only isolates application logic from data but also lays the groundwork for scalability. Additionally, databases can be further configured for robustness: Database Replication We can start with basic replication—distributing data across multiple instances and configuring regular snapshots for backup and recovery. Vertical vs. Horizontal Scaling While vertical scaling (upgrading to a larger instance) can be a quick fix, horizontal scaling (adding more instances) is typically preferred for large-scale systems due to the hard limits of vertical growth. Load Balancers Relying on a single server for all incoming traffic is not sustainable at scale. Introducing an Application Load Balancer (ALB) helps distribute traffic across multiple instances, improving availability and performance. Cache Caching is essential to reduce load on databases and improve response times. AWS services like ElastiCache (Redis/Memcached) can be used to cache expensive queries or frequently accessed data. Additionally, caching can be applied at: The frontend (e.g., static resources) API level (API Gateway Caching) I typically use cache for non-volatile content, but care must be taken to prevent serving stale data. Content Delivery Network (CDN) To optimize performance for global users, a CDN like CloudFront can serve content from edge locations closest to the user. One caveat: caching introduces complexity, such as stale content. Fortunately, CloudFront allows explicit cache invalidation—whether by resource path (e.g., /resources/*) or individual files. Configurations Use AWS Systems Manager Parameter Store to externalize configurations. For example, by storing your configuration data in an external service like Parameter Store, you can easily launch new servers that retrieve and use the same configurations—making it simple to replicate environments and scale consistently. Stateless Architecture Stateless applications make scaling easier. Each instance can serve requests independently, so if one fails, another can take over seamlessly. In contrast, stateful applications (like the initial monolith) create dependencies that hinder fault tolerance and scaling. Event-Driven Architecture To improve decoupling and resilience, I prefer asynchronous communication using messaging systems: SQS for point-to-point queues SQS Developer Guide SNS for publish-subscribe scenarios SNS Developer Guide This allows components to recover gracefully if others are temporarily unavailable—avoiding ripple effects that can crash the system. Observability A scalable system must be observable. AWS Lambda provides this by default with: Logging Metrics Tracing These capabilities enable you to monitor system health, debug issues, and make informed scaling decisions. Metrics can also feed into Auto Scaling Group (ASG) policies. More on AWS Lambda Auto Scaling With observability in place, the next step is implementing Auto Scaling—defining policies that trigger scale-out or scale-in actions. These policies can be based on: CPU usage Memory pressure Network traffic Time-based patterns (e.g., predictable peak hours) Conclusion Building a highly scalable and resilient application in AWS is challenging but achievable. You can start with a simple, monolithic architecture and progressively evolve it to handle millions of users. Along the way, keep these resilience patterns in mind: Minimize integration points Prevent cascading failures Avoid

Creating a large-scale system is a complex challenge that often requires first-principles thinking. To design an architecture that supports client needs effectively, it’s important to start with simplicity and evolve toward a more robust and reliable system over time.
Many companies begin with overly complex architectures, but in my view, it’s best to start simple and iteratively build upon it—adapting and scaling as requirements grow.
VPC
The foundation is a robust Virtual Private Cloud (VPC) architecture, including:
- A three-tier setup (Public, Application, Database) across three Availability Zones (AZs)
- Public subnets with Internet Gateway access
- Security Groups to control traffic between layers
- High availability through multi-AZ deployment
- IPv4 and IPv6 support
- EFS for shared storage
- Integrated monitoring via CloudWatch
Single Server Setup – EC2
Initially, I would start with a monolithic application deployed in the public subnet. For example, a WordPress instance capable of handling the early traffic. However, if this instance is stopped, it receives a new public IP, causing users to lose access. More critically, both data and files can be lost—something we must avoid from the beginning.
Database
A key early step is to decouple the data layer by deploying a managed database in the DB subnets. This not only isolates application logic from data but also lays the groundwork for scalability. Additionally, databases can be further configured for robustness:

Database Replication
We can start with basic replication—distributing data across multiple instances and configuring regular snapshots for backup and recovery.
Vertical vs. Horizontal Scaling
While vertical scaling (upgrading to a larger instance) can be a quick fix, horizontal scaling (adding more instances) is typically preferred for large-scale systems due to the hard limits of vertical growth.
Load Balancers
Relying on a single server for all incoming traffic is not sustainable at scale. Introducing an Application Load Balancer (ALB) helps distribute traffic across multiple instances, improving availability and performance.

Cache
Caching is essential to reduce load on databases and improve response times. AWS services like ElastiCache (Redis/Memcached) can be used to cache expensive queries or frequently accessed data. Additionally, caching can be applied at:
- The frontend (e.g., static resources)
- API level (API Gateway Caching)
I typically use cache for non-volatile content, but care must be taken to prevent serving stale data.
Content Delivery Network (CDN)
To optimize performance for global users, a CDN like CloudFront can serve content from edge locations closest to the user.
One caveat: caching introduces complexity, such as stale content. Fortunately, CloudFront allows explicit cache invalidation—whether by resource path (e.g., /resources/*) or individual files.
Configurations
Use AWS Systems Manager Parameter Store to externalize configurations. For example, by storing your configuration data in an external service like Parameter Store, you can easily launch new servers that retrieve and use the same configurations—making it simple to replicate environments and scale consistently.
Stateless Architecture
Stateless applications make scaling easier. Each instance can serve requests independently, so if one fails, another can take over seamlessly. In contrast, stateful applications (like the initial monolith) create dependencies that hinder fault tolerance and scaling.
Event-Driven Architecture
To improve decoupling and resilience, I prefer asynchronous communication using messaging systems:
- SQS for point-to-point queues SQS Developer Guide
- SNS for publish-subscribe scenarios SNS Developer Guide
This allows components to recover gracefully if others are temporarily unavailable—avoiding ripple effects that can crash the system.
Observability
A scalable system must be observable. AWS Lambda provides this by default with:
- Logging
- Metrics
- Tracing
These capabilities enable you to monitor system health, debug issues, and make informed scaling decisions. Metrics can also feed into Auto Scaling Group (ASG) policies.
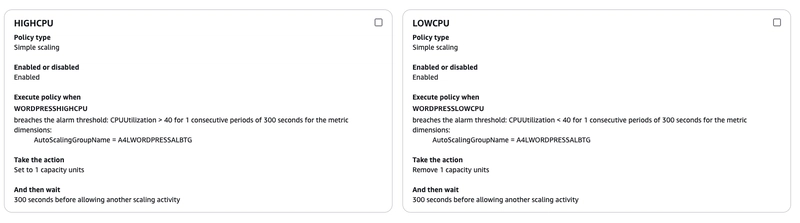
Auto Scaling
With observability in place, the next step is implementing Auto Scaling—defining policies that trigger scale-out or scale-in actions. These policies can be based on:
- CPU usage
- Memory pressure
- Network traffic
- Time-based patterns (e.g., predictable peak hours)
Conclusion
Building a highly scalable and resilient application in AWS is challenging but achievable. You can start with a simple, monolithic architecture and progressively evolve it to handle millions of users.
Along the way, keep these resilience patterns in mind:
- Minimize integration points
- Prevent cascading failures
- Avoid blocked threads and slow responses
- Implement timeouts and circuit breakers
- Use bulkheads to isolate failures
- Embrace the Fail Fast principle: detect and handle errors early
There has never been a better time to be an engineer and create value in society through software.
If you enjoyed the articles, visit my blog at jorgetovar.dev.



